
Wprowadzenie
Automatyczne wykrywanie twarzy (face detection) to różnorodne techniki maszynowego przetwarzania obrazu, które pozwalają na identyfikację i lokalizowanie twarzy ludzkich w materiałach wizualnych - tak statycznych obrazach jak i w nagraniach video. Bezpośrednim efektem działania narzędzi do wykrywania twarzy jest zestaw atrybutów, pozwalających na wyznaczenie granic w dwuwymiarowej przestrzeni obrazu, którą zajmuje każda pojedyncza twarz. Tak ten proces przebiega w usłudze demo platformy Microsoft Azure:

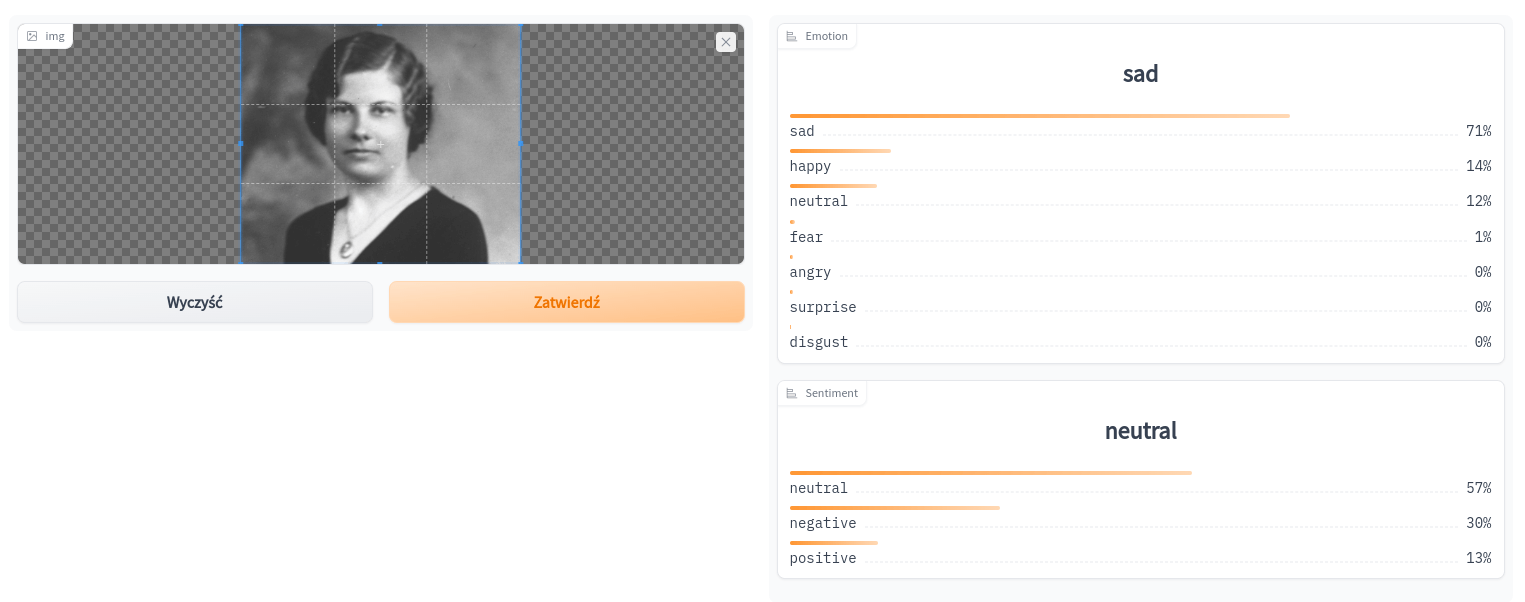
Poprawne wykrycie twarzy może być wstępem do jej późniejszej identyfikacji czy analizy, np. pod kątem emocji (Facial Expression Recognition, FER). Emocje wyrażane przez analizowaną twarz opisane są ogólnymi kategoriami, otrzymujemy informację o prawdopodobieństwie tego, że dana kategoria występuje. Przykładowo, tak emocje z portretu ze zbiorów Narodowego Archiwum Cyfrowego wykrywane są w przestrzeni schibsted-presplit/facial_expression_classifier w portalu HuggingFace (można tam przetestować własny obrazek):
W ramach tej lekcji zajmiemy się podstawami wykrywania twarzy.
Cele lekcji
Celem lekcji jest poznanie jednej z metod automatycznego wykrywania twarzy i sprawdzenie, czy nadaje się ona do pracy z fotografiami historycznymi. Nie będziemy korzystać z gotowych rozwiązań tylko napiszemy własne - użyjemy języka R i biblioteki OpenCV.
Efekty
Efektem naszej pracy będzie zestaw kilku fotografii ze zbiorów Narodowego Archiwum Cyfrowego, na których spróbujemy automatycznie wykryć twarze. Dowiemy się, jakie problemy mogą pojawić się przy wykrywaniu twarzy z archiwalnych materiałów wizualnych.
Wymagania
Praca z biblioteką OpenCV z wykorzystaniem języka R wymaga przygotowania odpowiedniego środowiska oraz podstawowych kompetencji programowania w R. Niestety, tym razem nie możemy pracować w Posit.cloud, ponieważ ta platforma nie daje dostępu do OpenCV. Dlatego konieczne jest postawienie własnego środowiska na komputerze - instalacja języka R, programu RStudio i biblioteki OpenCV. W systemie Ubuntu bibliotekę OpenCV instalujemy (przed rozpoczęciem pracy!) za pomocą polecenia:
sudo apt install libopencv-devR, RStudio i OpenCV są dostępne dla wszystkich systemów operacyjnych.
Część merytoryczna
Plan naszej pracy w ramach tej lekcji zakłada instalację biblioteki opencv dla R oraz napisanie kodu, który pozwoli na wyznaczenie twarzy na fotografiach historycznych z NAC. Jednak zanim zaczniemy pracę z kodem, spróbujemy dowiedzieć się, jak działa wykrywanie twarzy w OpenCV. Nie może być w tym przecież żadnej magii 😎.
Haar Cascades: analiza układów cieni i jasności
Wykorzystamy rozwiązanie dostępne standardowo w OpenCV, zdecydowanie nie najnowsze. Artykuł, który je opisuje - Rapid object detection using a boosted cascade of simple features opublikowano ponad dwadzieścia lat temu, jednak ponad 9.5 tys. cytowań świadczy o tym, że jego znaczenie dla rozwoju metod wykrywania twarzy jest fundamentalne. Podstawą opisanej w nim metody jest klasyfikator Haar Cascades.
Algorytm Haar Cascades przeszukuje obraz za pomocą prostokątnego okna o różnych rozmiarach, które przesuwa się po całym obrazie. W każdym położeniu okna analizowane są cechy Haar-like, czyli wzorce różnic w jasności między obszarami obrazu. Te cechy są wyrażane jako układ czarnych i białych prostokątów, które symbolizują ciemniejsze i jaśniejsze obszary. Na przykład, obszar oczu jest zwykle ciemniejszy niż policzki, co można rozpoznać jako charakterystyczny wzór (schemat) ludzkiej twarzy. Twarz jest rozpoznawana, jeśli znaleziony został zestaw trzech sąsiadujących ze sobą prostokątów (czarny, biały, czarny) lub inny, nawet bardziej skomplikowany układ, charakterystyczny dla wizerunków twarzy, które wykorzystano do trenowania.
Aby uniknąć zbędnego analizowania fragmentów obrazu i przyspieszyć proces, algorytm Adaboost wybiera najbardziej istotne cechy Haar-like spośród tysięcy możliwych. Dzięki temu kaskada klasyfikatorów może szybko odrzucać obszary, które na pewno nie zawierają twarzy, i dokładniej sprawdzać te, które wyglądają obiecująco. Takie podejście pozwala skutecznie wykrywać twarze na obrazach nawet w czasie rzeczywistym. Oto wizualizacja tego procesu:
Bardziej zaawansowany opis tej metody znajdziemy w dokumentacji OpenCV, na blogu Mirosława Mamczura oraz w opracowaniu Haar Cascades, Explained.
Korzystanie z wytrenowanego modelu
Kiedy będziemy korzystać z OpenCV, użyjemy już wytrenowanego modelu. Dostępne modele zapisane są w plikach XML, do których odwołuje się konkretna funkcja w naszej bibliotece opencv - mamy więc dowód wprost, że to żadne magiczne rozwiązanie:
ocv_face <- function(image){
facedata <- find_data_xml('haarcascades/haarcascade_frontalface_alt.xml')
eyedata <- find_data_xml('haarcascades/haarcascade_eye_tree_eyeglasses.xml')
cvmat_face(image, facedata, eyedata)
}
#' @export
#' @rdname opencv
ocv_facemask <- function(image){
facedata <- find_data_xml('haarcascades/haarcascade_frontalface_alt.xml')
cvmat_facemask(image, facedata)
}Aby użyć tej skomplikowanej metody, wystarczy kilka linijek kodu w R. Teraz możemy przejść do RStudio.
Wykrywamy twarz funkcją ocv_face
Po uruchomieniu RStudio zakładamy nowy projekt, wybierając z menu File opcję New project.Tworzymy pusty dokument R, w którym podajemy funkcję instalacji biblioteki opencv.
# 1. instalowanie pakietu i dodanie go do środowiska
install.packages('opencv')
library(opencv)Wysyłamy funkcję do wykonania konsoli (zaznaczając linię i wciskają CTRL + ENTER).
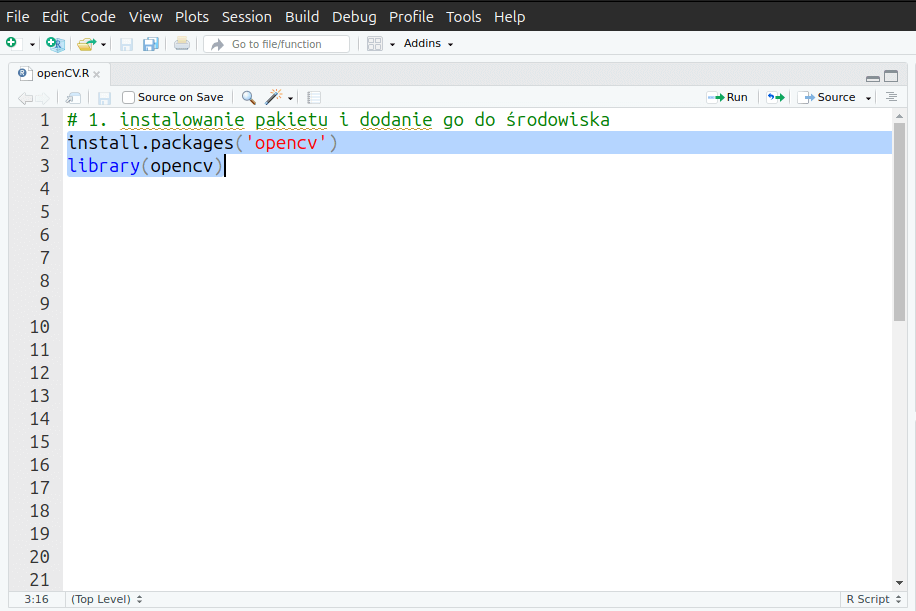
Pamiętajmy, że instalujemy jedynie nakładkę na funkcje i zasoby dużej biblioteki OpenCV, którą musimy już mieć w naszym systemie operacyjnym.
Pora teraz do środowiska przenieść kilka plików źródłowych ze zbiorów Narodowego Archiwum Cyfrowego (w domenie publicznej) - pliki dostępne są też na GitHubie. Umieszczamy je w katalogu naszego projektu, np. w podkatalogu nac_photos:
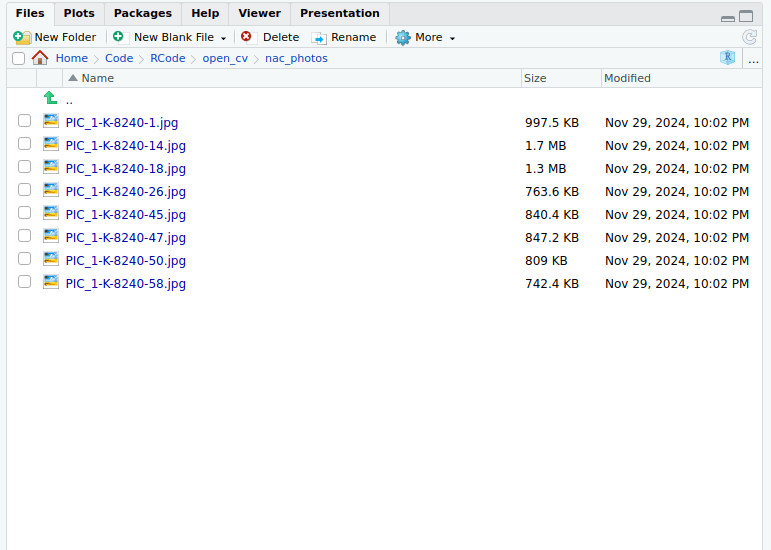
Spróbujmy najpierw wykryć twarze na pojedynczym zdjęciu. Stwórzmy katalog nac_faces i skorzystajmy z takiego kodu:
# 2. wczytanie pliku ze zdjęciem do środowiska
photo <- ocv_read('nac_photos/PIC_1-K-8240-1.jpg')
# 3. wykonanie rozpoznania funkcją ocv_face
# funkcja przyjmuje OBIEKT obrazka, a nie ścieżkę do niego!
photo_faces <- ocv_face(photo)
# 4. Zapisanie zdjęcia z oznaczonymi twarzami
ocv_write(photo_faces, 'nac_faces/faces_PIC_1-K-8240-1.jpg')Wykonanie tego kodu trwało tylko chwilę. W katalogu nac_faces mamy już plik faces_PIC_1-K-8240-1.jpg. Możemy ocenić jakość automatycznej analizy:

Zastanówmy się, jakiego typu twarze udało się modelowi rozpoznać, a jakie nie. Oznaczone kolorem są przede wszystkim twarze patrzące wprost - wszystkie pozostałe nie zostały wskazane, nawet jeśli na fotografii są wyraźniejsze niż np. twarz mężczyzny w lewej części zdjęcia. Oznaczenia dodane po prawej stronie (w kolorach zielonych) możemy uznać za błędy. Ogólna ocena tej próby maszynowego wyznaczania twarzy jest ze zrozumiałych względów niska.
Wykrywanie twarzy w pętli
Spróbujmy przetworzyć wszystkie pliki w nac_photos. Żeby nie powielać kodu, skorzystajmy z pętli for, prostej metody iteracji tych samych poleceń dla różnych danych.
Najpierw zbierzmy wszystkie nazwy plików z katalogu nac_photos:
# 5.1 zebranie nazw plików z katalogu nac_photos
photos <- dir("nac_photos")
# photos
# [1] "PIC_1-K-8240-1.jpg" "PIC_1-K-8240-14.jpg" "PIC_1-K-8240-18.jpg"
# [4] "PIC_1-K-8240-26.jpg" "PIC_1-K-8240-45.jpg" "PIC_1-K-8240-47.jpg"
# [7] "PIC_1-K-8240-50.jpg" "PIC_1-K-8240-58.jpg"Następnie piszemy pętlę, w której za każdą iteracją wczytywany będzie jeden plik z katalogu nac_photos, wykonywana będzie na nim funkcja ocv_face i plik wynikowy zapisywany będzie z przedrostkiem faces_ w katalogu nac_faces:
# 5.2 napiszmy pętlę
for(photo in photos) {
# wczytanie pliku do środowiska
# funkcją paste0 łączymy ścieżkę dostępu
p <- ocv_read(paste0('nac_photos/', photo))
# analiza funkcją ocv_face
p_faces <- ocv_face(p)
# zapisanie pliku wynikowego
# do oryginalnej nazwy pliku dodajemy faces_
ocv_write(p_faces, paste0('nac_faces/faces_', photo))
}Fotografie z czerwca 1936 roku, dokumentujące wizytę w Polsce światowej sławy śpiewaka Jana Kiepury, to wdzięczny obiekt testów maszynowego wykrywania twarzy. Ich techniczna jakość jest niska (w porównaniu z jakością współczesnych fotografii cyfrowych), a tylko nieliczne twarze w tłumie wielbicieli i gapiów są skierowane frontalnie w stronę aparatu. Widać bardzo dobrze, że metoda Haar Cascades nie pozwala na wykrycie twarzy, jeśli ta uwidoczniona jest z profilu:







Gdybyśmy chcieli maszynowo wyodrębić twarze z przetworzonych zdjęć, np. w celu wygenerowania kolażu, musielibyśmy użyć innego niż biblioteka opencv rozwiązania, np. kodu w Pythonie.
Podsumowanie
W ramach tej lekcji przetestowaliśmy wykrywanie twarzy za pomocą klasyfikatora Haar Cascades, rozwiązania uczenia maszynowego, które dostępne jest już od 2001 roku. Czy nadaje się ono do pracy z fotografiami historycznymi? Wydaje się, że nie. Haar Cascades działa najlepiej na wizerunkach, na których portretowana osoba patrzy na wprost, najlepiej z neutralnym wyrazem twarzy. Modele Haar Cascades, używane w bibliotece OpenCV, są trenowane na obrazach przedstawiających twarze w widoku frontalnym (frontal face detection). Kiedy pracujemy z fotografiami historycznymi, nie zawsze mamy do czynienia z takimi ujęciami.
Na skuteczność wykrywania twarzy na zdjęciach historycznych ma wpływ to, że bardzo często nie są to fotografie portretowe. Ich jakość techniczna nie jest najlepsza, pojawiają się rozmycia, niedoskonałości, złe światło. Problemem są też nakrycia głowy, tłum (zasłanianie niektórych twarzy przez osoby stojące obok) oraz twarze nie spoglądające wprost. Jeśli twarz jest obrócona, pochylona lub uchwycona pod nietypowym kątem, algorytm może jej nie wykryć.
Ta lekcja pokazała nam, jak ważne do realizacji określonego zadania jest odpowiednie dobranie algorytmu. Z Haar Cascades korzystać można do analizy zdjęć portretowych, fotografie przedstawiające tłum w ruchu można opracowywać za pomocą innych metod. Jedną z nich są sieci konwolucyjne (CNN), które analizują obrazy w sposób imitujący funkcjonowanie ludzkiego wzroku.
Poniżej przykład efektywności takiej sieci (przestrzeń hysts/ibug-face_detection) na platformie HuggingFace:

Wykorzystanie metod
Co może dać nam automatyczne wykrywanie twarzy w badaniach humanistycznych? Można za pomocą tego typu narzędzi np. badać style narracyjne seriali pod kątem obecności w nich postaci różnych płci. Taką analizę przygotowano dla amerykańskich sitkomów “Bewitched” (1964–1972) i “I Dream of Jeannie” (1965–1970). Wykorzystano algorytmy do wykrywania twarzy i lokalizacji postaci w kadrach oraz identyfikacji momentów przejścia między ujęciami i scenami, co pozwoliło na przygotowanie wizualizacji pozwalającej w nowy sposób spojrzeć na te produkcje filmowe.
W kontekście zbiorów archiwów, maszynowe wykrywanie twarzy może pomóc w przygotowywaniu podstawowych metadanych - opisujących choćby to, czy na fotografii są przedstawione jakieś osoby i ile tych osób jest. W projekcie Civil War Photo Sleuth (CWPS) maszynowe wykrywanie twarzy jest wstępem do łączenia ze sobą różnych wizerunków tych samych osób - żołnierzy wojny secesyjnej:

Pomysł na warsztat
Możemy przygotować prosty warsztat z wykrywania twarzy, korzystając z przestrzeni hysts/ibug-face_detection na platformie HuggingFace. Celem warsztatu byłoby przetestowanie ograniczeń w działniu tego typu rozwiązań, np. za pomocą analizowania fotografii twarzy w różnym ujęciu, z różnymi elementami zakrywającymi, takimi jak okulary, kapelusze, maski czy zarost. Obrazy do analizy mogą pochodzić z kamery laptopa - żadne pliki nie są udostępniane do HuggingFace.
Ciekawym zadaniem byłoby skorzystanie z narzędzi takich jak Fawkes, które komplikują proces wykrywania twarzy, czy nawet z tymczasowego makijażu.


