
Wprowadzenie
W 2019 roku w Twitterze zainicjowano projekt badawczy Bluesky, który już trzy lata później stał się niezależną firmą. W 2024 roku z zarządu tej firmy odszedł Jack Dorsey - w ten sposób Bluesky zerwał wszystkie relacje z Twitterem. Dziś, wobec upadku platformy X, którą stał się Twitter pod rządami Elona Muska, Bluesky widziany jest jako wartościowa alternatywa.
Czy jest nią rzeczywiście? W listopadzie 2024 roku z Bluesky korzystało 20 mln użytkowników - to wciąż dwa razy mniej niż samych tylko kont na Twitterze, kontrolowanych przez boty (48 mln w 2020 roku). Bluesky obiecuje jednak nowe podejście do mediów społecznościowych, w którym ważna jest podmiotowość użytkownika, dostęp do danych i kontrola nad algorytmami wyświetlania treści.
Cele lekcji
Celem lekcji jest przetestowanie dostępności danych z platformy Bluesky za pomocą kwerend, wykonywanych w języku R. Twitter (X) praktycznie zamknął dostęp do swoich danych, a jego właściciel niemal ręcznie steruje zasadami wyświetleń treści w tym serwisie. Czy Bluesky może być dla badaczy i badaczek kultury interesującą platformą? Im więcej kont instytucji kultury powstaje w tej przestrzeni, tym bardziej warto spróbować wykorzystać jej otwartość.
Efekty
Efektem naszej lekcji będą przetworzone dane, opracowane na podstawie wpisów wybranych kont na platformie Bluesky. Nauczymy się, jak za pomocą R łączyć się z interfejsem programistycznym (API) tej platformy i pobierać z niej interesujące nas dane.
Wymagania
Do tej pracy konieczna jest podstawowa znajomość R i konto na platformie Posit.cloud. Niezbędne jest też konto na Bluesky - aby połączyć się z API, musimy się uwierzytelnić. Konto może być anonimowe, nie podajemy tam żadnych danych finansowych - konieczne jest jednak podanie adresu email. Będziemy pracować z biblioteką bskyr.
Część merytoryczna
Zanim zaczniemy pracę z API Bluesky, dowiedzmy się, w jaki sposób działa ta platforma. W odróżnieniu od Twittera, Bluesky korzysta z otwartego standardu Authenticated Transfer Protocol (AT Protocol, ATProto). Protokół to w informatyce nic innego jak zestaw reguł, które umożliwiają maszynom komunikowanie się ze sobą. Każdy z nas codziennie korzysta z protokołów, np. wysyłając maile czy odwiedzając strony WWW.
Twitter i efekty centralizacji
Twitter, którego dziś musimy nazywać X, to przykład mocno scentralizowanej platformy społecznościowej. Użytkownicy X zakładają swoje konta na serwerach kontrolowanych przez tę firmę, także wszystkie dane przechowywane są centralnie. Kontrolę nad danymi ma wyłącznie X i korzysta z tego w pełni, np. bardzo mocno ograniczając dostęp do nich przez interfejs programistyczny (API). Miesięczny koszt dostępu do API X w modelu, który pozwalałby na pobranie 10 tys. tweetów, to 200 dolarów, przy 1 mln tweetów to już 5 tys. dolarów. Takie koszty skutecznie blokują podejmowanie badań nad X jako przestrzenią społeczną czy ograniczają działania strażnicze, np. w ramach walki z dezinformacją.
Centralizacja X objawia się także w tym, że sposób, w jaki użytkownikom wyświetlane są treści, jest ustalany odgórnie. Prowadzi to do poważnych nadużyć. Jak informuje portal The Verge:
Kiedy Musk ogłosił swoje wsparcie dla kampanii prezydenckiej Donalda Trumpa, platforma X Elona Muska mogła zmodyfikować swój algorytm w celu zwiększenia zasięgu jego konta oraz kont innych użytkowników o konserwatywnych poglądach. Dowodzi tego nowe badanie opublikowane przez Queensland University of Technology (QUT), wykazujące nagły i znaczny wzrost popularności wpisów Muska.
AT Protocol: przeciwko centralizacji sieci społecznościowych
Przeciwieństwem takiego modelu platformy społecznościowej jest Bluesky. Źródło odmienności Bluesky wynika z zastosowania ATP. Po pierwsze, zakładanie konta i przechowywanie danych użytkownika ma miejsce w jednym z autoryzowanych repozytoriów utrzymywanych na rozproszonych Serwerach Danych Personalnych (Personal Data Server, PDS). Dane te wymieniane są i przetwarzane dzięki wspólnemu standardowi i publikowane w wybranym interfejsie (nie musimy korzystać wyłącznie z serwisu bsky.app). Co więcej, moderacja treści to nie globalna funkcja w ramach całej infrastruktury, ale działania na poszczególnych PDS. Użytkownicy mogą też dostosowywać algorytmy wyświetlania treści do własnych potrzeb - nie jest to ustalane centralnie.
Czy taki sposób prowadzenia platformy społecznościowej - m.in. brak pełnej kontroli nad danymi użytkowników - może być utrzymywany przez jakikolwiek model biznesowy? Twórcy Bluesky przekonują, że tak:
Bluesky to korporacja o statusie public benefit corporation (korporacji służącej interesowi publicznemu), której misją jest „opracowywanie i wspieranie na dużą skalę technologii umożliwiających otwarty i zdecentralizowany dialog społeczny”. Status public benefit corporation pozwala nam realizować naszą misję ponad koniecznością generowania zysków, jednak wciąż musimy pracować nad tym, aby Bluesky był zrównoważoną usługą, co jest niezbędne do utrzymania trwałego i otwartego ekosystemu.
Bluesky ma nie zarabiać na reklamach wyświetlanych użytkownikom, ponieważ sama struktura systemu uniemożliwia takie wykorzystanie ich danych. Zamiast tego, jako public benefit corporation, Bluesky korzysta z finansowania początkowego (seed) w wysokości 8 mln dolarów (2023) oraz eksperymentuje z płatnymi usługami. Każdy użytkownik tej platformy może np. wykupić unikalną domenę i dodać ją do swojego oficjalnego identyfikatora w sieci ATP.
Zdalna autoryzacja w Bluesky
Zacznijmy konkretną pracę. Zalogujmy się na Posit.cloud - oczywiście możemy też pracować w RStudio na własnym komputerze. Musimy teraz pobrać i wczytać do środowiska bibliotekę bskyr - pozwoli nam ona w łatwy sposób łączyć się z oficjalnym API Bluesky, wykorzystującym szablon danych w ramach ATP, określany jako lexicon.
install.packages('bskyr')
library(bskyr)Musimy teraz założyć darmowe konto na Bluesky. Po potwierdzeniu maila, przechodzimy na stronę ustawień prywatności i zabezpieczeń. Pamiętajmy, że interfejs aplikacji możemy ustawić w taki sposób, aby wszystkie podpisy i nazwy elementów wyświetlały się w języku polskim.
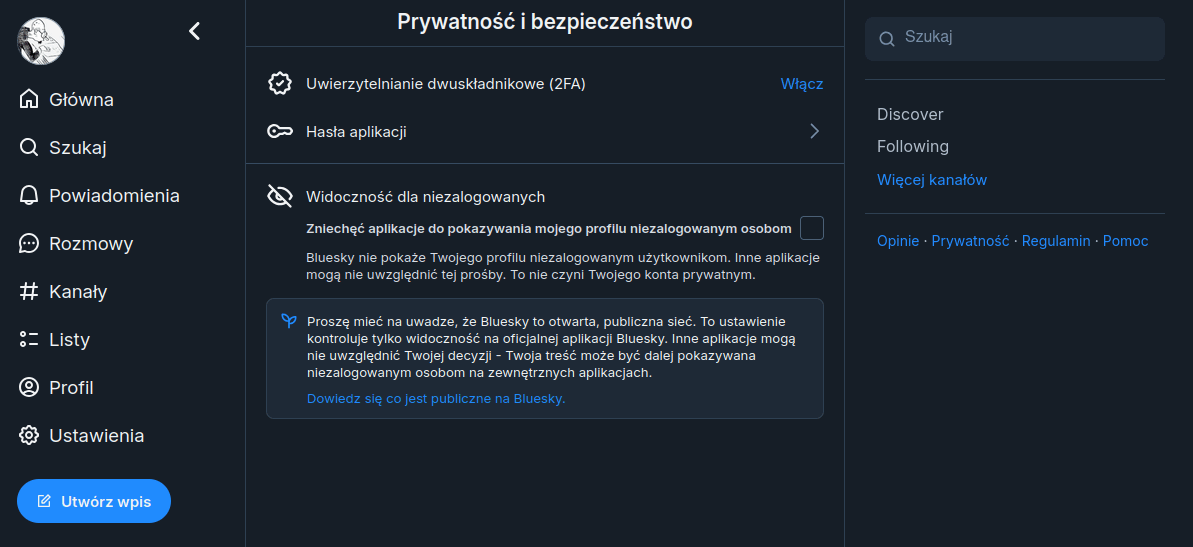
W ustawieniach prywatności i zabezpieczeń wybieramy odnośnik Hasła aplikacji. Ustawiamy nazwę aplikacji, przez którą będziemy pobierać dane:
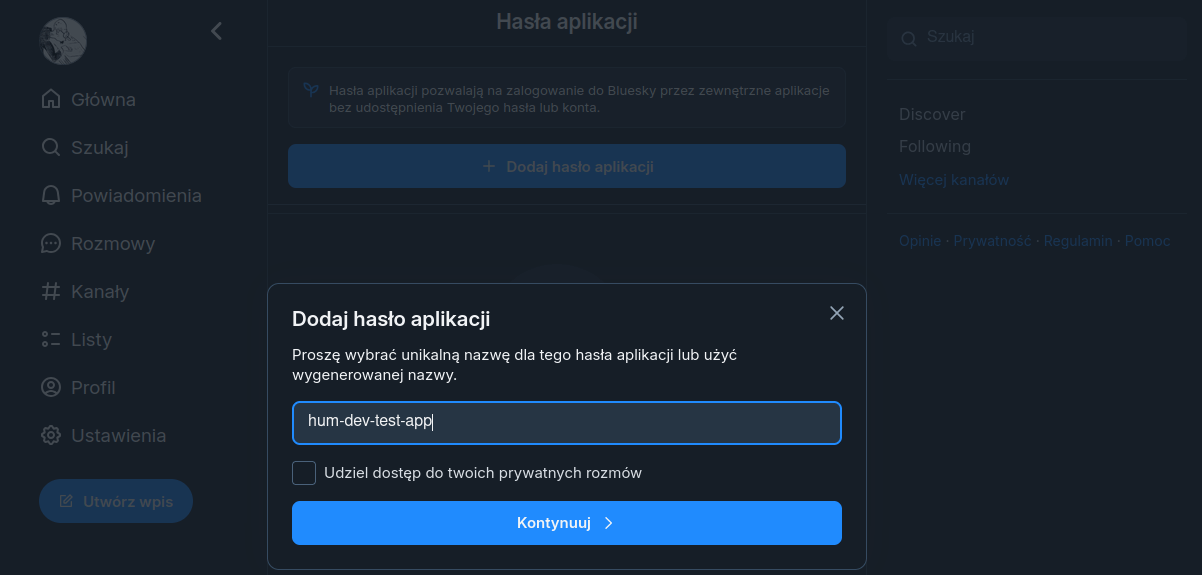
…oraz podajemy hasło. To hasło nie może być zgubione - nie ma żadnej opcji, żeby je odzyskać (należy wówczas wygenerować nowe). Nazwę i hasło aplikacji wykorzystamy w kodzie R, za pomocą którego będziemy łączyć się z API Bluesky. Używamy do tego dwóch funkcji z pakietu bskyr, który mamy już w środowisku:
# nazwa użytkownika - wpisz tu swoją nazwę użytkownika
# (nie nazwę aplikacji)
set_bluesky_user('XXXXXXXXX.bsky.social')
# hasło - podmień na hasło założonej przed chwilą aplikacji
set_bluesky_pass('XXXX-XXXX-XXXX-XXXX')Taka metoda autoryzacji działa wyłącznie w jednej sesji - jeśli zamkniemy projekt Posit.cloud lub okno RStudio, sesja wygaśnie i wygaśnie też autoryzacja dostępu. Przy ponownym uruchomieniu kodu znów będziemy musieli się autoryzować (tymi samymi danymi). Obejściem tego problemu jest skorzystanie z rozwiązania, opisanego w dokumentacji.
Pobieranie postów z konta Bluesky
Po poprawnej autoryzacji powinniśmy być w stanie pobrać wpisy z wybranego konta Bluesky. Oczywiście nie jest to jedyne zastosowanie API tej platformy, jednak jedno z najprostszych i najbardziej oczywistych. Pozwoli nam sprawdzić, czy biblioteka i kody dostępowe działają oraz podejrzeć strukturę danych o wpisach.
Na Bluesky pojawia się coraz więcej użytkowników, są wśród nich także instytucje kultury i dziedzictwa, takie jak np. Muzeum Historii Naturalnej Hrabstwa Los Angeles. Na platformie jest co prawda już przynajmniej jedna polska instytucja kultury - Zamek Królewski w Warszawie, jednak jak dotąd opublikowano tam zbyt mało wpisów, żebyśmy mogli je z sensem przeglądać i przetwarzać w R.
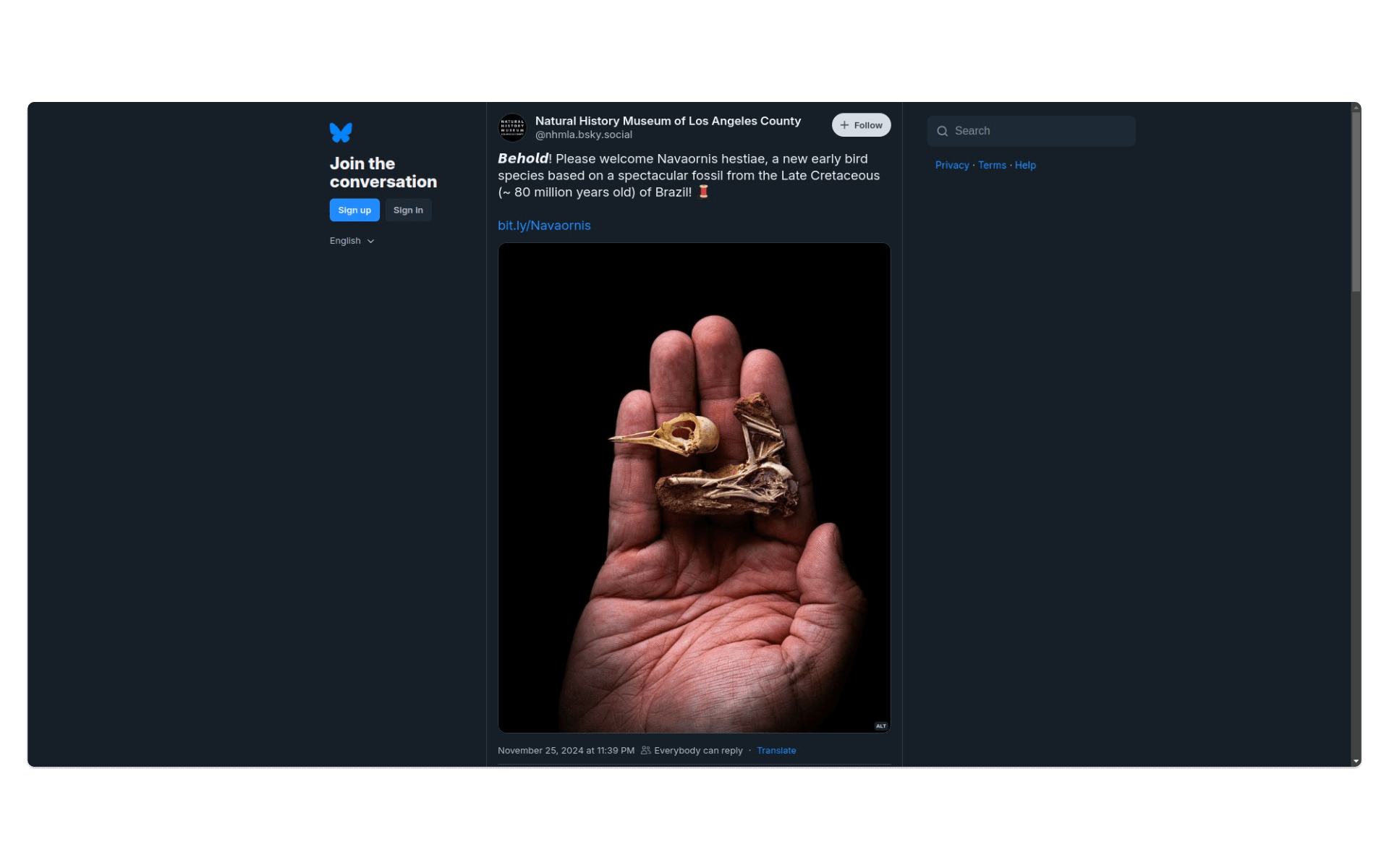
Do pobrania wpisów z profilu wybranego konta (w terminologii Bluesky - aktora) służy m.in. funkcja bs_get_author_feed:
bs_get_author_feed(
actor,
cursor = NULL,
limit = NULL,
user = get_bluesky_user(),
pass = get_bluesky_pass(),
auth = bs_auth(user, pass),
clean = TRUE
)Zwróćmy uwagę na parametry tej funkcji: actor to identyfikator użytkownika Bluesky, limit - wskazanie, ile wpisów chcemy pozyskać, cursor - wartość kursora z wcześniejszej odpowiedzi. Ten ostatni parametr wydaje się nieco tajemniczy, więc wyjaśnijmy, że chodzi tu o wskazanie, jaką stronę wyników (listy wpisów) pozyskać. Jeśli limit wynosi więcej niż 100, funkcja dzieli zapytania na mniejsze części, żeby zmieścić się w ograniczeniach serwera. Informacja o tym, jaka strona wyników była ostatnio przetwarzana, znajduje się właśnie w parametrze cursor. Parametr clean ustawia formatowanie danych wynikowych do postaci uproszczonej ramki danych - tibble.
Wyślijmy nasze zapytanie do Bluesky:
# ściągamy wpisy użytkownika o identyfikatorze nhmla.bsky.social
timeline <- bs_get_author_feed("nhmla.bsky.social")Otrzymaliśmy 50 wpisów. Spróbujmy pobrać wszystkie, jakie zostały dotąd opublikowane na tym koncie (352):
timeline <- bs_get_author_feed("nhmla.bsky.social", limit=352)Otrzymaliśmy …348 wpisów, być może te cztery brakujące to posty przypięte (pins), nie zaracane w takim zapytaniu - tak możemy przypuszczać po lekturze kodu źródłowego getAuthorFeed.json, dokumentującego implementację Protokołu AT w Bluesky. To zresztą świetnie pokazuje, jak ważna jest dobra dokumentacja API w badaniach.
Przetwarzanie danych o postach z Bluesky
Nasze dane (timeline) to uproszczona ramka danych (tibble), a więc dwuwymiarowa tabela. Możemy poruszać się po niej, korzystając z indeksów. Nasza ramka danych jest olbrzymia - ma ponad 1300 kolumn! Spróbujmy przetworzyć do CSV dane dotyczące obrazków umieszczonych w treści wpisów:
# ta kolumna zabiera adresy URL obrazków
# timeline$post_embed.images.fullsize...279
# oczywiście nie każdy wpis zawiera obrazek
sum(!is.na(timeline$post_embed.images.fullsize...32))
# [1] 63
# tylko 63 wpisy zawierają obrazek
sum(is.na(timeline$post_embed.images.fullsize...32))
# [1] 285
# w tym kodzie do obiektu images zapiszemy tylko te wiersze całej ramki danych, w których znajdują się odnośniki do obrazków
images <- timeline[!is.na(timeline$post_embed.images.fullsize...32), ]
# write.csv zapisze ramkę danych images do pliku CSV
write.csv(images, "images.csv", row.names = FALSE)Nasz plik CSV będzie miał ponad 1000 kolumn! Nie możemy się zgodzić na coś takiego, dlatego za pomocą pakietu dplyr w prosty sposób wybierzemy kolumny do eksportu. Użyjemy przetwarzania potokowego:
install.packages("dplyr")
library(dplyr)
# znak operatora potokowego %>% wpisujemy za pomocą kombinacji Ctrl + Shift + M
# do images2 została zapisana wartość images, ale przefiltrowana (wyłącznie z wyznaczonymi w funkcji select() kolumnami)
images2 <- images %>% select(post_uri, post_cid, post_author.handle, post_record.created_at, post_like_count, post_embed.images.fullsize...32)
write.csv(images2, "images2.csv", row.names = FALSE)Możemy teraz sprawdzić, jaka była maksymalna liczba polubień dla wpisu z obrazkiem. Kolumna post_like_count zawiera w sobie oryginalnie wartości tekstowe - “1” zamiast 1, stąd do wyliczenia maksimum potrzebujemy funkcji, która zamieni te wartości na wartości liczbowe - as_integer():
max((as.integer(images2$post_like_count)))
# [1] 208Na zakończenie tej lekcji spróbujmy znaleźć obrazek, który zebrał najwięcej polubień:
hot_image <- images2 %>% filter(post_like_count == "208") %>% select(post_embed.images.fullsize...32)
hot_image$post_embed.images.fullsize...32
# [1] "https://cdn.bsky.app/img/feed_fullsize/plain/did:plc:v4dpm7icom54y366e76xy3mj/bafkreibeejdzksjrlqmg6xhw5u74xd7nedqteifejta6y2u4v5phkjdk5e@jpeg"Powyższy kod jest trochę skomplikowany, ale działa. Do obiektu hot_images zapisujemy wynik przetwarzania obiektu images2. To przetwarzanie polega na przefiltrowaniu kolumny post_like_count i - ostatecznie - wybraniu tylko jednej kolumny post_embed.images.fullsize…32, w której znajdziemy ścieżkę do pliku.
Kliknijmy tutaj, żeby zobaczyć ten obrazek 💀.
Podsumowanie
Udało nam się podłączyć do API Bluesky oraz pobrać i przetworzyć wybrane dane. To oczywiście tylko przykład możliwości pakietu bskyr - w kolejnej lekcji spróbujemy wykorzystać go do automatycznego wysyłania wiadomości na Bluesky. Przygotujemy w R prostego bota 🤖.
Wykorzystanie metod
Twoje posty z Bluesky prawdopodobnie znajdują się teraz w wielu zestawach danych.
przekonuje dziennikarka portalu 404media.
Infrastruktura Bluesky to miecz obosieczny: z jednej strony jej zdecentralizowany charakter daje użytkownikom większą kontrolę nad ich treściami niż serwisy takie jak X czy Threads, z drugiej strony oznacza, że każde zdarzenie na stronie jest katalogowane w publicznym feedzie. Istnieje uzasadnione badawcze użycie postów z mediów społecznościowych, ale badacze przestrzegają zazwyczaj etycznych i prawnych reguł dotyczących wykorzystania tych danych. Na przykład w opublikowanym na początku tego roku artykule naukowym, który wykorzystywał posty z Bluesky do analizy na temat tego, jak dezinformacja i fałszywe informacje rozprzestrzeniają się w internecie, użyto zbioru danych zawierającego 235 milionów postów, które zostały zanonimizowane. Badacze wskazali przy tym jasne instrukcje co do usunięcia własnych danych z tego zbioru.
Pierwotnie udostępniony publicznie ten zestaw danych jest już zastrzeżony - środowisko naukowe było w stanie w tym przypadku same sobie narzucić pewne reguły, ograniczające swobodny dostęp do treści, jakie użytkownicy publikują na Bluesky. Trudno jednak oczekiwać, żeby taka autokrytyczna postawa stała się powszechna, dlatego możemy założyć, że publikowanie na Bluesky to praktyczna zgoda na to, żeby nasze wpisy trafiały do publicznych zbiorów danych, nawet bez anonimizacji.
Pomysł na warsztat
Korzystanie z API Bluesky może być ciekawym pomysłem na warsztat z R. Pozyskanie danych jest proste, a ich format przyjazdny do dalszej analizy. Jak zwykle przy pracy z danymi platform społecznościowych, warto krytycznie przejrzeć się ich zakresowi. Czy Bluesky jest rzeczywiście przyjazne dla prywatności swoich użytkowników? Czy są oni w tej przestrzeni traktowani podmiotowo? Można też wspólnie zastanowić się, czy założenia zdecetralizowanej sieci, wyrażone w standardzie ATP, rzeczywiście będą mogły być utrzymane, kiedy Bluesky będzie musiało coraz bardziej komercjalizować platformę, choćby ze względu na rosnące koszty obsługi wzrastającej liczby użytkowników.


