
Wprowadzenie
Rozpoznawanie jednostek nazwanych (Named Entity Recognition, NER) to jedna z ciekawszych metod maszynowego przetwarzania języka naturalnego. Odpowiednie modele i narzędzia językowe takie jak GLiNER, spaCy czy WiNER pozwalają automatycznie wyodrębniać wybrane klasy słów z przetwarzanego korpusu, np. imiona i nazwiska, nazwy geograficzne, nazwy instytucji i organizacji, numery telefonów itp.
Cele lekcji
Celem lekcji, złożonej z dwóch części, jest przygotowanie i wizualizacja danych geograficznych, wyodrębnionych z niewielkiego korpusu. Korpus ten zawiera treści osiemnastu haseł z polskiej Wikipedii, opisujących biogramy wybitnych Polek żyjących w XIX wieku. Wykorzystamy NER do wyodrębnienia nazw miejscowości i krajów, w których te kobiety przebywały, a pozyskane dane przetworzymy w ChatGPT do postaci mapy.
Efekty
Efektem pierwszej części naszej lekcji poświęconej NER będzie przetworzony korpus osiemnastu haseł, zawierający m.in. wyodrębnione nazwy geograficzne wraz z koordynatami (długością i szerokością geograficzną). Taki zasób będzie podstawą przygotowania mapy w ChatGPT, czym zajmiemy się w drugiej części tej lekcji.
Wymagania
Nasz korpus składać się będzie z treści wybranych haseł polskiej Wikipedii. Możemy pobrać je ręcznie albo skorzystać z cyklu lekcji Analizujemy maszynowo hasła Wikipedii poświęcone muzeom (część I, część II), w których nauczyliśmy się, jak to zrobić w języku R z wykorzystaniem pakietu WikipediR. Do wygodnej pracy w R potrzebujemy darmowego konta na platformie Posit.cloud. Osoby, które od razu chcą pracować z gotowymi źródłami, mogą z nich skorzystać w repozytorium GitHub.
Potrzebujemy też narzędzia NER - skorzystamy z platformy konsorcjum CLARIN-PL. Tu również musimy się zalogować. W drugiej części lekcji użyjemy ChatGPT - koniecznie w wersji 4.0, pozwalającej na upload plików. Taka wersja dostępna jest też (w ograniczonym zakresie) na darmowym koncie.
Część merytoryczna
Baza historii kobiet to projekt Muzeum Historii Kobiet. Jak czytamy na stronie muzeum, tylko 4 proc. postaci opisywanych w podręcznikach to kobiety, tylko 10 proc. ulic nosi imię kobiety i tylko 10 proc. polskich szkół ma kobiecą patronkę:
Kobiet brakuje w podręcznikach. W nazwach ulic. Nie ma kobiecych postaci na pomnikach, banknotach, nie ma zbyt wielu patronek szkół. Ich dzieł jest niewiele w muzeach. Gdy po raz pierwszy zaczniesz to dostrzegać i nad tym się zastanawiać, trudno już o tym zapomnieć. To bolesne i bardzo niesprawiedliwe. My chcemy oddać kobietom należne im miejsce Jesteśmy kobietami, a naszą tożsamość – tak jak naszych mam, babek i prababek – tworzy wiele różnych ról. Herstoria to opowieść o nich wszystkich, ukazująca ich złożoność i bogactwo – na przekór stereotypowym przekonaniom i oczekiwaniom. Pokazująca, że dokonania kobiet oraz ich codzienne decyzje miały i mają znaczenie dla wszystkich.
Skorzystajmy z Bazy Historii Kobiet, aby zidentyfikować kobiety ważne dla historii XIX wieku.
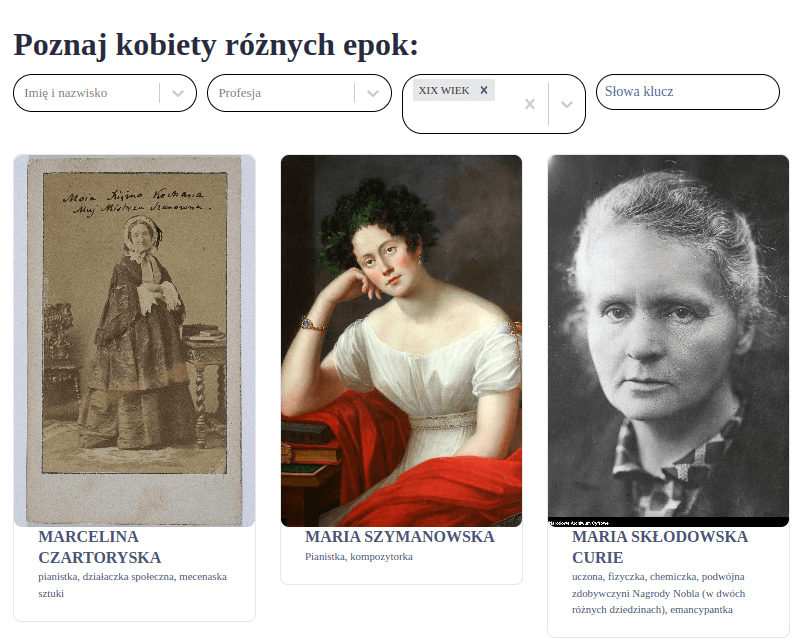
Oczywiście filtrowanie po sztywnych granicach czasowych (XIX wiek) ma ograniczoną wartość - chociaż Maria Skłodowska-Curie urodziła się jeszcze w latach 60. XIX wieku, to szczyt jej kariery naukowej przypadł już na początek XX wieku (nagrody nobla z 1903 i 1911 roku). Uznajmy jednak, że możemy przyjąc wyrysowany tak grubą kreską zakres naszej analizy - gromadzimy dane do ćwiczenia, a nie do pracy naukowej.
Skorzystamy z Bazy Historii Kobiet wyłącznie po to, aby zebrać informację o konkretnych nazwiskach wybitnych Polek - ich biogramy pobierzemy z Wikipedii, bo potrafimy to zrobić automatycznie.
Przygotowanie środowiska i danych wejściowych
Oto tytuły (nazwy) haseł Wikipedii, z których chcemy pobrać treść:
Marcelina_Czartoryska
Maria_Szymanowska
Maria_Skłodowska-Curie
Klaudyna_Potocka
Aniela_Tułodziecka
Narcyza_Żmichowska
Jadwiga_Zamoyska
Ksawera_Deybel
Eliza_Orzeszkowa
Maria_Dulębianka
Olga_Boznańska
Jadwiga_Łuszczewska
Helena_Modrzejewska
Julia_Molińska-Woykowska
Seweryna_Duchińska
Maria_Kalergis
Olga_Drahonowska-Małkowska
Emilia_SczanieckaLogujemy się do Posit.cloud i zakładamy nowy projekt. Wykorzystamy pętlę for, żeby za pomocą metody page_content pobrać i przetworzyć dane z wybranych haseł Wikipedii.
Zaczynamy od zainstalowania niezbędnych pakietów i wczytania ich do środowiska:
install.packages('WikipediR')
install.packages('stringi')
library(WikipediR)
library(stringi)Pakiet stringi ułatwia pracę z ciągami tekstowymi. Za chwilę skorzystamy z niego w naszym kodzie, najpierw jednak przygotujmy dane wyjściowe. Nazwy haseł Wikipedii, które będziemy przetwarzać, umieśćmy w wieloelementowym wektorze:
persons <- c(
"Marcelina_Czartoryska",
"Maria_Szymanowska",
"Maria_Skłodowska-Curie",
"Klaudyna_Potocka",
"Aniela_Tułodziecka",
"Narcyza_Żmichowska",
"Jadwiga_Zamoyska",
"Ksawera_Deybel",
"Eliza_Orzeszkowa",
"Maria_Dulębianka",
"Olga_Boznańska",
"Jadwiga_Łuszczewska",
"Helena_Modrzejewska",
"Julia_Molińska-Woykowska",
"Seweryna_Duchińska",
"Maria_Kalergis",
"Olga_Drahonowska-Małkowska",
"Emilia_Sczaniecka"
)W pakiecie WikipediR dostępna jest metoda (funkcja) page_content, którą możemy użyć za pomocą następującej składni:
test <- page_content("pl", "wikipedia", page_name = "Maria_Skłodowska-Curie")Pierwsze dwa argumenty przesyłane do tej funkcji (pl, wikipedia) wskazują na źródło danych: pl.wikipedia.org. Parametr page_name przyjmuje tytuł (nazwę) hasła - zwróćmy uwagę na jego zapis (to część ścieżki URL hasła).
Po testowym uruchomieniu funkcji otrzymamy listę, w której znajdziemy treść hasła - strukturę pozyskanych danych możemy podejrzeć za pomocą funkcji str:
str(test)
#List of 1
# $ parse:List of 4
# ..$ title : chr "Maria Skłodowska-Curie"
# ..$ pageid: int 3544
# ..$ revid : int 75240478
# ..$ text :List of 1
# .. ..$ *: chr "<div class=\"mw-content-ltr mw-parser-output\" lang=\"pl\" dir=\"ltr\"><div class=\"noprint noexcerpt disambig "| #__truncated__
# - attr(*, "class")= chr "pcontent"Jak widać, interesujący nas tekst znajduje się w obiekcie test, który jest listą i zawiera listę 🥲 text, której jedynym elementem jest kod HTML z treścią hasła. Musimy zwrócić na to uwagę przy przetwarzaniu naszych biogramów.
Przygotowanie pętli i pozyskanie danych
Mamy do pobrania treść osiemnastu haseł, których nazwy umieściliśmy w obiekcie persons. Możemy użyć takiego kodu, aby pobrać z nich treści i zapisać je do plików:
for (person in persons) {
# 1. Wyświetlamy nazwę aktualnie przetwarzanego hasła
# funkcja paste0 pozwala nam połączyć nazwę hasła ze znakiem nowej linii,
# dzięki czemu nazwy haseł będą pojawiać jedno pod drugim
cat(paste0(person, '\n'))
# 2.Pobieramy treść hasła, dynamicznie wysyłając do page_name aktualną wartość person
wp_content <- page_content("pl", "wikipedia", page_name = person)
# 3. Tworzymy obiekt wp_txt, który zawiera treść hasła. Pamiętajmy, że to wciąż lista!
wp_txt <- wp_content$parse$text
# 4. Korzystając z pakietu stringi i funkcji stri_trans_general zamieniamy nazwę hasła na taką postać,
# która nadaje się jako nazwa pliku (usunięcie polskich znaków)
# Zamiana spacji na podkreślenia możliwa jest dzięki funkcji gsub
file_name <- stri_trans_general(person, "Latin-ASCII")
file_name <- gsub(" ", "_", file_name)
# 5. Do każdej nazwy pliku dodajemy rozszerzenie txt
file_name <- paste0(file_name, ".txt")
# 6.Zapisujemy plik pod dynamicznie generowaną nazwą.
# Funkcja unlist pozwala nam przetworzyć wp_txt z listy do postaci ciągu tekstowego
writeLines(unlist(wp_txt), file_name)
}Po uruchomieniu pętli w katalogu project znajdziemy wszystkie wygenerowane pliki. Musimy je wyeksportować ze środowiska Posit.cloud:
Udało nam się wygenerować osiemnaście plików. To pliki txt zawierające kod HTML (części stron internetowych, którymi są przecież hasła Wikipedii). Nie musimy się jednak tym przejmować - narzędzia CLARIN-PL dobrze radzą sobie z przetwarzaniem kodu HTML do czystego tekstu.
Spakujmy te pliki do katalogu wikipedia_persons.zip (pliki te dostępne są już na GitHub).
Usługa wyznaczania danych geolokalizacyjnych
Przejdźmy do platformy CLARIN-PL. Po zalogowaniu wybierzmy usługę Geolocation. Usługa wykorzystuje m.in. dane z platformy GeoNames i OpenStreetMap oraz narzędzia NER: winer, spaCy czy WiNER.
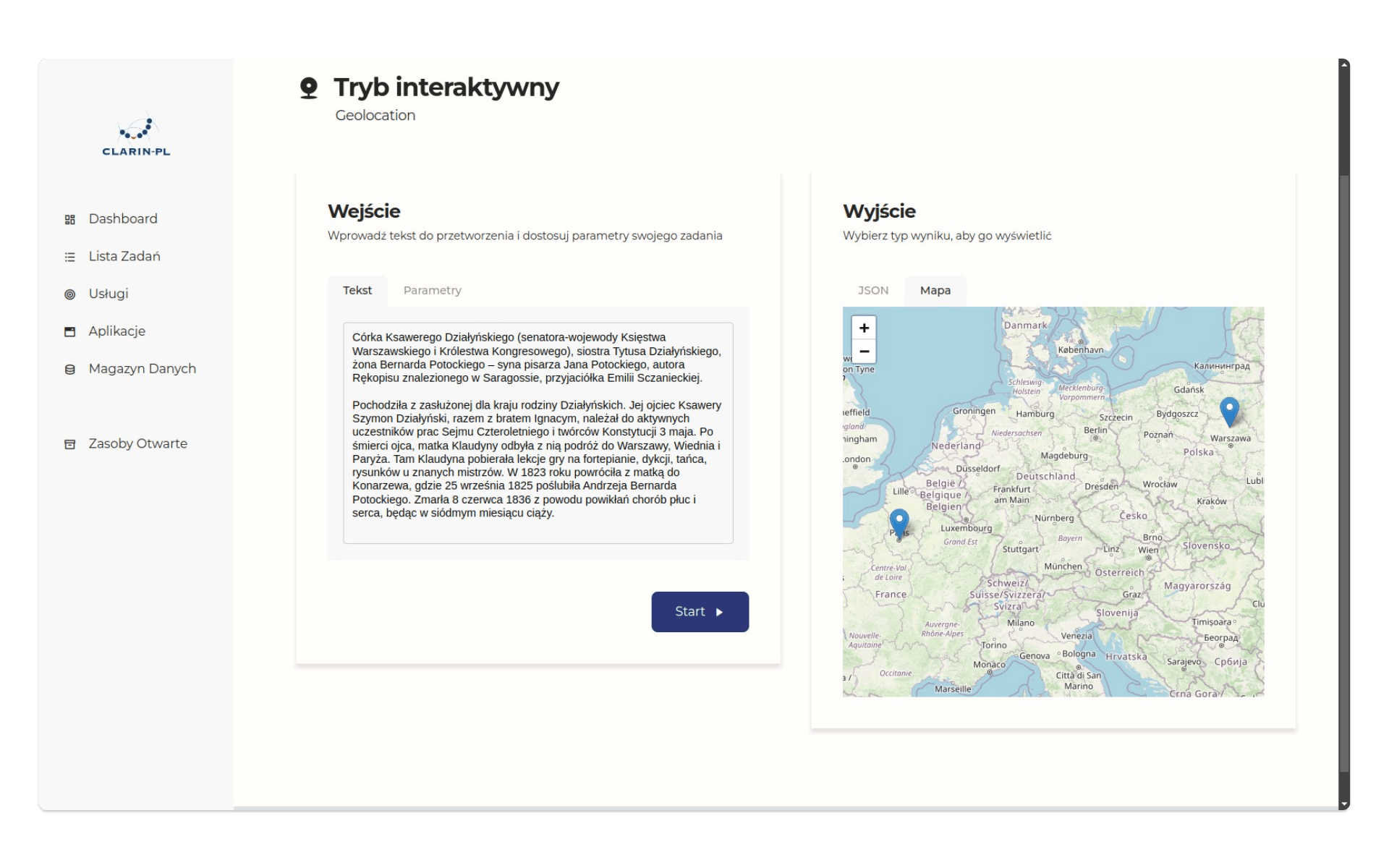
Spróbujmy wypróbować tę usługę w trybie interaktywnym. Do formularza wklejmy następujący tekst, będący fragmentem biogramu Klaudyny Potockiej:
Córka Ksawerego Działyńskiego (senatora-wojewody Księstwa Warszawskiego i Królestwa Kongresowego), siostra Tytusa Działyńskiego, żona Bernarda Potockiego – syna pisarza Jana Potockiego, autora Rękopisu znalezionego w Saragossie, przyjaciółka Emilii Sczanieckiej. Pochodziła z zasłużonej dla kraju rodziny Działyńskich. Jej ojciec Ksawery Szymon Działyński, razem z bratem Ignacym, należał do aktywnych uczestników prac Sejmu Czteroletniego i twórców Konstytucji 3 maja. Po śmierci ojca, matka Klaudyny odbyła z nią podróż do Warszawy, Wiednia i Paryża. Tam Klaudyna pobierała lekcje gry na fortepianie, dykcji, tańca, rysunków u znanych mistrzów. W 1823 roku powróciła z matką do Konarzewa, gdzie 25 września 1825 poślubiła Andrzeja Bernarda Potockiego. Zmarła 8 czerwca 1836 z powodu powikłań chorób płuc i serca, będąc w siódmym miesiącu ciąży. Człowiek bez problemu wyodrębni z niego punkty geograficzne: Warszawa, Wiedeń, Paryż, Konarzewo. Czy uda się nam wyodrębnić je podobnie dokładnie, jeśli użyjemy maszyny? Aby to sprawdzić, klikamy przycisk start:
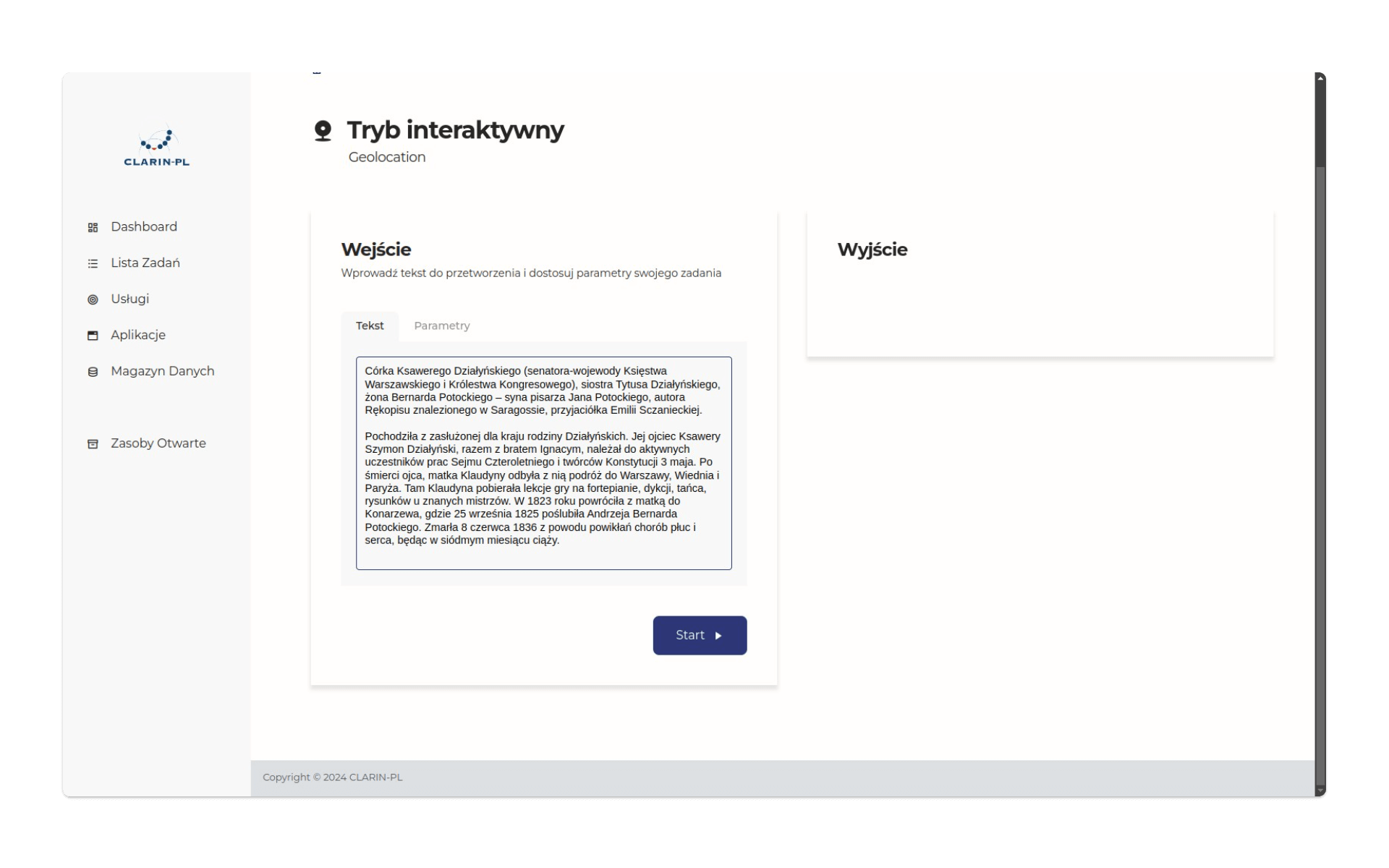
Po chwili otrzymamy dwa rodzaje odpowiedzi: dane w postaci JSON oraz mapę. Dane JSON mają tu dość skomplikowaną strukturę, jednak w kluczu records i następnie geolocation znajdziemy informacje o dwóch obiektach geograficznych:
{
"records": {
"geolocation": [
{
"obj-id": "62d61713-d829-44a5-bd30-ab1c334d2444",
"name": "Paryż, Île-de-France, Francja",
"type": "administrative",
"lat": 48.85881005,
"lon": 2.32003101155031,
"importance": 0.96893459932191
},
{
"obj-id": "4cfff375-b8de-4f70-8773-2f43fffc88de",
"name": "Konarzewo, gmina Gołymin-Ośrodek, powiat ciechanowski, województwo mazowieckie, Polska",
"type": "hamlet",
"lat": 52.8175,
"lon": 20.9225,
"importance": 0.275
}
]
}
}Cóż, nie jest to zbyt imponująca jakość analizy - narzędzie NER nie wykryło Warszawy i Wiednia oraz błędnie zidentyfikowało miejscowość Konarzewo (tu znajdującą się w Wielkopolsce):
Spróbujmy użyć innego NER-u (liner):
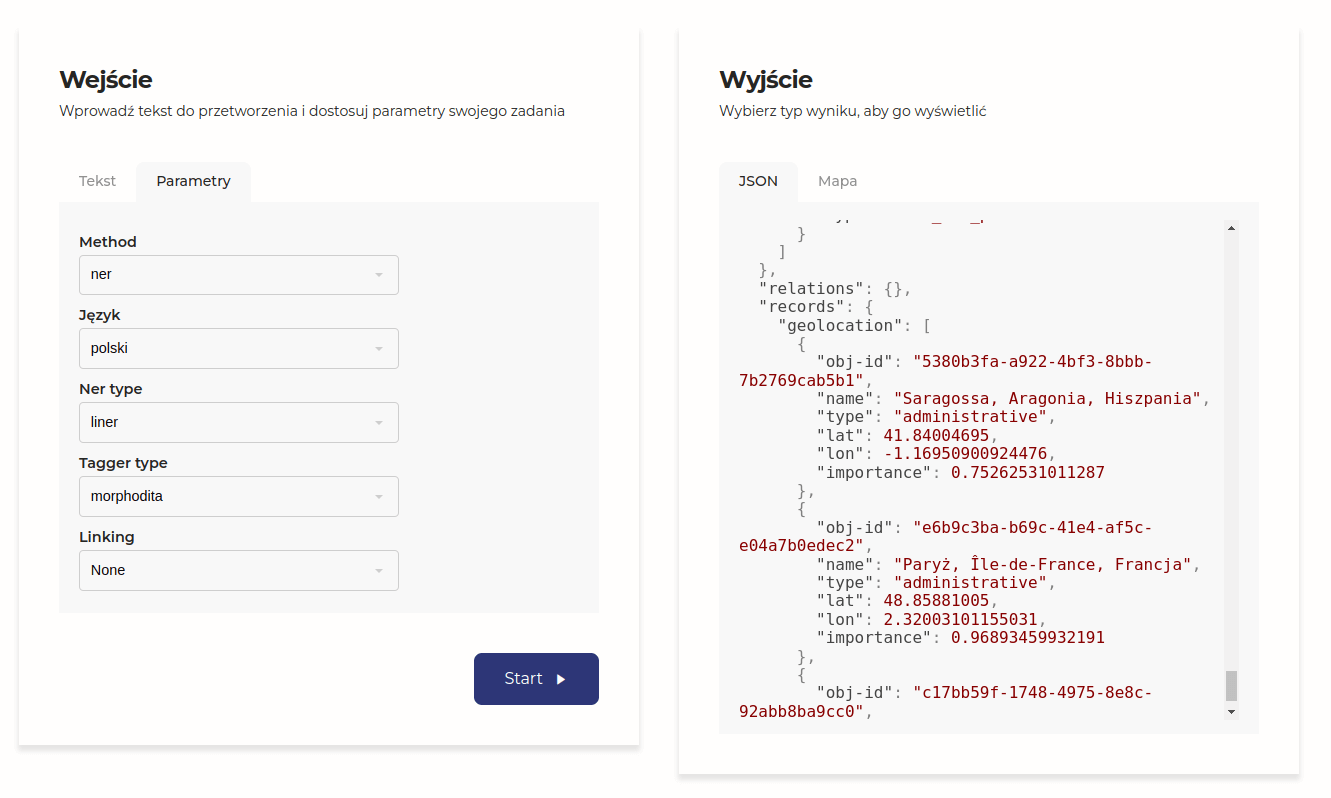
Tutaj także jakość odpowiedzi jest niska. Nie tylko znów nie ma Warszawy i Wiednia, a Konarzewo przypisywane jest do Mazowsza, to jeszcze wyróżniona została Saragossa, ponieważ w biogramie znajduje się fragment:
Córka Ksawerego Działyńskiego (senatora-wojewody Księstwa Warszawskiego i Królestwa Kongresowego), siostra Tytusa Działyńskiego, żona Bernarda Potockiego – syna pisarza Jana Potockiego, autora Rękopisu znalezionego w Saragossie […]
Musimy przywyknąć do tego, że jakość maszynowego rozpoznawania interesujących nas klas słów może nie być wysoka. Zaletą tych metod jest przede wszystkim ich zakres - bardzo szybko możemy przetworzyć duże zbiory tekstów. Spróbujmy zrobić to teraz i umieśćmy nasz plik wikipedia_persons.zip na platformie CLARIN-PL.
W tym celu klikamy w zakładkę Magazyn Danych i wysyłamy do niego nowy korpus.
Masowa analiza tekstów biogramów
Umieszczenie korpusu w Magazynie Danych jest warunkiem przetwarzania w trybie kreatora. Po przejściu na stronę usługi, wybieramy interesujący nas korpus. Możemy też eksperymentować z parametrami przetwarzania:
Klikamy Uruchom. Za kilka chwil będziemy mogli pobrać nasze dane jako plik zip w zakładce Lista Zadań. Dla tekstów o większej objętości lista wyodrębnionych lokalizacji okazała się odpowiednio większa. Przykładowo, dla biogramu Elizy Orzeszkowej wyróżniono 45 lokalizacji (przy czym niektóre wielokrotnie). Oto krótki fragment danych:
[
{
"obj-id": "269c6fc6-b90c-44f7-8a34-a758f3bd1bf5",
"name": "województwo podlaskie, Polska",
"type": "administrative",
"lat": 53.2668455,
"lon": 22.8525787,
"importance": 0.69134395347837
},
{
"obj-id": "e3bd6ca0-b0c2-4b00-81d8-566ee961ecea",
"name": "Grodno, obwód grodzieński, Białoruś",
"type": "city",
"lat": 53.6834599,
"lon": 23.8342648,
"importance": 0.66452669323231
},
{
"obj-id": "e26c9579-bf8f-4439-9625-1823e8d8f410",
"name": "Grodno, obwód grodzieński, Białoruś",
"type": "city",
"lat": 53.6834599,
"lon": 23.8342648,
"importance": 0.66452669323231
},
{
"obj-id": "9dc27d2e-0557-4be5-a8f0-830e576833d3",
"name": "Jungfrau, Lauterbrunnen, Verwaltungskreis Interlaken-Oberhasli, Verwaltungsregion Oberland, Berno, 3801, Szwajcaria",
"type": "peak",
"lat": 46.5367739,
"lon": 7.9625907,
"importance": 0.56328064002702
}
]Zwróćmy uwagę, że NER geolokalizacyjny, udostępniany przez CLARIN, wyróżnia też typy i wagę (importance) wyodrębnionych nazw geograficznych. W powyższym przykładzie z biogramu Orzeszkowej wyznaczył region (województwo), miasto i szczyt górski. W tekście biogramu czytamy, że:
[Orzeszkowa] Zwiedziła wodospad Giessbach i Schynige Platte, podziwiała Jungfrau.
Typy lokalizacji wykorzystać można w analizie, choćby odrzucając te wszystkie, które nie są miejscowościami. Wszystkie przetworzone biogramy dostępne są na GitHub.
Podsumowanie
Narzędzia językowe CLARIN-PL pozwalają nam pracować z tekstami bez programowania. Jednym z zastosowań maszynowego przetwarzania języka naturalnego jest wyodrębnianie jednostek nazwanych (NER), które wydaje się szczególnie użyteczne w pracy z dużymi zbiorami tekstów. Ceną za duży zakres analizy jest niestety jej dokładność - oczywiście pozyskane dane można potem ręcznie sprawdzać i w ten sposób poprawić ich jakość.
Zwróćmy także uwagę, że NER opisał nam punkty geograficzne we współczesnych granicach państw. Jeśli zależałoby nam na odpowiednim oznaczeniu ich w historycznym kontekście, musielibyśmy zmapować wszystkie punkty, dodając np. nowy klucz w JSON - historical_name:
[
{
"obj-id": "e26c9579-bf8f-4439-9625-1823e8d8f410",
"name": "Grodno, obwód grodzieński, Białoruś",
"historical_name": "Grodno, powiat grodzieński, województwo białostockie, Polska (II Rzeczpospolita)",
"type": "city",
"lat": 53.6834599,
"lon": 23.8342648,
"importance": 0.66452669323231
}
]Wykorzystanie metod
Ciekawym przykładem zastosowania NER w badaniach historycznych jest artykuł Event-based Access to Historical Italian War Memoirs (2021), w którym autorzy opisują system automatycznego wykrywania wydarzeń (event extraction) ze treści zdigitalizowanych włoskich pamiętników z okresu II wojny światowej. Dane pozyskane dzięki narzędziom NER są w tym badaniu zestawiane z innymi typami danych wyodrębnionych automatycznie.
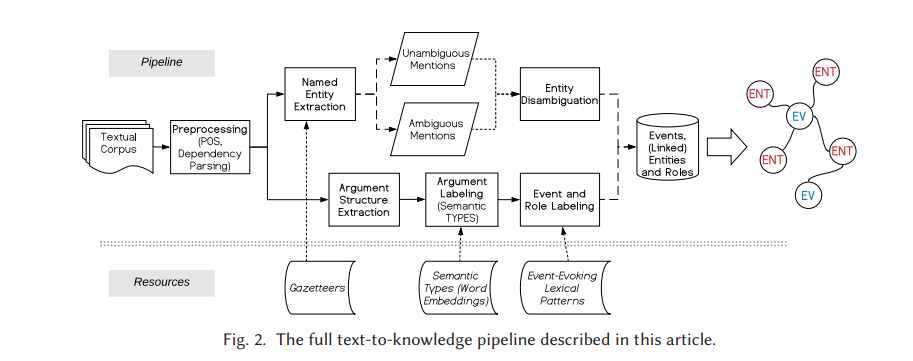
Ostatecznie w maszynowym wykrywaniu wydarzeń interesuje nas nie tylko fakt zaistnienia jakiegoś wydarzenia, ale też aktorzy i obiekty, które są w nie zaangażowani. Przykładowo, autorom opracowania udało się wygenerować graf wydarzeń związanych z postacią Duccio Galimbertiego, włoskiego antyfaszysty, zamordowanego w grudniu 1944 roku:
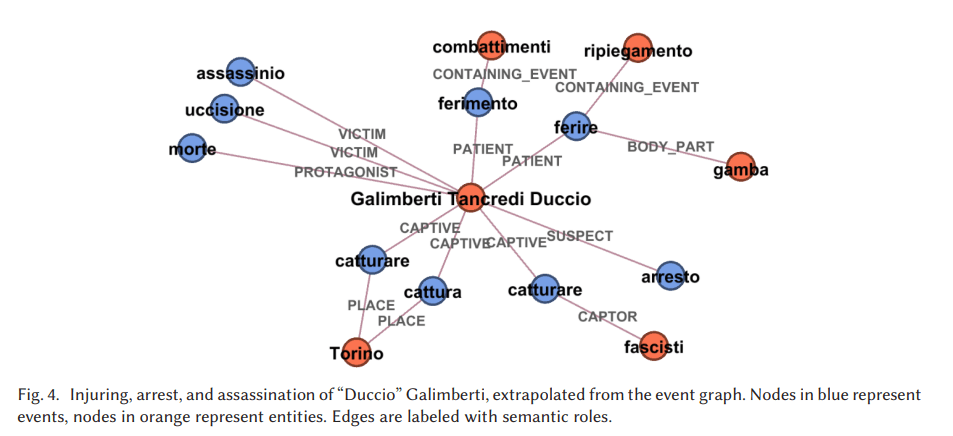
Zwróćmy uwagę, że relacje między wydarzeniami a aktorami i obiektami są opisane za pomocą wybranych typów (miejsce, ofiara, podejrzany itp.).
Pomysł na warsztat
Celem warsztatu może być zbadanie możliwości i ograniczeń maszynowego wyodrębniania nazw geograficznych przez odpowiednie zhakowanie narzędzia do Geolokalizacji, dostępnego na platformie CLARIN-PL. Osoby uczestniczące w warsztacie przygotowywałyby krótkie teksty, w których pojawiłoby się maksymalnie wiele odniesień do nazw geograficznych, przy czym powinny być one podane w taki sposób, żeby ich odczytanie maszynowe było jak najmniej efektywne. W treści ćwiczeniowych tekstów mogą pojawiać się wieloznaczności, miejscowości o tych samych nazwach położone w różnych regionach, nazwy zwyczajowe i miejscowe a także nazwy polskich miejscowości w swoich historycznych wersjach np. w języku niemieckim czy nazwy miejscowości w wariantach kaszubskim lub śląskim. Z powodzeniem próbować można też używać nazw geograficznych w niegeograficznym kontekście, np. w tytułach książek czy filmów lub nazwiskach.


