
Wprowadzenie
W 1997 roku swoje witryny internetowe miało już m.in. Muzeum Sztuki w Łodzi, Centrum Sztuki Współczesnej w Warszawie, Muzeum Pałac w Wilanowie, Galeria Zachęta, Muzeum Narodowe w Warszawie i Ośrodek KARTA. Czy można dotrzeć do treści tych witryn sprzed dekad?
Cele lekcji
Celem lekcji jest zdobycie praktycznych umiejętności w zakresie korzystania z Wayback Machine, prowadzonego przez fundację Internet Archive otwartego archiwum WWW (Webu). Uwaga: treść lekcji nie obejmuje metod i narzędzi archiwizacji stron internetowych - będziemy pracować wyłącznie z zasobami już zarchiwizowanymi. Osoby, które chciałyby poznać metody masowej archiwizacji stron WWW, zapraszam do kontaktu z Pracownią Archiwistyki Webu CKC UW.
Efekty
Efektem lekcji będzie umiejętność wyszukiwania i korzystania z archiwalnych wersji stron WWW, dostępnych w zbiorach Wayback Machine. Poznamy też podstawowe pojęcia i standardy wykorzystywane w rozwijającej się już od połowy lat 90. archiwistyce Webu.
Wymagania
Do skorzystania z lekcji wystarczy przeglądarka. Będziemy korzystać z portalu Wayback Machine. Nie będziemy programować.
Część merytoryczna
Często słyszy się, że w internecie nic nie ginie i że internet pamięta. Być może jest tak, kiedy patrzymy z bliskiej perspektywy - wciąż możemy odnaleźć własne wpisy w mediach społecznościowych, od dekad dostępna jest Wikipedia i popularne portale. Jednak kiedy spojrzymy szerzej na zasoby sieci World Wide Web (części internetu dostępnej przez przeglądarkę), zobaczymy, że w żadnym wypadku nie są one stabilne.
Link rot i content drift
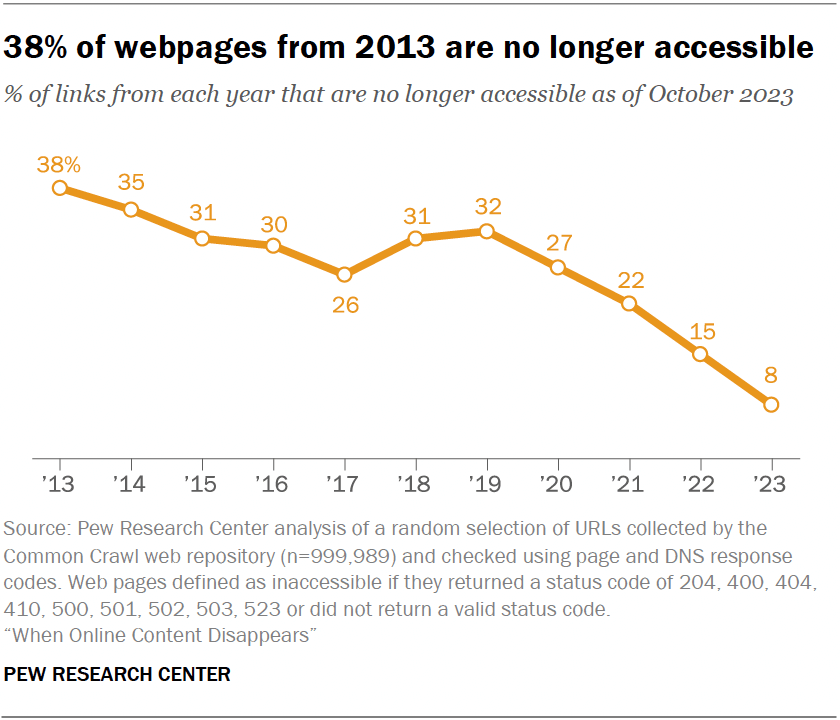
W maju 2024 roku opublikowano kolejne badanie zjawiska link rot, tym razem obejmujące prawie 1 mln stron (adresów URL), publikowanych w latach 2013-2023:
Gnicie czy dezakutalizacja linków (link rot) to zjawisko polegające na tym, że adresy URL do stron internetowych i innych obiektów online przestają działać. Ma to swoje konsekwencje np. w komunikacji naukowej. W przypisie pracy naukowej znajduje się odnośnik do strony - po kliknięciu w niego oczekujemy, że przejdziemy do cytowanej treści. Niestety, podany w przypsiei link nie wyświetla już żadnej strony albo pokazuje inną niż oczekiwana treść.
Jeśli w takiej sytuacji otrzymujemy treść, która różni się od pierwotnie linkowanej treści, mówimy o zjawisku dryfu treści (content drift). Nie zawsze jesteśmy w stanie dostrzec, że oryginalna treść została zmieniona. Problem link rot i content drift nie dotyczy tylko stron WWW, ale wszystkich obiektów, które mogą być udostępniane w sieci WWW: plików PDF, multimediów, streamingu, map itp.
Analiza instytutu Pew Internet polegała na sprawdzeniu dostępności adresów z wybranych lat - jak widać na wykresie, 38 proc. zidentyfikowanych stron WWW przestało być dostępnych w ciągu dekady. Jeśli zwrócimy uwagę na ostatnie lata (2020-2023), to skala tej niedostępności też nie jest mała - sięga nawet 1/3!
Dlaczego strony przestają być dostępne? Przyczyn może być wiele, ale wśród przyczyn jest na pewno:
- świadome działanie zmierzające do usunięcia niektórych treści,
- aktualizacja systemu zarządzania treścią witryny, która powoduje, że zmienia się struktura odnośników,
- nieopłacenie domeny / hostingu, skutkujące brakiem dostępu do witryny,
- ograniczenie dostępu do treści za paywallem, rejestracją lub innymi metodami autoryzacji użytkowników,
- filtrowanie treści przez dostawców usług internetowych w wyniku cenzury, blokad regionalnych lub innych ograniczeń,
- awarie serwera lub przypadkowe usunięcie plików z hostingu.
Musimy pamiętać, że sieć WWW sama w sobie nie została wyposażona w żadne techniczne rozwiązania, pozwalające na samoarchiwizację publikowanych w niej zasobów. Oznacza to, że historyczne wersje witryn interesujących nas instytucji kultury mogły nie być zabezpieczone i mogą być dziś niedostępne. Jeśli same instytucje nie zadbały o ich archiwizację, możemy spróbować poszukać ich śladów w Wayback Machine i innych archiwach Webu.
Archiwistyka Webu
Próbą przeciwdziałania niestabilności zasobów sieci WWW jest archiwistyka Webu:
Archiwizacja Webu to proces gromadzenia części zasobów World Wide Web (WWW) w celu zachowania ich dla przyszłych badaczy, historyków i opinii publicznej. Sama sieć WWW i wykorzystywany do komunikacji w niej protokół HTTP nie posiadają mechanizmów samoarchiwizowania przesyłanych zasobów, dlatego ważne jest istnienie inicjatyw i instytucji, które selekcjonują, archiwizują i udostępniają archiwalne zbiory witryn internetowych. Metody archiwizacji Webu oraz same archiwalne zbiory WWW mogą być wykorzystywane w badaniach naukowych, pracy dziennikarskiej, działalności organizacji pozarządowych i twórczości artystycznej. Archiwa Webu pozwalają również na utrzymanie ważności linków umieszczanych w przypisach do prac naukowych oraz wyrokach sądowych i ich uzasadnieniach.
W Polsce używamy pojęcia archiwistyka Webu zamiast archiwistyka internetu, ponieważ jest ono lepszym odpowiednikiem angielskiego web archiving - w działaniach archiwalnych tego typu pracuje się z zasobami sieci WWW a nie całego internetu (np. poczty elektronicznej czy zasobów przechowywanych na serwerach FTP). Pamiętajmy, że to, co widzimy w przeglądarce, wcale nie jest całym internetem.
Witryny i obiekty webowe od połowy lat 90. archiwizuje fundacja Internet Archive oraz biblioteki i archiwa narodowe w wielu krajach na świecie. W Polsce próby archiwizowania polskiej domeny krajowej miały miejsce w latach 2009-2011 - w naszym kraju nie ma obecnie archiwum Webu (poza oddolną inicjatywą Archiwum Społecznego Polskiego Webu). Na szczęście korzystać możemy z Wayback Machine, otwartego archiwum pozwalającego na samodzielne archiwizowanie treści online i przeglądanie historycznych zasobów Webu.
Więcej na temat archiwistyki Webu dowiedzieć się można z opracowania Web archives as a data resource for digital scholars (2019) oraz podczas webinariów organizowanych w Pracowni Archiwistyki Webu CKC UW.
Interpretacje a nie kopie
Chociaż niektóre archiwa Webu są częścią zamkniętej infrastruktury naukowej, z innych możemy korzystać swobodnie, samodzielnie przeglądając, a nawet archiwizując wybrane zasoby. Takim archiwum jest Wayback Machine.
Wayback Machine powstało w 1996 roku i od tego czasu gromadzi archiwalne kopie witryn i innych obiektów WWW. Słowo kopia nie oddaje przy tym specyfiki obiektu, który tworzy się w akcie archiwizacji strony. W teorii archiwistyki Webu podkreśla się, że z różnych technicznych względów nie można w dokładny sposób powielić dostępnej online strony internetowej - wyciągnięcie jej z przestrzeni live Web ma poważne konsekwencje. Możemy zresztą przekonać się o tym sami, zapisując na dysku dowolną stronę wyświetlaną w przeglądarce za pomocą opcji Zapisz stronę jako…. Tak zapisana kopia może nie posiadać wszystkich oryginalnych elementów (np. obrazków), jej mechanizmy (widżety, wyszukiwarki itp.) mogą nie działać, a linki być bezużyteczne.
W archiwistyce Webu podkreśla się, że strona czy jakikolwiek inny obiekt, zabezpieczony w archiwum Webu, to szczególna interpretacja archiwalna. W literaturze naukowej zamiast kopii używa się takich pojęć jak migawka (snapshot) czy memento. Snapshot czy memento zawsze identyfikowany jest przynajmniej dwoma elementami: adresem URL oryginalnego zasobu, dostępnego online, oraz oznaczeniem czasu (timestamp).
Przeglądanie stron w Wayback Machine
Wejdźmy na stronę Wayback Machine i wpiszmy do formularza wyszukiwania adres Muzeum Sztuki w Łodzi:
http://www.sunsite.icm.edu.pl:80/ddg/msl/Dlaczego taki adres? Chcemy dotrzeć do witryny MS z 1997 roku, a w tym czasie dostępna była ona na serwerach ICM UW. Skąd to wiemy? Mamy dostęp do strony domowej serwera Sun SITE ICM z maja 1997 roku, na której publikowane są odnośniki m.in. do Muzeum Sztuki.
Podstawą pracy z Wayback Machine jest znajomość adresów interesujących nas stron i witryn. Wyszukiwarka Wayback Machine przeszukuje tylko strony główne witryn, więc wyszukiwanie za pomocą słów kluczowych może nie być efektywne. Ale skąd brać archiwalne wersje adresów witryn?
Dobrym rozwiązaniem jest sięgnięcie po drukowane przewodniki po internecie, wydawane jeszcze w pierwszych latach XXI wieku. Czasem archiwalne wersje adresów znaleźć można też w prasie drukowanej, w katalogach online lub jako odnośniki na innych stronach.
Po wpisaniu adresu do okna wyszukiwania Wayback Machine, wyświetla nam się strona z kalendarzem archiwizacji - kolorem niebieskim oznaczone są dni, w których robot Wayback Machine wszedł na interesujący nas adres i poprawnie wykonał jego kopię (interpretację).
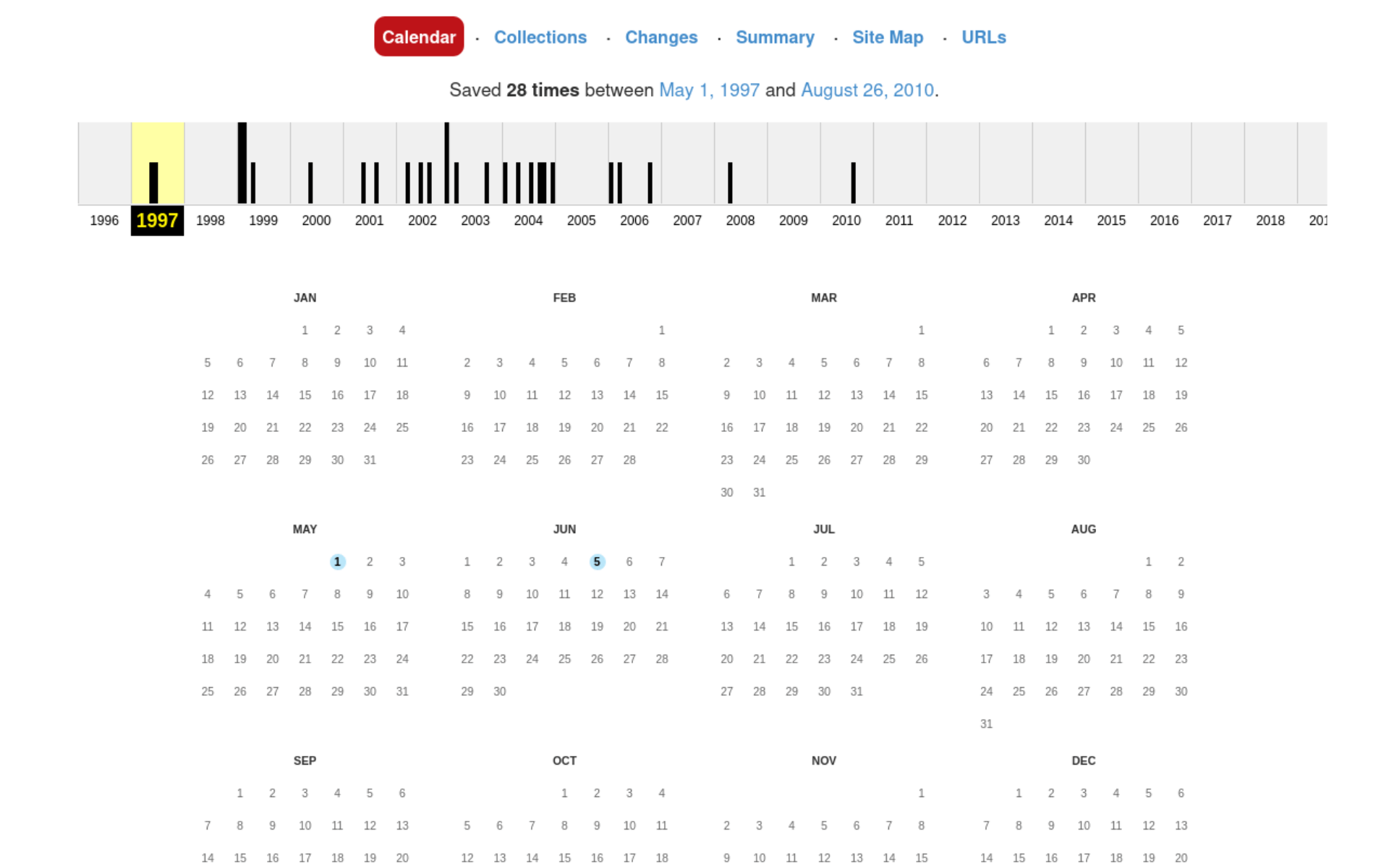
Wayback Machine archiwizuje nie tyle strony WWW czy inne obiekty dostępne online, takie jak pliki PDF, pliki graficzne czy multimedia, ale odpowiedzi serwerów - niektóre z nich mogą być błędne. Jeśli robot Wayback Machine w czasie wejścia na żądany adres nie otrzyma poprawnej treści, zapisze informację o błędzie lub przekierowaniu, która na kalendarzu archiwizacji zostanie oznaczona innym kolorem.
W 1997 roku wszystkie dwie archiwizacje strony głównej witryny Muzeum Sztuki w Łodzi były poprawne. Kliknijmy w archiwizację z 1 maja:
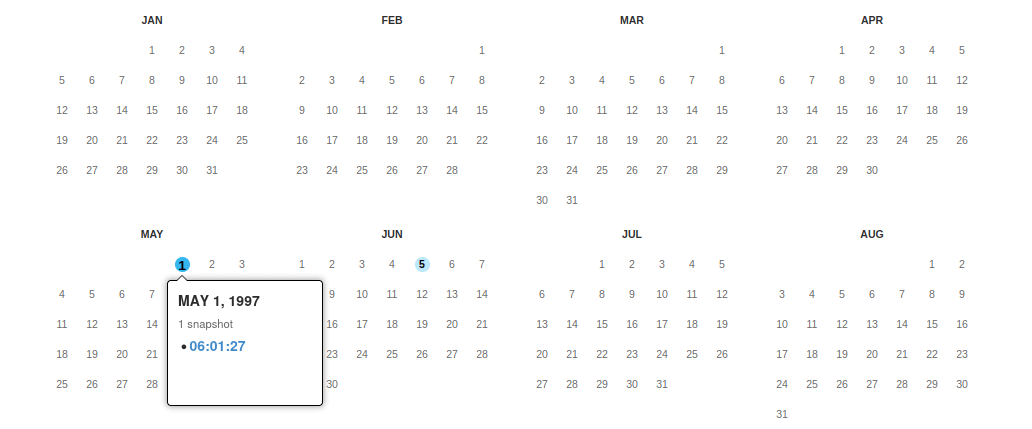
Jednego dnia dany adres może być archiwizowany wielokrotnie - w naszym przypadku mamy dostęp tylko do jednego snapshotu (memento) - z godz. 6 rano. Jeśli klikniemy w udostępniony link, przejdziemy na stronę kopii archiwalnej, dostępnej pod adresem:
https://web.archive.org/web/19970501060127/http://www.sunsite.icm.edu.pl:80/ddg/msl/Możemy wyróżnić trzy elementy składowe tego adresu:
- adres portalu Wayback Machine - https://web.archive.org/web/,
- znacznik czasu archiwizacji (timestamp) - 19970501060127 (1997-05-01 06:01:27),
- oryginalny URL strony - http://www.sunsite.icm.edu.pl:80/ddg/msl/.
Te trzy elementy adresu kopii archiwalnej wskazują na części systemu archiwum Webu: portalu, pozwalającego na rekonstrukcję wyglądu i zachowania strony z jej kopii archiwalnej, oznaczenia czasowego kopii oraz identyfikującego ją oryginalnego adresu.
Dzięki tym trzem elementom możemy zapoznać się z wyglądem i treścią strony, która nie jest już dostępna online - to właśnie snapshot (memento):
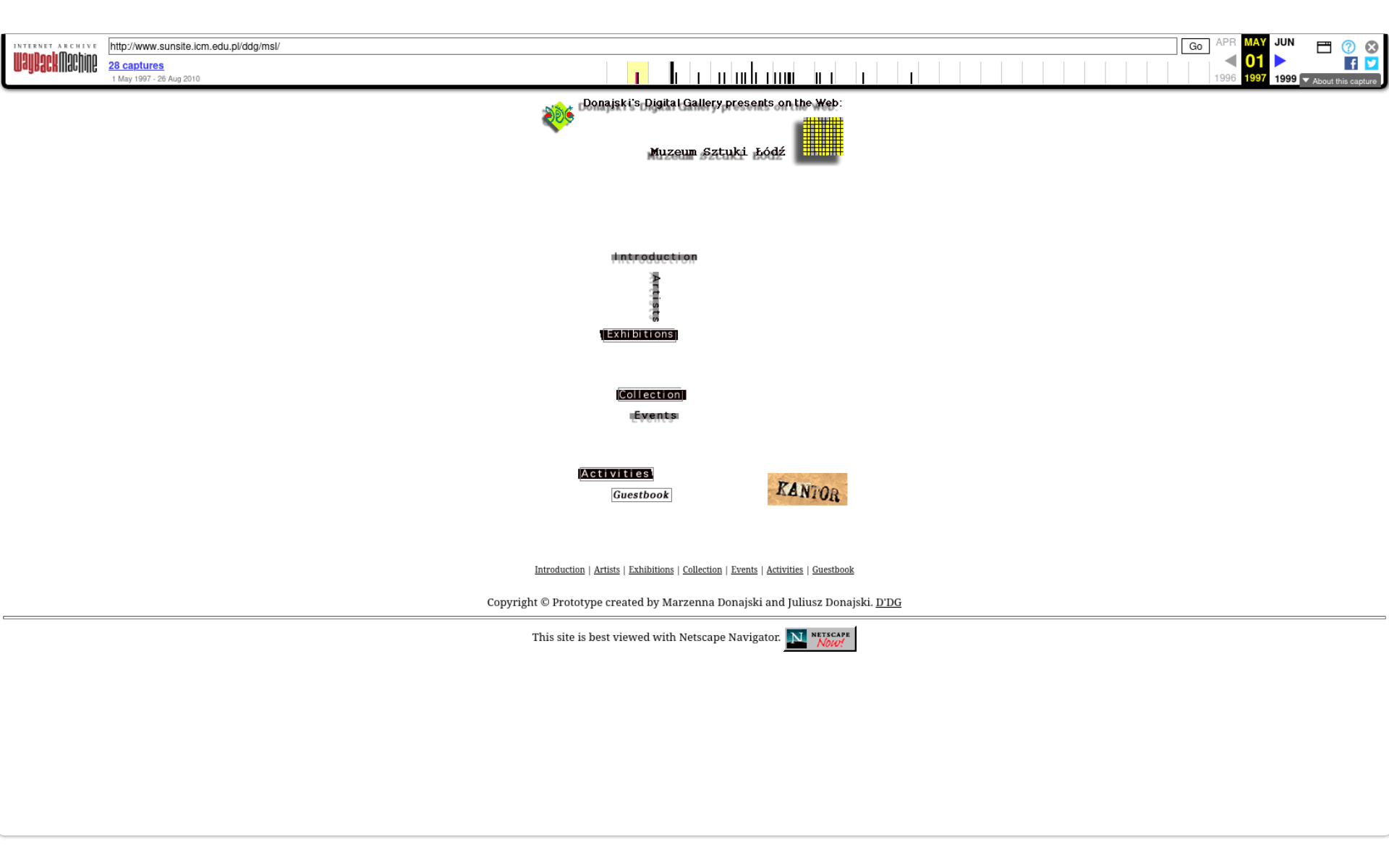
Zwróćmy uwagę, że strona jest aktywna - możemy kilkać w linki, zobaczyć jej źródło HTML itd. - jedną z naczelnych zasad archiwistyki Webu jest takie udostępnianie archiwalnych stron, żeby ich przeglądanie jak najbardziej przypominało codzienne korzystanie ze współczesnych stron.
W literaturze przedmiotu wskazuje się, że archiwalne kopie (interpretacje) stron i innych obiektów WWW są odtwarzane (replaying) z paczek archiwalnych, którymi są zazwyczaj pliki WARC (Web ARChive). To zgodny ze standardem ISO 28500:2017 format archiwizowania treści online.
Ponowne wykorzystanie zarchiwizowanych elementów
Wayback Machine, archiwizując każdy obiekt, generuje dla niego identyfikator treści (hash), co pozwala uniknąć ponownego archiwizowania, jeśli obiekt nie zmienił się od czasu ostatniej archiwizacji. Doskonale widać to przy okazji memento strony głównej Muzeum Sztuki w Łodzi, wygenerowanego 5 czerwca 1997 roku, a więc miesiąc po pierwszej archiwizacji. Nie wiemy, dlaczego ta strona została akurat wtedy zarchiwizowana, możemy jednak zobaczyć, skąd pochodzą jej składowe elementy. Wejdźmy na adres
https://web.archive.org/web/19970605212103/http://www.sunsite.icm.edu.pl:80/ddg/msl/i wybierzmy opcję dostępną w prawym górnym rogu - About this capture:
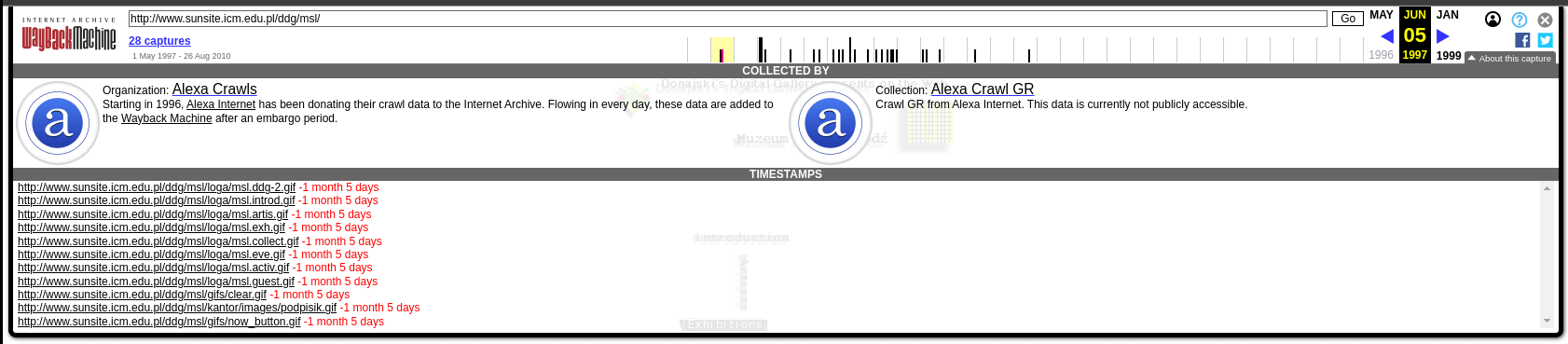
Widzimy, że treść strony (plik HTML) została zarchiwizowana w czerwcu, ale pliki graficzne są starsze od tej treści o miesiąc! W przypadku niektórych kopii w Wayback Machine ten brak integralności czasu archiwizacji wszystkich elementów strony jest jeszcze bardziej widoczny, a różnice liczone są nie w miesiącach, ale latach.
Pamiętajmy też, że moment archiwizacji nie musi wskazywać na dostępność strony: jeśli nasza strona została zarchiwizowana w maju i czerwcu 1997 roku, nie oznacza to, że nie była dostępna wcześniej.
Przekierowania i błędy
Jak widzimy na kalendarzu archiwizacji strony głównej Muzeum Sztuki w Łodzi, w 1998 roku nie została zabezpieczona żadna treść. W 1999 roku mamy dostęp do kilku archiwizacji, ale mają one szczególną postać, na co wskazuje kolor zielony:
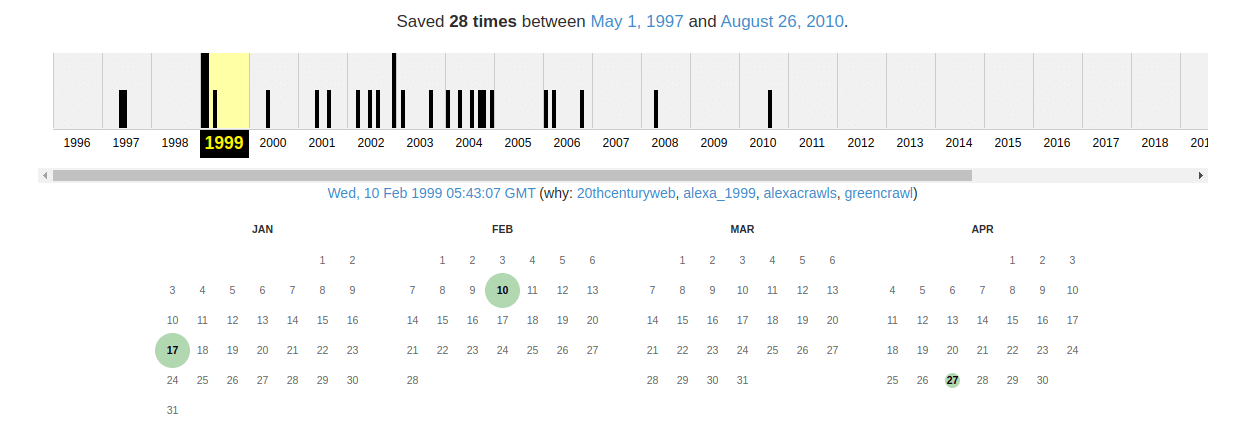
Kolor zielony oznacza przekierowania. Przekierowanie w protokole HTTP, na którym bazuje komunikacja w sieci WWW, to mechanizm, pozwalający serwerowi wskazać klientowi (np. przeglądarce internetowej) nową lokalizację zasobu, który ten próbuje uzyskać. W naszym przypadku chcemy dotrzeć np. do kopii ze stycznia
https://web.archive.org/web/19990117000733/http://www.sunsite.icm.edu.pl/ddg/msl/jednak Wayback Machine zarchiwizował tutaj nie kopię strony, ale odpowiedź serwera i przekierowanie do adresu www.infoseek.icm.edu.pl:

W kolejnych latach kopie pierwotnego adresu Muzeum Sztuki
http://www.sunsite.icm.edu.pl:80/ddg/msl/zwracają już słynny błąd 404 (nie ma takiej strony), a więc możemy uznać, że przynajmniej od początku 1990 roku witryna Muzeum Sztuki jest już dostępna pod innym adresem. Przeniesiono ją z serwera ICM, być może także zmieniono jej kształt.

Ewolucja witryny
Historia witryny Muzeum Sztuki w Łodzi obejmuje trzy adresy:
- www.sunsite.icm.edu.pl:80/ddg/msl przynajmniej od 1997 roku,
- www.muzeumsztuki.lodz.pl przynajmniej od 1999,
- www.msl.org.pl - przynajmniej od 2007 do dziś.
Dostępność strony pod trzema adresami nie musi wcale wskazywać na jej trzy wersje. Przykładowo, wersja muzeumsztuki.lodz.pl z 30 września 2007 z jest zbieżna z wersją msl.org.pl z 1 października 2007 - witryna Muzeum Sztuki funkcjonowała przez jakiś czas pod dwoma adresami.
Wayback Machine udostępnia ciekawe narzędzie, pozwalające automatycznie wykazać zmiany w konstrukcji i treści archiwizowanej strony. Przejdźmy na adres
https://web.archive.org/web/changes/http://www.muzeumsztuki.lodz.pl/żeby sprawdzić, kiedy MS przestało publikować treści z wykorzystaniem adresu muzeumsztuki.lodz.pl.
Wybierając konkretne snapshoty, możemy wygenerować porównania. Przykładowo, oto zestawienie wersji strony muzeumsztuki.lodz.pl z maja 1999 i października 2008:
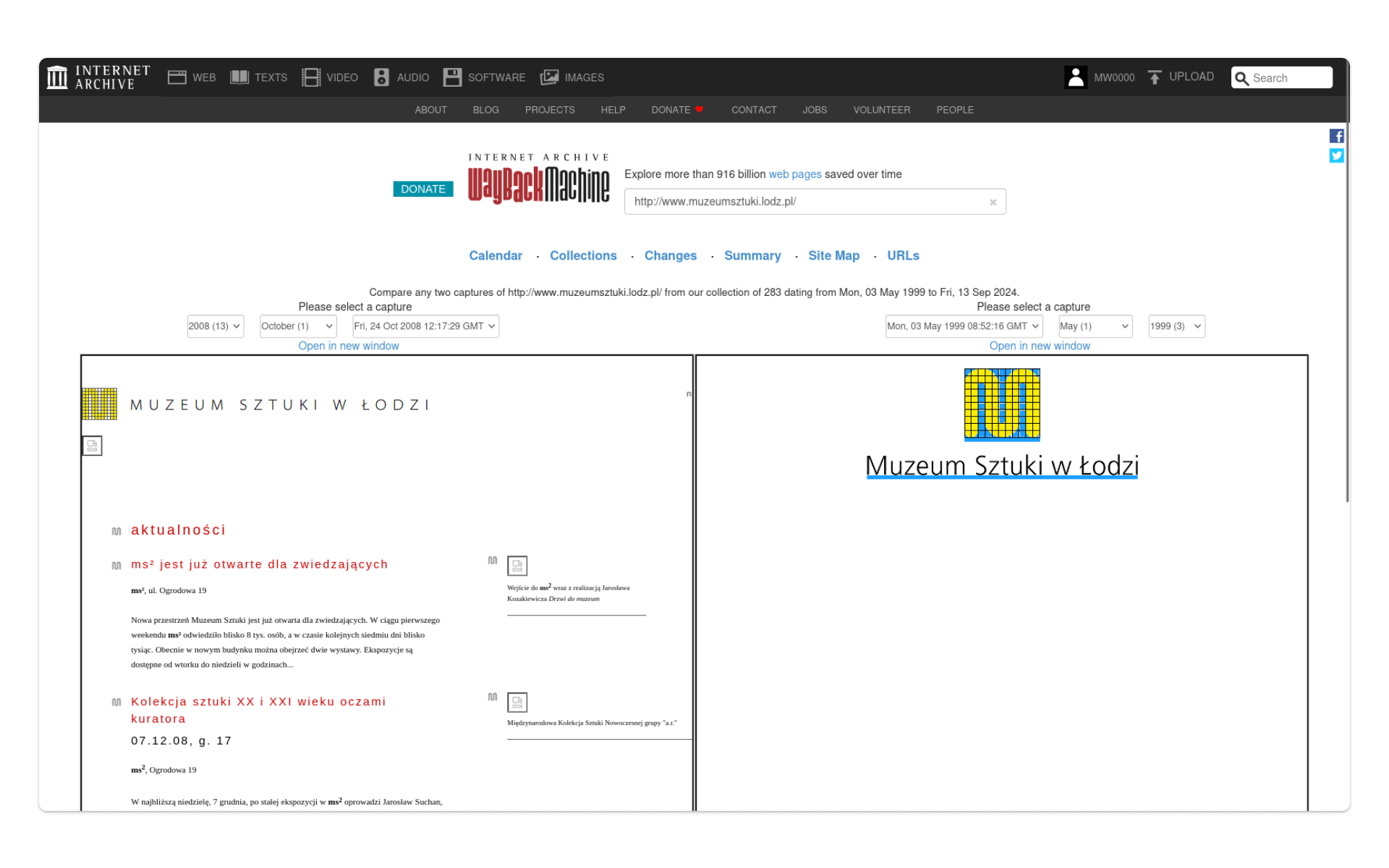
Uważnie analizując kalendarz zmian w treści tej strony, możemy próbować wychwycić moment, w którym adres muzeumsztuki.lodz.pl przestał być wykorzystywany do publikowania strony muzeum:

Porównanie dwóch wersji z 2012 roku pozwala wskazać na moment zmiany:

Ograniczenia w archiwizacji
Archiwizacja stron w Wayback Machine prowadzona jest przede wszystkim przez boty - roboty internetowe, które wchodzą na wybrany adres i poruszają się po odnośnikach, odwiedzając kolejne linkowane strony (crawling). Niestety, czasem boty nie są w stanie odwiedzić wskazanego adresu, np. ze względu na blokady (pliki robots.txt), błędy serwerów czy pułapki.
Nawet jeśli bot wejdzie na żądaną stronę, nie ma pewności, że będzie w stanie poprawnie ją zarchiwizować - dotyczy to zwłaszcza skomplikowanych, dynamicznych stron, w przeszłości także stron tworzonych we Flashu czy dynamicznie generowanych w przeglądarce.
Boty nie zawsze są też w stanie poprawnie pobrać elementy składowych strony, stąd prawdopodobne są błędy w wyświetlaniu niektórych grafik czy skryptów. Pamiętajmy też, że Wayback Machine nie zawsze może zarchiwizować wszystkie zasoby witryny w zbliżonym czasie (pojawia się kwestia integralności czasowej kopii).
Osobnym problemem jest to, na jakiej podstawie wybierane są zasoby do archiwizacji w Wayback Machine. Artykuł The Internet Archive and the socio-technical construction of historical facts (2018), pokazuje, jak bardzo skomplikowany jest ten system archiwalny i jak niekiedy bardzo przypadkowo podejmowane są decyzje o wyborze takich a nie innych adresów do pozyskania.
Podsumowanie
Wayback Machine to ogólnodostępne i łatwe w obsłudze archiwum Webu. Każdy może z niego korzystać, a nawet samodzielnie archiwizować wybrane zasoby WWW. W Polsce, w przeciwieństwie do wielu krajów Europy, nie istnieje państwowe archiwum Webu, dlatego Wayback Machine pozostaje głównym narzędziem umożliwiającym dostęp do historycznych zasobów polskiej domeny krajowej. Niestety, archiwizacja w Wayback Machine nie jest prowadzona regularnie, co ogranicza możliwości i precyzję badania wybranych witryn.
Spis kolekcji archiwalnych zebranych przez luksemburskie archiwum Webu może stanowić dobry przykład tego, jakie istotne społecznie treści tracimy z powodu braku krajowego archiwum tego rodzaju. Wśród gromadzonych tam zbiorów są:
- zasoby WWW dokumentujące pandemię COVID-19,
- treści online związane z kampaniami wyborczymi w wyborach krajowych i europejskich,
- archiwa aktualności z krajowych portali informacyjnych,
- blogi,
- wpisy z Twittera (X),
- witryny instytucji kultury,
- inne zbiory webowe z domeny .lu.
Wykorzystanie metod
Archiwa Webu wykorzystywane są nie tylko w badaniach ewolucji witryn. Ich zasoby mogą być używane jako dowody w sprawach sądowych, dokumentować ważne bieżące wydarzenia czy nawet gromadzić kolekcje sztuki cyfrowej.
Jednym z większych archiwów Webu, działającym jednak na nieco innych niż Wayback Machine zasadach, jest Common Crawl. Gromadzone przez niego zasoby stanowią dziś podstawę trenowania wielu modeli języka naturalnego:
Common Crawl to największy publicznie dostępny zbiór zasobów sieciowych (web crawl data) i jedno z najważniejszych źródeł danych do wstępnego trenowania dużych modeli językowych (LLM). Jest używany tak często i stanowi tak dużą część danych treningowych, że można go uznać za podstawowy element rozwoju LLM, a w konsekwencji także produktów generatywnej sztucznej inteligencji opartych na LLM.
Pomysł na warsztat
Dobrym wstępem do poznania zasad działania Wayback Machine i samej koncepcji archiwistyki Webu może być praca z zasobami projektu GifCities - to wyszukiwarka animowanych gifów z lat 90. i 00., stworzona dzięki możliwościom, jakie daje format WARC. Dostępnych jest tam ponad 1.6 mln unikatowych obrazków z serwisu GeoCities (1994-2009), udostępniającego przestrzeń na zakładanie amatorskich stron domowych.
Każdy plik gif w tym zbiorze posiada własny URL, składający się z timestampu i oryginalnego adresu, możemy też sprawdzać, jak często i z jakim skutkiem był archiwizowany oraz zobaczyć kontekst, w jakim go opublikowano. To dobry wstęp do omówienia mechanizmu archiwizacji zasobów WWW i interfejsu Wayback Machine.


