
Wprowadzenie
W poprzedniej lekcji Wyodrębniamy nazwy geograficzne z biogramów wybitnych Polek XIX wieku (część I) przetworzyliśmy w narzędziu Geolocation (na platformie CLARIN-PL) niewielki korpus osiemnastu wikipedystycznych biogramów wybitnych Polek XIX wieku. Z biogramów wyodrębniliśmy nazwy geograficzne, które dodatkowo zostały opisane dokładnymi koordynatami. To dobry zasób do przygotowania mapy.
Cele lekcji
Wykorzystaliśmy narzędzie do rozpoznawania jednostek nazwanych (Named Entity Recognition, NER) do wyodrębnienia nazw miejscowości i krajów, w których przebywały bohaterki naszych biogramów. Teraz przygotujemy na podstawie tych danych kilka map, przy okazji sprawdzając, jak ChatGPT radzi sobie z pracą z danymi w postaci JSON i z maszynowym tworzeniem map.
Efekty
Efektem naszej lekcji będzie zbiór przetworzonych danych i mapy, gotowe do udostępnienia w internecie.
Wymagania
Korzystamy z danych już przygotowanych i dostępnych w repozytorium GitHub. Będziemy używać ChatGPT - konieczny jest przy tym dostęp do wersji 4.0, która umożliwia upload plików. To standardowa wersja w płatnym pakiecie, ale włączona jest także w pakiecie darmowym - tutaj jesteśmy ograniczeni jednak tylko do kilku zapytań.
Część merytoryczna
ChatGPT to nie tylko przestrzeń rozmowy, której celem może być uzyskanie odpowiednich informacji, parafraza tekstów czy wygenerowanie obrazka. To także platforma, w której pracować możemy z danymi. To dość ciekawe połączenie poleceń w języku naturalnym z kodem wykonywanym w tle. Jak czytamy na stronie OpenAI:
Podczas analizy danych, ChatGPT uzyskuje dostęp do bezpiecznego środowiska, w którym wykonywany jest kod. Środowisko to jest wstępnie wyposażone w setki bibliotek Pythona, a ChatGPT potrafi pisać kod w celu zaimportowania i skorzystania z tych bibliotek. Środowisko ma dostęp do plików załączonych do promptu ChatGPT, co umożliwia interakcję z przesłanymi przez Ciebie danymi strukturalnymi.
Spróbujmy sprawdzić, jak taki setup sprawdzi się przy przetwarzaniu danych z jednego, wybranego biogramu.
Konwersja z JSON do tabeli CSV
Geolocation przetworzył nam wszystkie biogramy do postaci danych JSON. Znajdują się w nich m.in. pełen tekst biogramu oraz - najbardziej interesujące nas - klucze records i geolocation. geolocation to lista, w której umieszczone są informacje o poszczególnych punktach geograficznych, jakie udało się wyznaczyć:
[
{
"obj-id": "269c6fc6-b90c-44f7-8a34-a758f3bd1bf5",
"name": "województwo podlaskie, Polska",
"type": "administrative",
"lat": 53.2668455,
"lon": 22.8525787,
"importance": 0.69134395347837
},
{
"obj-id": "e3bd6ca0-b0c2-4b00-81d8-566ee961ecea",
"name": "Grodno, obwód grodzieński, Białoruś",
"type": "city",
"lat": 53.6834599,
"lon": 23.8342648,
"importance": 0.66452669323231
},
{
"obj-id": "e26c9579-bf8f-4439-9625-1823e8d8f410",
"name": "Grodno, obwód grodzieński, Białoruś",
"type": "city",
"lat": 53.6834599,
"lon": 23.8342648,
"importance": 0.66452669323231
},
{
"obj-id": "9dc27d2e-0557-4be5-a8f0-830e576833d3",
"name": "Jungfrau, Lauterbrunnen, Verwaltungskreis Interlaken-Oberhasli, Verwaltungsregion Oberland, Berno, 3801, Szwajcaria",
"type": "peak",
"lat": 46.5367739,
"lon": 7.9625907,
"importance": 0.56328064002702
}
]W danych wytworzonych z biogramu Elizy Orzeszkowej tablica geolocation ma aż 45 elementów (przy czym niektóre pojawiają się wielokrotnie). Ponieważ plik Eliza_Orzeszkowa.txt jest duży i skomplikowany, wykorzystajmy ChatGPT do jego uproszczenia.
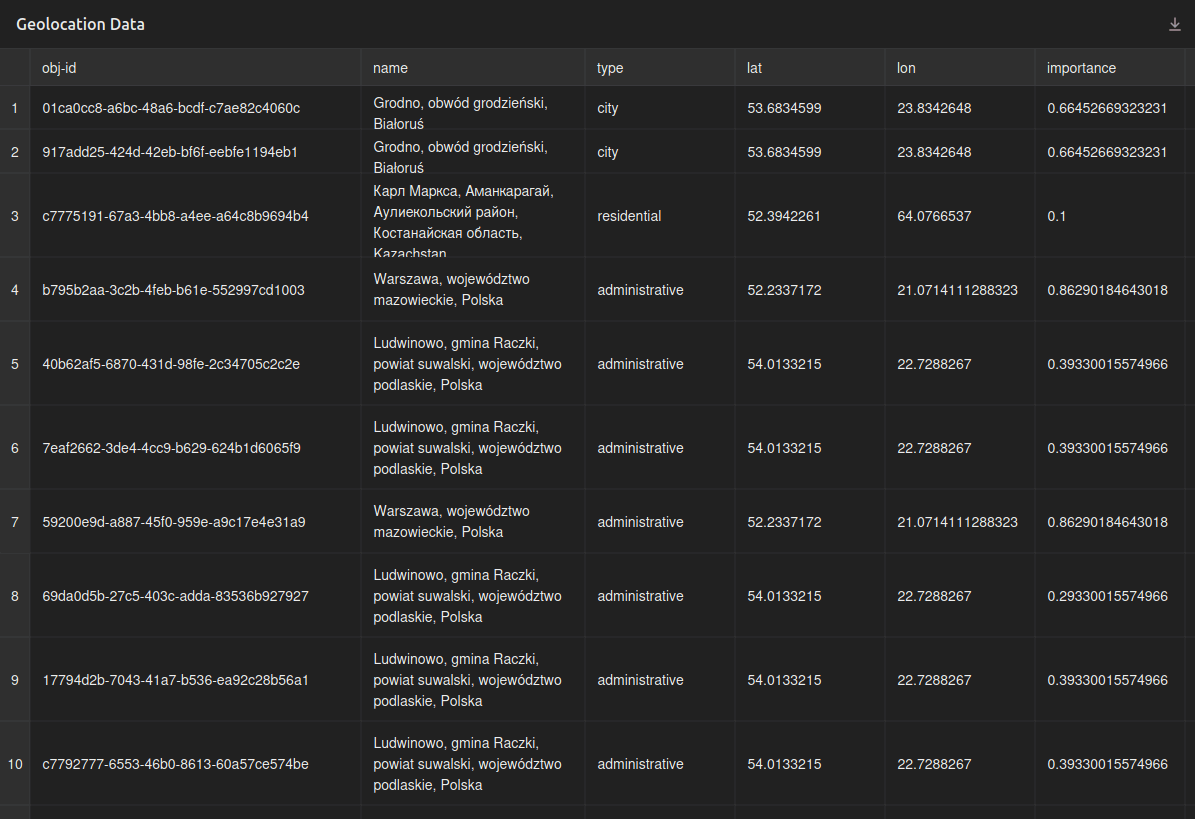
Każdy element listy punktów geograficznych zawiera takie klucze: obj-id, name, type, lat, lon, importance. Jeśli te dane przetworzymy z postaci JSON do tabeli, klucze te staną się po prostu nagłówkami poszczególnych kolumn.
Logujemy się do ChatGPT i zaczynamy nową konwersację. Umieszczamy na platformie plik Eliza_Orzeszkowa.txt i podajemy następujący prompt:
udostępniam ci plik tekstowy, w którym są dane JSON. wyodrębnij dane z klucza records i geolocation i wygeneruj tabelę, która je przedstawi. w tabeli kazda kolumna niech ma wartosc kolejnego klucza z obiektow, znajdujacych sie w geolocationTo, co moglibyśmy zrobić bezpośrednio w R czy Pythonie za pomocą odpowiednich poleceń i funkcji, próbujemy zrobić poleceniami wyrażonymi w języku naturalnym, które zostaną przetworzone przez model językowy i następnie wysłane do środowiska Pythona. Czy to oznacza, że programujemy? Być może, z jednej strony realizujemy przecież zadania za pomocą kodu Pythona, z drugiej strony nie mamy bezpośredniego wpływu na to, jakie metody przetwarzania naszych danych zostaną użyte.

W czasie testów okazało się, że ChatGPT nie potrafił poradzić sobie z faktem, że dane JSON zapisane są w pliku z rozszerzeniem txt, stąd w prompcie bezpośrednie wskazanie na plik tekstowy, w którym są dane JSON.
Po wygenerowaniu odpowiedzi, którą jest tabela z 45 wierszami, możemy podejrzeć proces przetwarzania danych w Pythonie. To zdecydowanie nie model językowy, ale biblioteki Pythona pozwalają wykonać nasze zadanie:
Efektem naszej pracy jest prosta tabela, której kolumny reprezentują klucze każdego obiektu z listy geolocation:
Analiza danych z tabeli
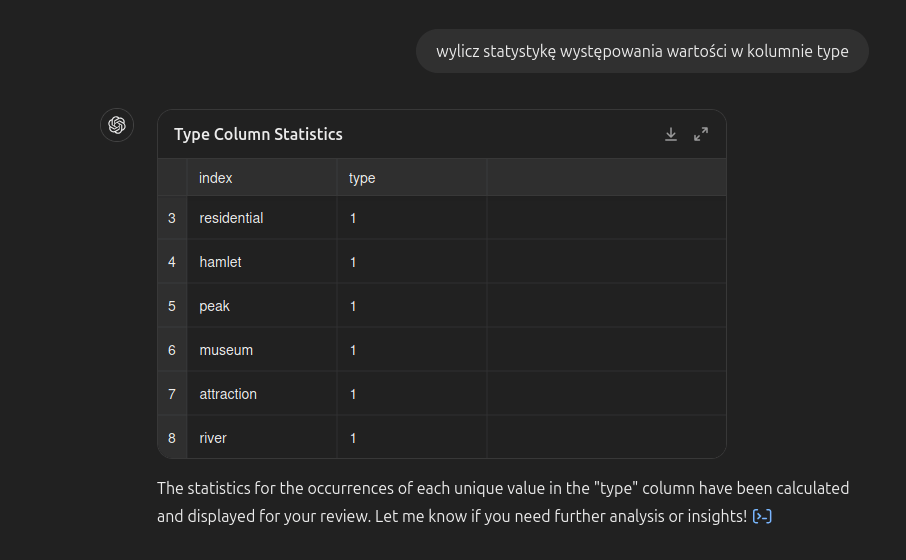
Dane wyświetlone za pomocą tabeli łatwiej zinterpretować. Co więcej, korzystając z ChatGPT, możemy spróbować wykonać na niej odpowiednie przeliczenia. Być może dobrym pomysłem byłoby zebranie statystyk typów nazw (punktów) geograficznych, które zostały wyodrębnione z biogramu Orzeszkowej. Niech ChatGPT w Pythonie przeanalizuje kolumnę type:
wylicz statystykę występowania wartości w kolumnie typeW efekcie:
W Pythonie można też generować wykresy - skorzystajmy z tej możliwości za pomocą promptu, odwołującego się do właśnie przetworzonych danych:
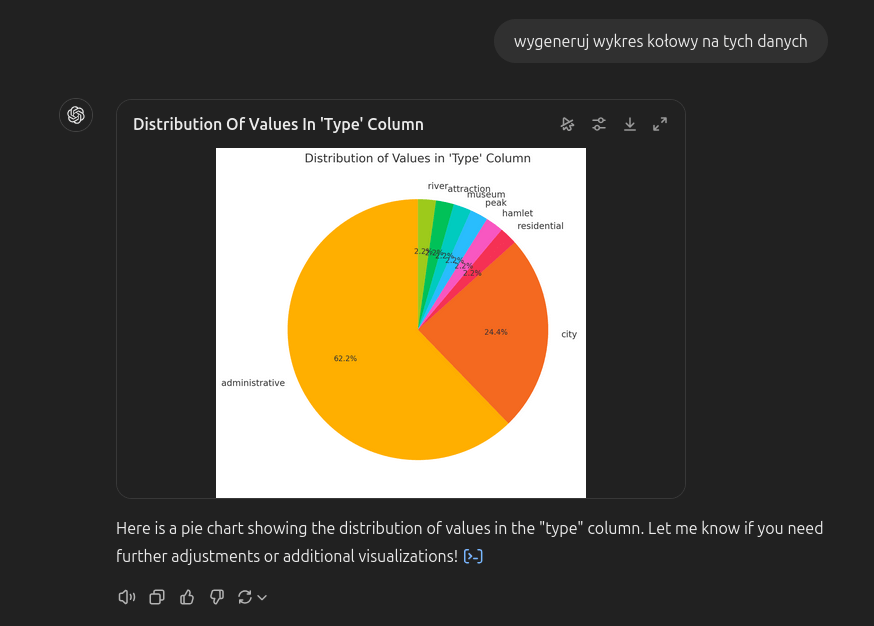
Typy, jakimi opisane są wyodrębnione z tekstu nazwy geograficzne, to region administracyjny, miasto, osiedle, osada, szczyt, muzeum, atrakcja i rzeka.
Generowanie mapy
ChatGPT wykorzysta bibliotekę Folium, aby wygenerować w Pythonie mapę z naszymi danymi. Spróbujmy wysłać taki prompt:
na podstawie tabeli z danymi geograficznymi wygeneruj mapę do pobrania i umieszczenia online. niech każdy typ punktu geograficznego zostanie oznaczony markerem innego koloru, a po kliknięciu w marker pojawi się w dymku nazwa punktu i jego importanceZwróćmy uwagę, że dokładnie opisujemy cechy mapy: definiujemy właściwości markerów i wydarzenia (events), które mają się uruchamiać po kliknięciu w nie. W efekcie otrzymujemy mapę w postaci pliku HTML do pobrania.
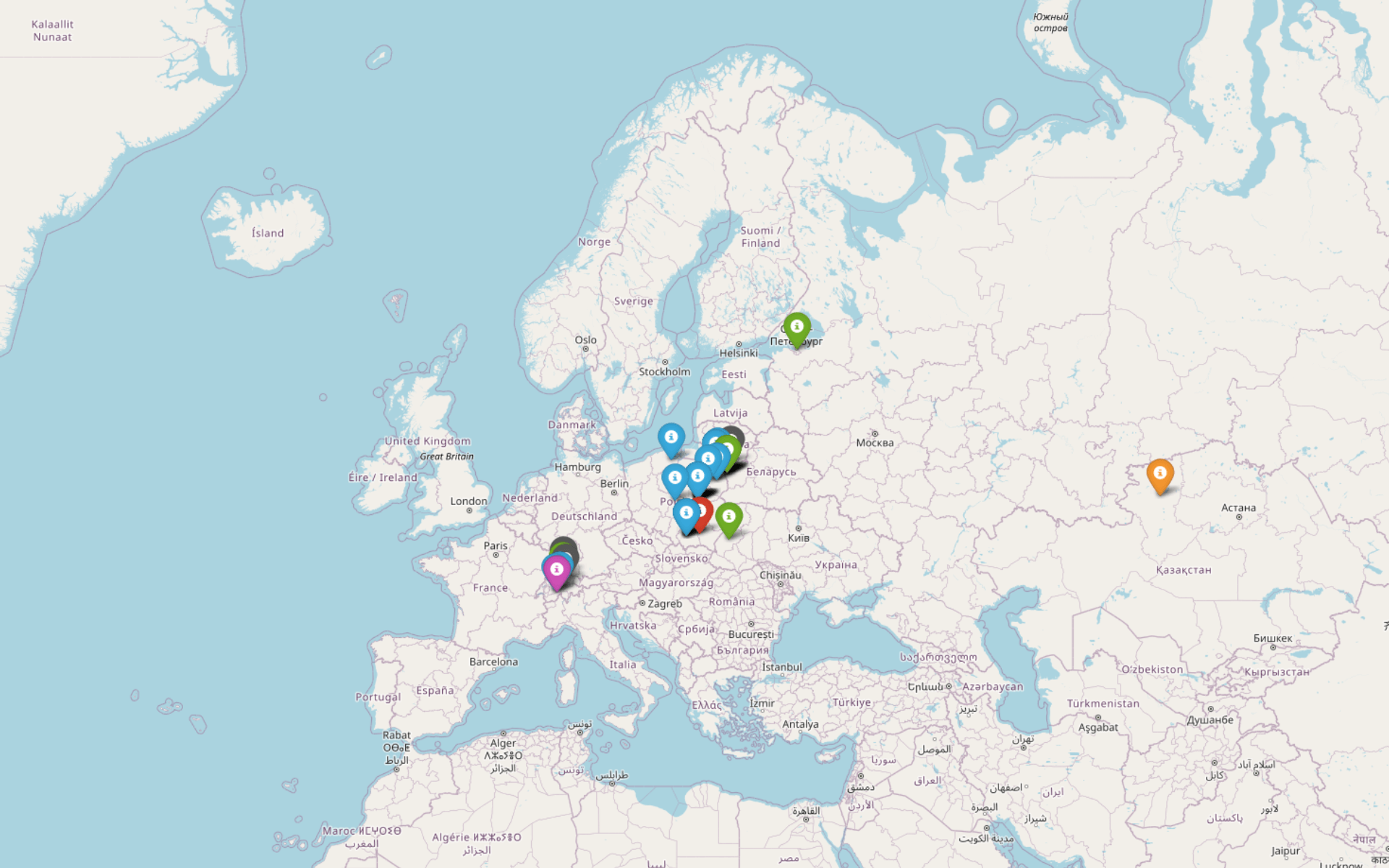
Mapa wygląda nieźle, można ją zoomować i przesuwać, niestety jej wadą jest współczesny podział polityczny - granice krajów w żaden sposób nie odpowiadają realiom XIX-wiecznej Europy. Liczba punktów na mapie nie wynosi 45, chociaż nasza tabela ma 45 wierszy - jak pamiętamy, niektóre z nazw i koordynatów punktów się powtarzają.
Skorzystajmy z tego jako dodatkowej informacji i załóżmy, że im częściej w biogramie pojawia się nazwa geograficzna, tym jest istotniejsza z punktu widzenia historii życia naszej bohaterki. Poniższmy prompt może nam pomóc wygenerować mapę, która zilustruje najczęściej wymieniane w biogramie Orzeszkowej nazwy geograficzne:
przetwórz mapę tak, aby jeśli dany punkt występuje więcej niż raz, jego marker był większy odpowiednią ilość razy. niech po kliknięciu w punkt pokazuje się wartość name. przygotuj mapę do pobrania.Fraza przygotuj mapę do pobrania jest fundamentalna, ponieważ zmusi ChatGPT do wygenerowania gotowego pliku HTML. W innym razie otrzymamy krótki tutorial, jak samodzielnie w Pythonie wygenerować taką mapę, a na tym nam nie zależy 😊.
Gotowa mapa prezentuje się w taki sposób:
Przetworzenie wszystkich biogramów
Skoro przećwiczyliśmy już generowanie mapy z pojedynczego biogramu, spróbujmy zrobić to dla wszystkich osiemnastu. W tym celu wyślijmy do ChatGPT plik geolocation_full.zip. Praca z ChatGPT polega w dużej mierze na pisaniu jak najbardziej efektywnych promptów, więc dajmy sobie przestrzeń na eksperymentowanie i załóżmy, że nie od razu uda nam się wygenerować poprawną mapę.
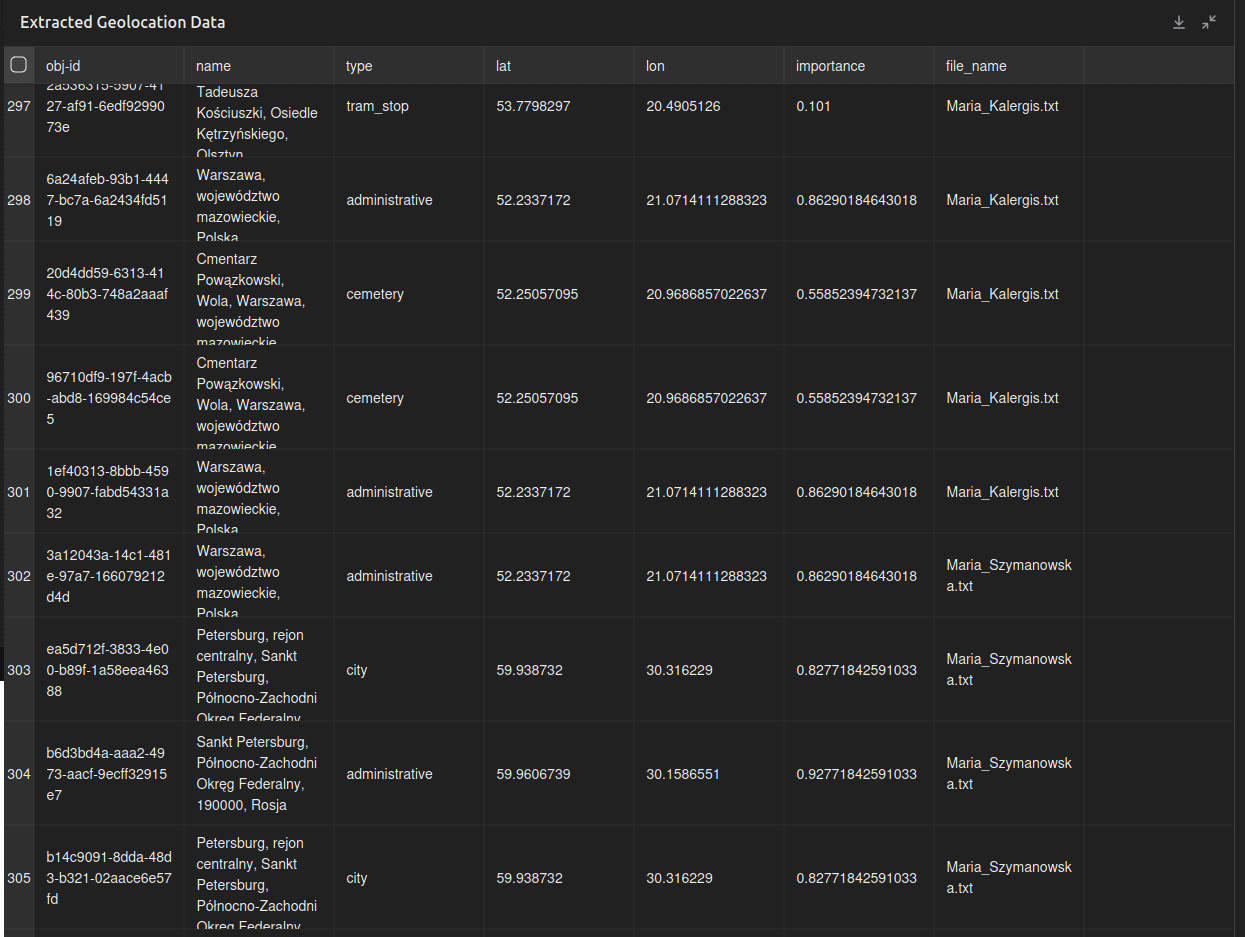
Najpierw przetwórzmy wszystkie dane do tabeli:
udostępniam ci plik zip, w którym są pliki tekstowe, w których są dane JSON. wyodrębnij z tych plików wszystkie dane z klucza records i geolocation i wygeneruj tabelę, która je przedstawi. w tabeli kazda kolumna niech ma wartosc kolejnego klucza z obiektow, znajdujacych sie w geolocation oraz kolumnę file_name, w której podasz nazwę pliku, z którego wyodrębniłaś dane geograficzneW razie problemów, szczególnie jeśli ChatGPT nie będzie w stanie znaleźć danych geograficznych, możemy spróbować polecić mu przeanalizowanie jednego pliku w całości. Dzięki temu zrozumie schemat danych i przygotuje nam oczekiwane przez nas zestawienie:
Generowanie mapy dla wszystkich biogramów
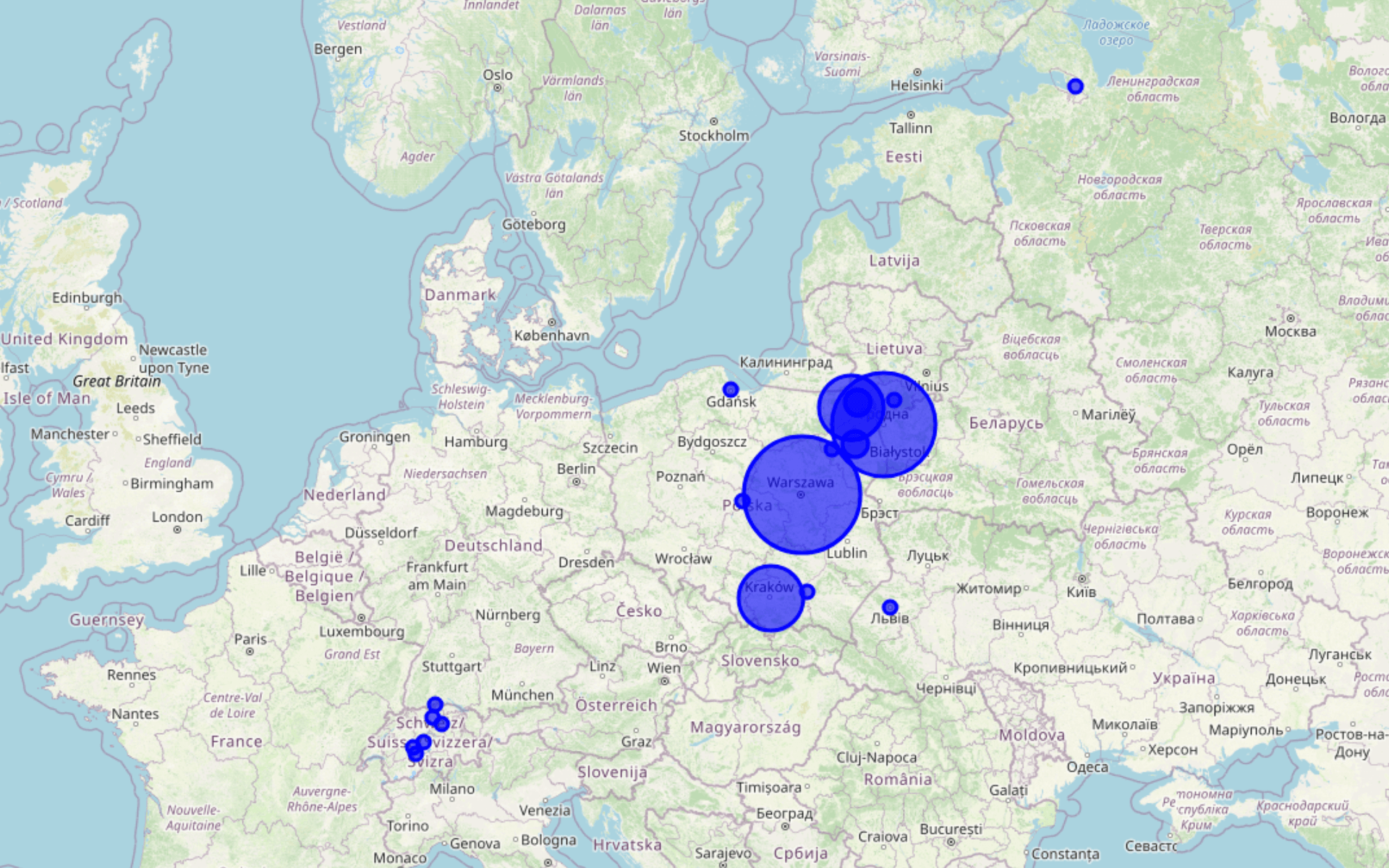
Skoro mamy już dane dla wszystkich osiemnastu biogramów, umieśćmy je na mapie! Zrezygnujmy z tworzenia markerów, raczej skorzystajmy z możliwości wizualizacji tego, jak często w danym biogramie pojawia się odwołanie do wybranego punktu geograficznego. Kolorami wyróżnijmy punkty reprezentujące każdy z biogramów.
przetwórz te dane na mapę do pobrania. zwizualizuj każdy punkt. jeśli punkt występuje w danym pliku więcej niż raz, odpowiednio go zwiększ. zróżnicuj kolory dla punktów z różnych plików. do punktów dodaj dymki z wartością name, type i file_name. niech dymek otwiera się po kliknięciu w punktW efekcie otrzymujemy mapę, na której możemy zidentyfikować kluczowe regiony dla historii życia analizowanych przez nas kobiet:

Uwaga na błędy i halucynowanie!
Halucynowanie to jedno z największych ograniczeń ChatGPT. O ile tego typu błędy i mistyfikacje możemy z powodzeniem wykryć przy pracy z odpowiedziami w postaci tekstowej, to trudno to zrobić przy okazji przetwarzania danych. Jeśli mielibyśmy sprawdzać je ręcznie, po co nam pośrednictwo ChatGPT? Tego typu automatyzacja nie ma sensu.
Żeby uniknąć ręcznego sprawdzania danych, możemy skorzystać z prompta
sprawdź poprawność danych i mapy, tak żeby uniknąć halucynowania
Czy zaufamy tego typu zapewnieniom? A może ChatGPT nadaje się wyłącznie do wstępnych analiz, a poprawne dane i porządną mapę powinniśmy przygotować samodzielnie?
Podsumowanie
ChatGPT obiecuje nam duże ułatwienia w pracy z danymi, jednak wciąż nie mamy pewności, czy efekt jego przeliczeń jest odpowiedniej jakości. Z pewnością można wykorzystać go do podstawowej pracy z danymi i próbnych wizualizacji, ale trudno powiedzieć, czy nadają się one do pokazania na konferencji lub w artykule naukowym. Być może pewnym rozwiązaniem jest ręczna walidacja danych na każdym etapie ich przetwarzania - w naszym przypadku musielibyśmy dokładnie sprawdzić tabelę z danymi przed rozpoczęciem pracy z mapą. Połączenie modelu językowego ze środowiskiem programistycznym dla Pythona to samo w sobie bardzo ciekawe rozwiązanie - możemy dzięki niemu (w ograniczonym zakresie) programować w języku naturalnym.
Wadą naszych danych i mapy jest to, że nie wzięliśmy pod uwagę kontekstu, w jakim pojawiły się nazwy geograficzne w tekstach biogramów.
Wykorzystanie metod
Taki kontekst udało się załapać autorom bardzo ciekawego opracowania Following the footsteps of giants: modeling the mobility of historically notable individuals using Wikipedia (2019). W swojej pracy analizowali oni wzorce migracji osób historycznie znaczących (historically notable individuals) i wykorzystali techniki przetwarzania języka naturalnego, aby z treści wikipedystycznych biografii tych osób wyodrębnić miejsca i daty urodzenia i śmierci oraz znaczących wydarzeń w życiu, związanych z migracją.
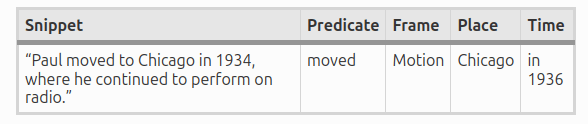
Słowa takie jak Moving, Arriving, Being_employed, Transfer czy Travel pozwoliły automatycznie wyznaczyć wydarzenia z biografii tych osób, a dane z FrameNet i dbpedii zmapować je do punktów geograficznych. W ten sposób powstała mapa migracji, dokumentująca losy 2407 osób:
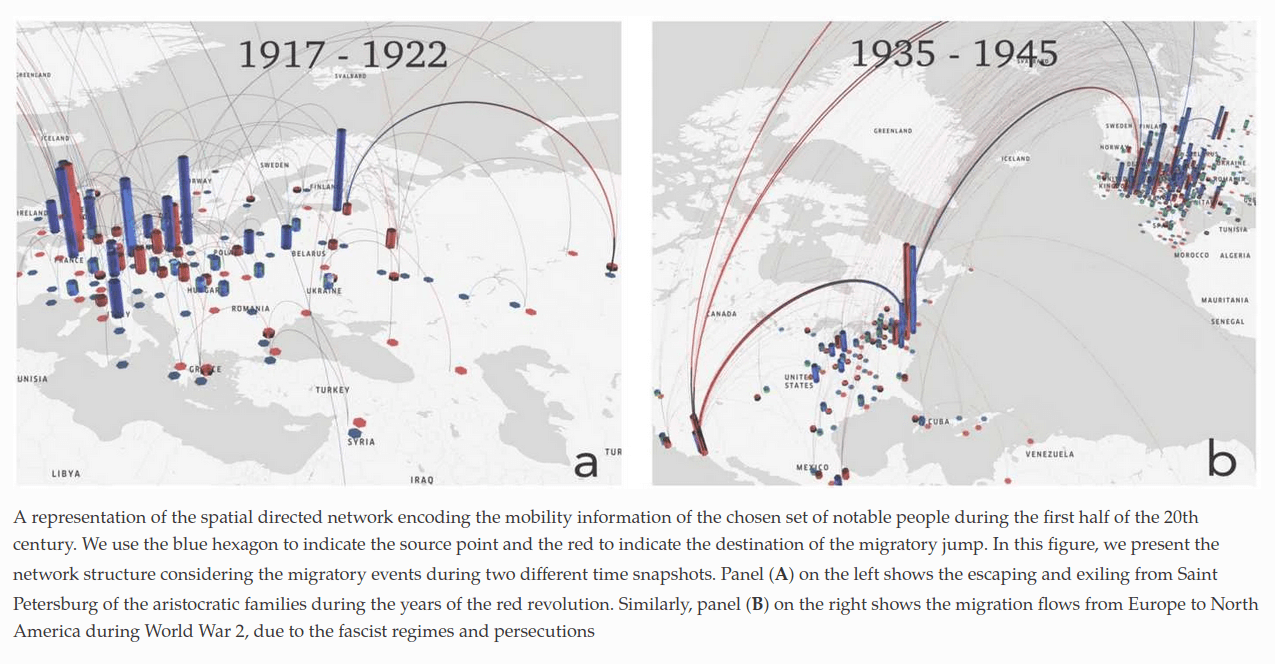
Pomysł na warsztat
Celem warsztatu może być nauka przetwarzania danych bez programowania: ChatGPT wykorzystujemy jako narzędzie, które jest w stanie zamienić polecenia w języku naturalnym na odpowiedni kod programu w Pythonie. W trakcie takiego warsztatu możemy pracować z gotowymi już danymi (np. pobranymi z tej strony) i koncentrować się na ich czyszczeniu, uzupełnianiu, przetwarzaniu do różnych formatów czy wizualizowaniu za pomocą wykresów czy map.
Warsztat można zaplanować w ten sposób, żeby uczestnicy mogli korzystać z darmowego konta ChatGPT (założenie go wymaga jednak podania numeru telefonu). Dane do przetwarzania można wysyłać bezpośrednio w prompcie, np. w postaci CSV.


