
Wprowadzenie
Dzięki poprzedniej lekcji z maszynowej analizy haseł Wikipedii poznaliśmy pakiet WikipediR. Spróbujmy skorzystać z jego możliwości, tym razem po to, aby pobrać dane, które następnie przetworzymy za pomocą kwerend języka XPath.
Cele lekcji
W tej lekcji wykorzystamy metody pakietu WikipediR, aby pobrać treści wybranych haseł i zanalizować je za pomocą zapytań XPath. W naszym projekcie połączymy więc korzystanie z API z podstawami web scrapingu.
Efekty
Efektem lekcji będą dane na temat liczby niepowtarzalnych plików graficznych, umieszczonych w treści wybranych haseł Wikipedii. Zadanie takie może być częścią analizy jakości haseł.
Wymagania
Tak jak poprzednio, będziemy pracować w języku R na platformie Posit.cloud, która pozwala na uruchomienie środowiska programistyczego bezpośrednio w przeglądarce (konieczne jest założenie darmowego konta). Skorzystamy z bibliotek WikipediR oraz xml2, której metody używaliśmy już przy lekcji ze scrapowania danych o polskich filmach.
Pamiętajmy, że maszynowy dostęp do haseł Wikipedii jest łatwy dzięki temu, że platforma ta wystawia odpowiednie publiczne API.
Część merytoryczna
Wikipedia to nie tylko treści haseł, ale też ich kategoryzowanie. Spójrzmy na kategorię Muzea według typu w Polsce:
Znajdziemy tu odnośniki do podkategorii, z których pozyskać możemy gotowe listy haseł. Oczywiście, należy założyć, że lista muzeów publikowana na Wikipedii nie będzie pełna, ale jeśli interesuje nas podejście statystyczne, lepiej skorzystać z oficjalnych danych publicznych. W podobny sposób analizować możemy tematy kulturowe, pozyskując listy pisarzy i pisarek czy informacje o filmach o malarzach i malarkach. Dobrym (ale również ograniczonym) źródłem danych są też kwerendy w Wikidanych oraz zbiory udostępniane bezpośrednio przez instytucje.
W naszym ćwiczeniu skorzystamy z haseł, zgrupowanych w kategorii Muzea historyczne w Polsce.
Pozyskiwanie tytułów stron z kategorii
W kategorii Muzea historyczne w Polsce zebrano 80 stron (haseł), opisujących poszczególne muzea. Czy jest tak, że - aby pobrać informacje o tych hasłach i ich treści - musimy ręcznie skopiować tytuły poszczególnych stron, aby wysłać je do funkcji page_info? Oczywiście, że nie 😎 - skorzystajmy z gotowych rozwiązań, jakie udostępnia biblioteka WikipediR.
Przechodzimy do Posit.cloud, zakładamy projekt. Zaczynamy oczywiście od instalacji biblioteki i wczytania jej do środowiska:
install.packages("WikipediR")
library(WikipediR)WikipediR udostępnia funkcję pages_in_category:
pages_in_category(
language = NULL,
project = NULL,
domain = NULL,
categories,
properties = c("title", "ids", "sortkey", "sortkeyprefix", "type", "timestamp"),
type = c("page", "subcat", "file"),
clean_response = FALSE,
limit = 50,
...
)Zwróćmy uwagę, że parametry przesyłane do funkcji pozwalają nam dostosować kształt kwerendy do własnych potrzeb: poza podaniem podstawowych informacji o projekcie Wikimediów, z którego będziemy korzystać, możemy podać jaki typ elementów kategorii i jakie informacje na jego temat chcemy otrzymać. Nasze zapytanie może wyglądać tak:
museum_pages <- pages_in_category("pl", "wikipedia", categories = "Muzea historyczne w Polsce", properties = "title", limit = 100)Otrzymamy listę categorymembers zagnieżdżoną w liście query, która zawiera (również w postaci list) informacje o tytułach stron:
museum_pages$query$categorymembers[[1]]$title
# [1] "Muzeum Historyczne Inspektoratu Zamojskiego Armii Krajowej w Bondyrzu"
museum_pages$query$categorymembers[[10]]$title
# [1] "Muzeum Historyczne – Pałac w Dukli"Za pomocą indeksu [[1]] czy [[10]] wskazujemy na wybrany element listy categorymembers.
Lista list to skomplikowana i nieprzejrzysta struktura, nas interesują wyłącznie tytuły. Przepuśćmy pozyskane dane przez pętlę, która wyciągnie tytuły i zapisze je do ramki danych:
# tworzymy pustą ramkę danych
historical_museums <- data.frame()
# iterujemy przez elementy listy categorymembers
for(museum_page in museum_pages$query$categorymembers) {
# pozyskujemy tytuł
title <- museum_page$title
# dodajemy wiersz do ramki danych
historical_museums <- rbind(
historical_museums,
list(
page_title = title
)
)
}Nasza ramka ma 80 wierszy, możemy podejrzeć ją także za pomocą funkcji head, która wyświetli pierwsze kilka obserwacji:
head(historical_museums)
# page_title
# 1 Muzeum Historyczne Inspektoratu Zamojskiego Armii Krajowej w Bondyrzu
# 2 Podziemia Będzińskie
# 3 Muzeum Historyczne w Białymstoku
# 4 Muzeum Pamięci Sybiru
# 5 Muzeum Ceramiki w Bolesławcu
# 6 Muzeum i Gród Średniowieczny w BrzeźnikuMożemy też łatwo zobaczyć zawartość całej kolumny:
historical_museums$page_title
# [1] "Muzeum Historyczne Inspektoratu Zamojskiego Armii Krajowej w Bondyrzu"
# [2] "Podziemia Będzińskie"
# [3] "Muzeum Historyczne w Białymstoku"
# [4] "Muzeum Pamięci Sybiru"
# [5] "Muzeum Ceramiki w Bolesławcu"
# [6] "Muzeum i Gród Średniowieczny w Brzeźniku"
# [7] "Centrum Dialogu „Przełomy”"
# [8] "Zagroda Bafiów w Chochołowie"
# [9] "Muzeum Protestantyzmu w Cieszynie"
# [10] "Muzeum Historyczne – Pałac w Dukli"
...Mamy tytuły stron (haseł) - czas pozyskać i przetworzyć ich treści.
Pozyskiwanie treści hasła
Skorzystamy tym razem z funkcji page_content.
page_content(
language = NULL,
project = NULL,
domain = NULL,
page_name,
page_id = NULL,
as_wikitext = FALSE,
clean_response = FALSE,
...
)Większość parametrów tej funkcji wydaje się oczywista, zwróćmy uwagę na parametr as_wikitext. Wikitext to, podobnie jak Markdown, język znaczników, który ma ułatwiać kodowanie treści do struktury HTML. Ponieważ chcemy wykonywać kwerendy XPath na strukturze HTML stron Wikipedii, treści w postaci Wikitekstu nie będą nam potrzebne.
Spróbujmy przetestować funkcję page_content na jednej ze stron. Poniższy kod pozyska treść dla strony, której tytuł zapisany jest w dziesiątym wierszu naszej ramki danych. Indeks [10,1] wskazuje na dziesiąty wiersz i pierwszą kolumnę - poruszamy się przecież w przestrzeni dwuwymiarowej tabeli:
test_content <- page_content("pl","wikipedia", page_name = historical_museums[10,1])Znów mamy do czynienia ze skomplikowanym zestawem list:
test_content
# $parse
# $parse$title
# [1] "Muzeum Historyczne – Pałac w Dukli"
#$parse$pageid
# [1] 1714321
# $parse$revid
# [1] 74065930
# $parse$text
# $parse$text$`*`
# [1] "<div class=\"mw-content-ltr mw-parser-output\" lang=\"pl\" dir=\"ltr\"><table class=\"infobox\">\n<caption class=\"naglowek\" style=\"background-color:LightBlue; color:#000000;\"><style data-mw-deduplicate=\"TemplateStyles:r65781301\">.mw-parser-output .infobox>caption>.iboxt-flex#{display:flex;justify-content:flex-start;align-items:center;gap:4px}.mw-parser-output .infobox>caption>.iboxt-flex>.iboxt-ikona{flex-grow:0;flex-shrink:0;font-size:7px;max-width:40px;overflow:hidden}.mw-parser-output .infobox>caption>.iboxt-flex>.iboxt-tekst{flex-grow:1}.mw-parser-output .infobox>caption .iboxt-1{font-weight:bold}.mw-parser-output .infobox>caption .iboxt-2{font-style:italic}.mw-parser-output .infobox>caption .iboxt-3{font-style:italic;font-size:90%}</style><div class=\"iboxt-1\">Muzeum Historyczne – Pałac w Dukli</div>\n</caption>\n<tbody><tr class=\"grafika iboxs\">\n<td colspan=\"2\"><span typeof=\"mw:File\"><a href=\"/wiki/Plik:Dukla,
...W elemencie $parse$text znajdziemy interesujące nas treści - kod źródłowy merytorycznej części strony hasła “Muzeum Historyczne – Pałac w Dukli” z Wikipedii. To ważne, żeby analizować nie całą stronę (z elementami nawigacji, banerami, ozdobami), ale wyłącznie treść opisującą muzeum.
Pozyskana treść to skomplikowany, ale jednak HTML z dodanym stylowaniem. A skoro to HTML, możemy parsować go za pomocą języka XPath.
Przetwarzanie treści hasła (testy)
Eksperymentujmy wciąż z treścią pojedynczego hasła - kiedy przetestujemy metodę pracy z nią, uruchomimy odpowiednią pętlę i przetworzymy wszystkie 80 stron.
Naszym celem jest zliczenie unikalnych grafik (obrazków), publikowanych w treści każdego hasła. Oto kod, za pomocą którego na stronie hasła o Muzeum Historycznym - Pałacu w Dukli umieszczono fotografię, przedstawiającą wnętrza muzeum:
<img
alt="Wygląd wystawy poświęconej historii Dukli i pałacu"
src="//upload.wikimedia.org/wikipedia/commons/thumb/7/7c/Dukla_-_muzeum_35.JPG/200px-Dukla_-_muzeum_35.JPG"
decoding="async"
width="200"
height="150"
class="mw-file-element"
srcset="
//upload.wikimedia.org/wikipedia/commons/thumb/7/7c/Dukla_-_muzeum_35.JPG/300px-Dukla_-_muzeum_35.JPG 1.5x,
//upload.wikimedia.org/wikipedia/commons/thumb/7/7c/Dukla_-_muzeum_35.JPG/400px-Dukla_-_muzeum_35.JPG 2x
"
data-file-width="3264"
data-file-height="2448"
/>Kwerenda XPath, która pozwoli nam znaleźć ścieżki do plików obrazków, wygląda tak:
//img/@srcEfektem takiej kwerendy będą wartości atrybutu src każdego elementu img, niezależnie od jego miejsca w strukturze strony. W razie potrzeby możemy też pozyskać podpis - wartość atrybutu alt:
//img/@altAby użyć XPath na treści hasła, pozyskanej przez jedną z metod WikipediR, potrzebujemy dodatkowego pakietu: xml2 (używaliśmy go już do budowy scrapera w jednej z poprzednich lekcji):
install.packages("xml2")
library(xml2)Mamy dostęp do treści strony, która jest zwykłym ciągiem tekstowym. Aby wykonać kwerendę XPath, musimy ten ciąg tekstowy zamienić na zestaw elementów (węzłów) - typ html_document. Dopiero z kodem w takiej postaci możemy pracować metodami xml2:
test_content_html <- read_html(test_content$parse$text[[1]])
test_content_html
# {html_document}
# <html>
# [1] <body><div class="mw-content-ltr mw-parser-output" lang="pl" dir="ltr">\n<table class="infobox">\n<caption class="nag ...Pozostaje nam wysłać kwerendę XPath:
# wysyłamy kwerendę xpath funkcją xml_find_all
test_images <- xml_find_all(test_content_html, '//img/@src')
# podglądamy pozyskane węzły
test_images
# {xml_nodeset (46)}
# [1] src="//upload.wikimedia.org/wikipedia/commons/thumb/5/54/Dukla%2C_zesp%C3%B3%C5%82_pa%C5%82acowy_%28HB1%29.jpg/240p ...
# [2] src="//upload.wikimedia.org/wikipedia/commons/thumb/1/12/Flag_of_Poland.svg/22px-Flag_of_Poland.svg.png"
# [3] src="//upload.wikimedia.org/wikipedia/commons/thumb/9/94/POL_wojew%C3%B3dztwo_podkarpackie_flag.svg/22px-POL_wojew% ...
# [4] src="//upload.wikimedia.org/wikipedia/commons/thumb/8/80/Dukla_location_map.png/238px-Dukla_location_map.png"Niektóre obrazki na stronie hasła mogą być publikowane wielokrotnie - aby tego uniknąć, zachowajmy tylko unikalne wartości ścieżek. Aby użyć funkcji unique, musimy zestaw węzłów zamienić na wieloelementowy wektor:
test_count_images <- length(unique(unlist(as_list(test_images))))
test_count_images
# [1] 29Funkcją length zliczamy liczbę elementów takiego wektora. To dane, na których nam zależy w analizie. Spróbujmy tę metodę pozyskiwania danych o liczbie obrazków umieścić w pętli, aby wykonać ją dla wszystkich 80 stron opisujących polskie muzea historyczne.
Przetwarzanie stron w pętli
W ramce danych historical_museums mamy kolumnę page_title - nasza pętla powinna przejść przez wszystkie wiersze w tej kolumnie i wysłać ich wartość do funkcji page_content, a następnie odpowiednio przetworzyć odpowiedź.
Spróbujmy użyć pętli w takiej postaci i pracujmy z nową, pustą ramką danych:
historical_museum_images <- data.frame()
for (museum_title in historical_museums$page_title) {
# pobieranie treści strony
museum_page_content <- page_content("pl", "wikipedia", page_name = museum_title)
# przetwarzenie ją na dokument html
museum_page_content_html <- read_html(museum_page_content$parse$text[[1]])
# wysyłanie kwerendy XPath
museum_page_content_images <- xml_find_all(museum_page_content_html, '//img/@src')
# zliczanie unikalnych wartości ścieżek do obrazków
museum_page_content_images_count <- length(unique(unlist(as_list(
museum_page_content_images
))))
# dodawanie danych do ramki historical_museum_images
historical_museum_images <- rbind(
historical_museum_images,
# dodajemy dane do dwóch kolumn - page_title i images_count
list(page_title = museum_title, images_count = museum_page_content_images_count)
)
}Oczywiście tę pętlę można byłoby napisać z mniejszą liczbą tworzonych, tymczasowych wektorów (zmiennych), ale taka postać jest bardziej czytelna i lepiej sprawdzi się w celach edukacyjnych. Efektem naszej pracy jest taki zestaw danych:
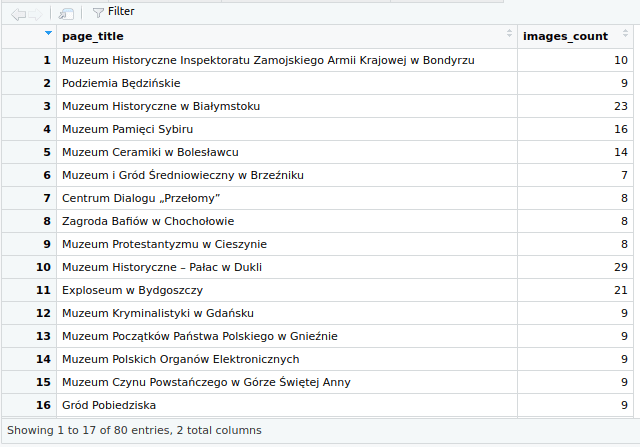
Modyfikując kwerendę XPath i odpowiednio przetwarzając jej wyniki możemy analizować inne elementy treści hasła w Wikipedii, np. liczbę cytatów umieszczonych na stronie i informacje o ich autorach, linki wewnętrzne i zewnętrzne (chociaż jest do tego dedykowana funkcja), liczbę i teksty przypisów czy nawet wspomniane w tekście daty.
Ramkę danych historical_museum_images wyeksportować możemy do pliku CSV:
write.csv(historical_museum_images, "historical_museum_images.csv", row.names = FALSE)Podsumowanie
Maszynowy dostęp do treści haseł Wikipedii pozwala nam planować zaawansowane i szeroko zakrojone analizy czy budować narzędzia do obserwowania zmian. W przypadku badań, w których źródłem miałyby być bardzo duże liczby haseł, a nawet całe wersje językowe Wikipedii, lepiej skorzystać z kopii treści w postaci zrzutów danych (data dumps), regularnie udostępnianych przez Wikimedia.
WikipediR ułatwia nam pracę z API Wikipedii i siostrzanych projektów, a korzystając z innych bibliotek R możemy je dalej przetwarzać i analizować. Dzięki R możemy zbudować własne narzędzia analityczne, dostosowane do potrzeb naszych badań, łączące w sobie wiele różnych metod, choćby - tak jak w tej lekcji - dostęp API i scrapowanie danych za pomocą XPath.
Wykorzystanie metod
Przykładem wykorzystania pakietu WikipediR w badaniach jest artykuł The memory remains: Understanding collective memory in the digital age (2017). W badaniu pozyskano i analizowano 1606 haseł anglojęzycznej Wikipedii, poświęconych katastrofom lotniczym. Zebrano także statystyki ich oglądalności. Zaproponowano model matematyczny, który miał wyjaśniać przepływy oglądalności z haseł poświęconych bieżącym wypadkom lotniczym na hasła opisujące takie wydarzenia z przeszłości.
Innym interesującym badaniem, zrealizowanym z użyciem WikipediR, jest próba oceny jakości cytowań w hasłach Wikipedii poświęconych pandemii COVID-19.
Pomysł na warsztat
Lekcja jest gotowym komponentem do warsztatów z podstaw R i web scrapingu.
Podczas warsztatu z analiz jakości haseł Wikipedii (który można przeprowadzić bez konieczności programowania) skorzystać można z wydanej przez Fundację Wikimedia broszury Evaluating Wikipedia: Tracing the evolution and evaluating the quality of articles (2010).


