
Wprowadzenie
Mija dziesięć lat od powstania Europejskiego Centrum Solidarności, muzeum i centrum kultury, umiejscowionego tuż obok historycznej bramy nr 2 Stoczni Gdańskiej. To ważny punkt na muzealnej mapie Gdańska i Polski:
ECS to nowoczesna instytucja kultury prezentująca drogę do wolności Polaków i innych narodów Europy Środkowo-Wschodniej, miejsce kultury i pielęgnowania wartości obywatelskich. Na wiele sposobów zachowujemy w pamięci Polaków i Europejczyków doświadczenie Solidarności jako pokojowej europejskiej rewolucji. Chcemy, aby Solidarność była ważną częścią mitu założycielskiego Europy. Zapraszamy na wystawy, warsztaty edukacyjne i warsztaty rodzinne, debaty, spotkania autorskie, projekcje, festiwale i konferencje. Działają tu SOLIDARNOŚĆ CODZIENNIE – przestrzeń dla aktywistek i aktywistów, WYDZIAŁ ZABAW dla dzieci, biblioteka, archiwum i mediateka. (źródło: ecs.gda.pl)
W ECS uwagę przyciąga nie tylko temat wystawy stałej czy organizowane tu wydarzenia, ale też architektura budynku, nawiązująca do stoczniowego dziedzictwa tej części Gdańska.
Cele lekcji
Celem naszej lekcji będzie poznanie podstaw analizy sentymentu - automatycznego rozpoznawania emocji w tekstach. Pracować będziemy na komentarzach, jakie na temat ECS pozostawiły w systemie Google Maps osoby, które je odwiedziły. Są to więc treści szczególnie wartościowe dla muzeum - zakładamy przecież, że udostępniły je osoby, które naprawdę były na miejscu.
Jak oceniają ekspozycję i przestrzeń muzeum? Jakie budzi w nich emocje? Na co zwracają uwagę? Co psuje im przyjemność zwiedzania? Na te pytania postaramy się odpowiedzieć. Pamiętajmy, że nasze badanie robimy w ramach ćwiczeń i testów, będzie więc z konieczności uproszczone, a wnioski niespecjalnie odkrywcze.
Efekty
Efektem naszej pracy będą dane, opisujące prawdopodobieństwa obecności określonych emocji w komentarzach osób, które zwiedzają Europejskie Centrum Solidarności oraz opisujące prawdopodobny wydźwięk tych komentarzy. Postaramy się zebrać je i porównać ze sobą: jakie emocje dominują podczas wizyty w ECS?
Wymagania
Do pracy z komentarzami z Google Maps potrzebujemy scrapera, który pozwoli nam je automatycznie pozyskać. Skorzystamy, podobnie jak w lekcji poświęconej facebookowym wpisom Muzeum Narodowego w Warszawie, z platformy Apify. Musimy założyć tam darmowe konto (nie trzeba podawać danych płatności). Skorzystamy też z narzędzi językowych konsorcjum CLARIN-PL - tutaj również musimy się zalogować.
Dane z Google Maps pobierzemy w postaci plików CSV, gdzie każdy wiersz zawiera treść i metadane pojedynczego komentarza. Aby skorzystać z narzędzi CLARIN-PL, musimy wyodrębnić te wiersze do osobnych plików. Ponieważ w tej lekcji nie chcemy programować, musimy skorzystać z ChatGPT (w ramach darmowego dostępu do wersji 4.0, która pozwala na upload własnych plików). Używanie ChatGPT wymaga założenia darmowego konta - musimy jednak podać numer telefonu. Osoby, które nie chcą tego robić, mogą skorzystać z przygotowanych już plików, opisanych w dalszej części tej lekcji. Do finalnej analizy danych konieczny będzie dostęp do Google Sheets, Excela czy Open Office Calc.
Część merytoryczna
Twórcom aplikacji Google Maps udało się obudować mapę rozmaitymi narzędziami społecznościowymi - jednym z nich jest dodawanie ocen (komentarzy) do wybranych lokalizacji. W dniu pisania tego tutoriala, ECS skomentowało ponad 8 tys. osób, a średnia ocen wynosi 4.8 - myślę, że to bardzo dobry wynik.
To nie jedyne dane na temat ECS, jakie są agregowane i przetwarzane przez Google na mapie.
Warto myśleć o mapie Google jako bogatym źródle danych na temat instytucji kultury. To nie tylko informacje o adresach, stronach domowych, godzinach otwarcia, ale też np. o ułatwieniach dla osób niepełnosprawnych. Wydaje się, że takie dane mają duży potencjał badawczy, o ile oczywiście zaufamy ich wiarygodności.
Nas interesują jednak przede wszystkim komentarze. Spróbujmy je teraz pobrać, korzystając z Apify.
Wybór aktora i uruchomienie kwerendy
Jeśli używaliśmy już z Apify, pamiętamy, że kluczowy jest wybór aktora - konkretnego scrapera, dostosowanego do platformy i zadania, które chcemy na niej wykonać. Pamiętamy też, że każdy aktor to kod źródłowy, niezbędne biblioteki i konfiguracja, zapisana jako obraz Dockera - dostajemy więc właściwie całe niezbędne środowisko, w którym możemy bezpiecznie i zdalnie uruchomić nasz program. Niczego nie instalujemy i nie programujemy, pracujemy wyłącznie w przeglądarce. Zasoby naszego komputera nie są wykorzystywane do pobierania treści.
Aktorów wybieramy, klikając przycisk Store w lewym bocznym panelu okna aplikacji. Niektóre z tych programów są płatne, inne nie, ale bez względu na to, każde ich użycie wiąże się z wykorzystywaniem określonych zasobów dostępnych w ramach darmowego konta (pamięć RAM i koszt użycia liczony w dolarach). W darmowym pakiecie możemy korzystać z zasobów aplikacji do sumy pięciu dolarów, limit odnawia się co kilka dni.
Aktorem (scraperem), który wykorzystamy, jest Google-Maps-Reviews-Scraper:
This scraper uses a pay-per-result pricing model, making costs easy to calculate: it will cost you $0.50 to scrape 1,000 Google reviews, which comes to $0.0005 per review. With the Apify Free plan, you get $5 free usage credits every month, allowing you to scrape over 10,000 Google reviews for free within those credits.
Znajdujemy aktora o takiej nazwie w sklepie Apify i używamy go w naszym projekcie. Aby rozpocząć zbieranie danych, musimy odpowiednio skonfigurować program - robimy to, wypełniając formularz:
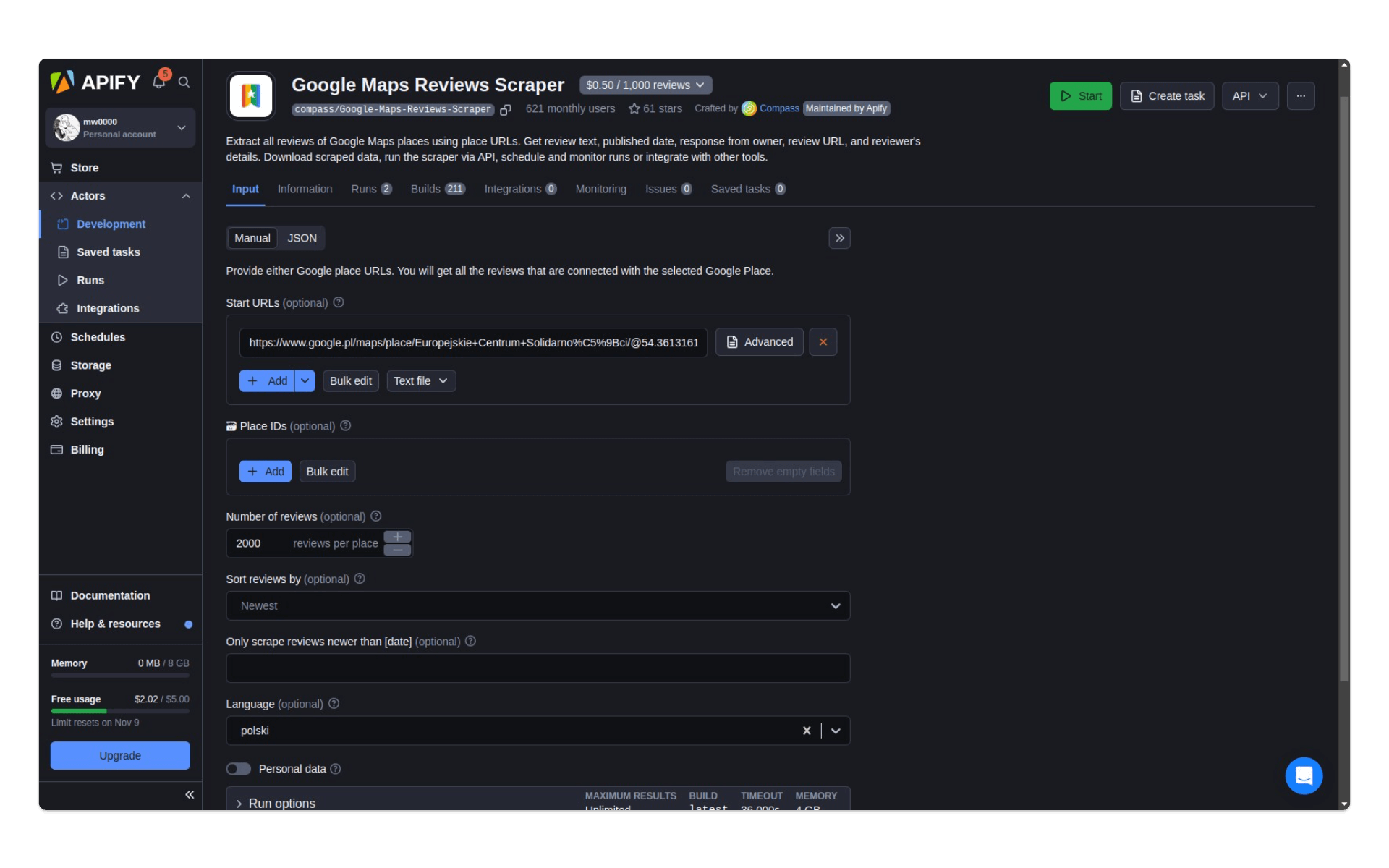
W formularzu podajemy lokalizację obiektu (URL z Google Maps), na temat którego chcemy pobrać opinie. Ustawiamy też oczekiwaną liczbę komentarzy do pobrania oraz, co jest bardzo ważne, decydujemy, czy pozyskane dane zawierać będą dane osobowe - przede wszystkim imię i nazwisko osoby komentującej. Dane te nie są nam do niczego potrzebne, dlatego na dole formularza odznaczamy checkbox podpisany jako Personal data.
Podgląd danych
Dane, które gromadzi Google Maps, mają imponujący zakres. Obok tekstów komentarzy otrzymaliśmy też informacje o ocenach obiektu (w skali 1-5), informacje o czasie dodania opinii czy kontekście wizyty (w kluczu reviewContext). Zwróćmy też uwagę, że Google udostępnia oryginalny tekst komentarzy oraz ich maszynowe tłumaczenie, jeśli zostały napisane w języku innym niż język polski. Mamy też dostęp do adresów zdjęć, którym osoba zwiedzająca ECS zilustrowała swoją ścieżkę zwiedzania (reviewImageUrls):
{
"searchString": "Direct Detail URL: https://www.google.pl/maps/place/Europejskie+Centrum+Solidarno%C5%9Bci/@54.3613161,18.6471651,17z/data=!3m1!4b1!4m6!3m5!1s0x46fd73710d9770f9:0xe2010c5f4e6145ad!8m2!3d54.361313!4d18.64974!16s%2Fg%2F120pnc0n?entry=ttu&g_ep=EgoyMDI0MTAyOS4wIKXMDSoASAFQAw%3D%3D",
"name": null,
"text": "Very impressive and interesting exhibition about an important part of Polish history! The audioguide is a great tool, it’s gonna take you smoothly through the whole story - definitely recommend to ask for it:)",
"textTranslated": "Bardzo imponująca i ciekawa wystawa poświęcona ważnej części historii Polski! Audioprzewodnik to świetne narzędzie, które płynnie poprowadzi Cię przez całą historię - zdecydowanie polecam poprosić o niego :)",
"publishAt": "wczoraj",
"publishedAtDate": "2024-11-02T21:19:20.538Z",
"likesCount": 0,
"reviewId": null,
"reviewUrl": null,
"reviewerId": null,
"reviewerUrl": null,
"reviewerPhotoUrl": null,
"reviewerNumberOfReviews": 1,
"isLocalGuide": false,
"reviewOrigin": "Google",
"stars": 5,
"rating": null,
"responseFromOwnerDate": null,
"responseFromOwnerText": null,
"reviewImageUrls": [
"https://lh5.googleusercontent.com/p/AF1QipPssr8YGUH5Omx9T0oeIOItYwauhTnV0YtMxY8M=w1920-h1080-k-no-p",
"https://lh5.googleusercontent.com/p/AF1QipOV6zF0J_GG0Q8bcvY0AL2zM7pAjhOVPqwVkH_0=w1920-h1080-k-no-p",
"https://lh5.googleusercontent.com/p/AF1QipMU3-fMWJozFvWoU_PvwtYi55thS2bKBPTxUNzI=w1920-h1080-k-no-p",
"https://lh5.googleusercontent.com/p/AF1QipPYCsy4n-na_CpNr0SKbYEmVaasdXjk1-9cflfI=w1920-h1080-k-no-p",
"https://lh5.googleusercontent.com/p/AF1QipOmv2JpfNPcatguvuNSzIUCZ9ZytL3KrZJ6Sdo1=w1920-h1080-k-no-p",
"https://lh5.googleusercontent.com/p/AF1QipNaq9ssufr7lxoyFxZBpuBzbK2rQRnLOvIzQI5e=w1920-h1080-k-no-p"
],
"reviewContext": {
"Data wizyty": "Weekend",
"Czas oczekiwania": "Nie trzeba było czekać",
"Zalecana rezerwacja": "Nie"
},
"reviewDetailedRating": {},
"isAdvertisement": false,
"placeId": "ChIJ-XCXDXFz_UYRrUVhTl8MAeI",
"location": {
"lat": 54.361313,
"lng": 18.64974
}
}Zajmujemy się recenzjami, więc interesować nas będą treści w kluczach / kolumnach text oraz textTranslated. Wszystkie dane, z których korzystamy w tym ćwiczeniu, dostępne są równolegle na GitHubie.
Pozyskane przez aktora dane pojawią się w naszym magazynie danych, dostępnym w zakładce Storage. Pamiętajmy, żeby nadać temu zestawowi wybraną nazwę, inaczej Apify usunie go w ciągu kilku dni.
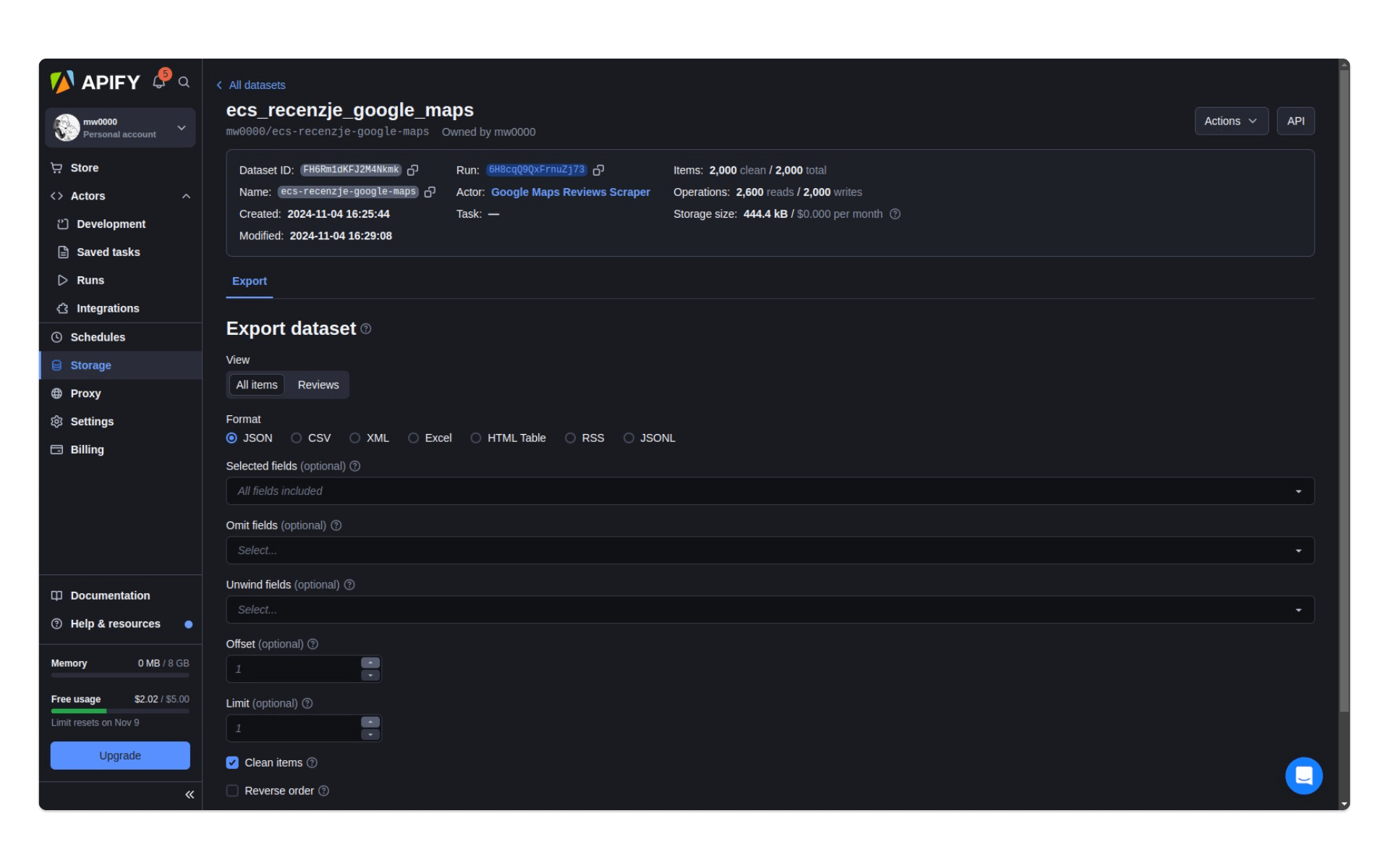
Możemy wybrać format danych (JSON, CSV, Excel a nawet tabelę HTML) oraz eksportować wyłącznie wybrane kolumny. Dzięki temu powinniśmy mieć na dysku pliki z treścią oryginalnych i tłumaczonych opinii - nazwijmy je ecs_reviews_text.csv i ecs_reviews_text_translated.csv. Niech nasze pliki nie zawierają nazw kolumn (nagłówków).
Dzielenie plików CSV z ChatGPT
Przeglądarkowe narzędzia CLARIN-PL nie bardzo radzą sobie z dużymi plikami pełnymi treści - a takie są przygotowane przez nas pliki. Musimy przetworzyć je tak, aby mogły zostać użyte w aplikacjach językowych. Założyliśmy na początku lekcji, że nie będziemy programować, musimy więc znaleźć inny sposób na to, aby każdy wiersz ecs_reviews_text.csv i ecs_reviews_text_translated.csv przekształcić na osobny plik.
Z pomocą przychodzi ChatGPT. ChatGPT korzysta z języka Python do pracy z danymi i tekstami. Zamiast kodować, możemy zaprogramować w języku naturalnym określone zadanie, przygotowując odpowiedni prompt. Rozwiązanie to będzie skuteczne, jednak tylko jeśli korzystamy z ChatGPT 4.0 - konieczna jest możliwość uploadu własnych plików. Na szczęście ChatGPT 4.0 dostępny jest nawet w ramach konta darmowego (jednak wówczas tymczasowo i z niewielkimi limitami zapytań).
Możemy użyć następujący prompt:
Podziel podany plik CSV tak, aby powstaly pojedyncze pliki zawierajace po jednym wierszu. Te pliki mają mieć nazwy zawierające oryginalny numer wiersza. Udostępnij wszystkie jako plik zip. Ten plik źródłowy CSV nie ma nagłówka. Nie przetwarzaj pustych wierszy.W odpowiedzi ChatGPT poprawnie przetworzy pliki csv, jednak zgubi kolejność numeracji wierszy / plików (kazaliśmy mu ominąć puste wiersze). Warto wziąć to pod uwagę, jeśli zależałoby nam na łączeniu danych - informacji o nacechowaniu emocjonalnym komentarza np. z informacją o tym, ile gwiazdek (w skali 1-5) do niego przypisano.
Niech nasze pliki nazywają się text_split_rows.zip i text_translated_split_rows.zip. Pliki dostępne są też na GitHub dla wszystkich, którzy korzystając z tej lekcji chcieliby uniknąć logowania się w aplikacji ChatGPT.
Możemy teraz wysłać pozyskane przez nas treści komentarzy do narzędzi językowych CLARIN-PL. Skoncentrujmy się na zawartości archiwum text_translated_split_rows.zip - to komentarze, które zostały dodane w języku innym niż polski i zostały automatycznie przetłumaczone przez Google. Analizując je, będziemy w stanie zbadać, jak turyści spoza Polski oceniają Europejskie Centrum Solidarności.
Analiza sentymentu - jak to zrobić?
Wybierzmy jeden z przetłumaczonych komentarzy - znajdujący się w pliku row_24.csv:
Najlepsze muzeum jakie do tej pory odwiedziłem. Sam budynek jest imponująco pięknie zbudowany z zewnątrz, a zwłaszcza od wewnątrz! Wystawa ma charakter wyjątkowo pouczający i ekscytujący, jest mieszanką dokumentów, filmów i plansz! Każdy, kto interesuje się historią Polski, a zwłaszcza Solidarnością, jest tutaj w dobrych rękach! Audioprzewodnik działa doskonale, a potem możesz zostawić osobistą wiadomość na ścianie. W stronę ulicy mijamy starą bramę fabryczną Stoczni Lenina, wieża bramna zachowała się do dziś w swojej pierwotnej formie!Zostawmy na boku jakość tego automatycznego tłumaczenia (wieża bramna), skoncentrujmy się na emocjach, które charakteryzują ten tekst (analizujemy tekst a nie poszczególne zdania). Co to za emocje? Moglibyśmy pewnie wyróżnić takie emocje jak:
radość, zainteresowanie, ekscytacja, doświadczenie autentyczności, ciekawość, impresjaOczywiście taki zestaw jest całkowicie zależy od analizy osoby czytającej ten tekst, co więcej, możemy nawet myśleć o tych samych emocjach, ale nazywać je w różny sposób. Żeby rozpoznawać emocje maszynowo, czyli wykonać to, co określa się jako analizę sentymentu, musimy poruszać się w pewnej skali. Po pierwsze, musimy mieć raczej zamkniętą listę nazw emocji (kategorii), aby móc je ze sobą zestawiać i badać statystycznie. Po drugie, musimy zastanowić się, czy te emocje rozpoznajemy binarnie, np. ciekawość jest (1) albo nie jest (0) wyrażona w tekście, czy możeby badać różne prawdopodobieństwa, np. ciekawość - 40 proc., radość - 13 proc. itp.
W narzędziach CLARIN-PL w analizie wydźwięku emocjonalnego tekstów stosowany jest model Plutchika - kategorie (nazwy) emocji zostały więc wyznaczone na podstawie pracy naukowej. Emotagger, z którego będziemy teraz korzystać,
Pozwala analizować dane wejściowe na poziomie całego tekstu, poszczególnych akapitów lub zdań. Uwzględnia osiem kategorii emocji z modelu Plutchika (radość, zaufanie, ciekawość, zaskoczenie, strach, smutek, wstręt i złość) oraz trzy kategorie wydźwięku: pozytywny, negatywny, neutralny. Wynikiem usługi jest stopień pewności modelu dla każdej kategorii będący wartością z przedziału od 0 do 1. Stopień pewności bliższy wartości 1 oznacza, że dana emocja jest wyrażona w analizowanym fragmencie tekstu.
Po zalogowaniu się w platformie CLARIN-PL przejdźmy do strony narzędzia - do trybu interaktywnego. Pozwoli to nam przetestować jego działanie i zapoznać się z formą odpowiedzi. Wklejamy do formularza zacytowany wyżej komentarz i klikamy Start. Program zadziała w ustawieniach standardowych - analizowany będzie wydźwięk całego tekstu:
Narzędzie automatycznie wyliczyło skalę pewności dla zamkniętego katalogu emocji i zaproponowało ogólną interpretację wydźwięku:
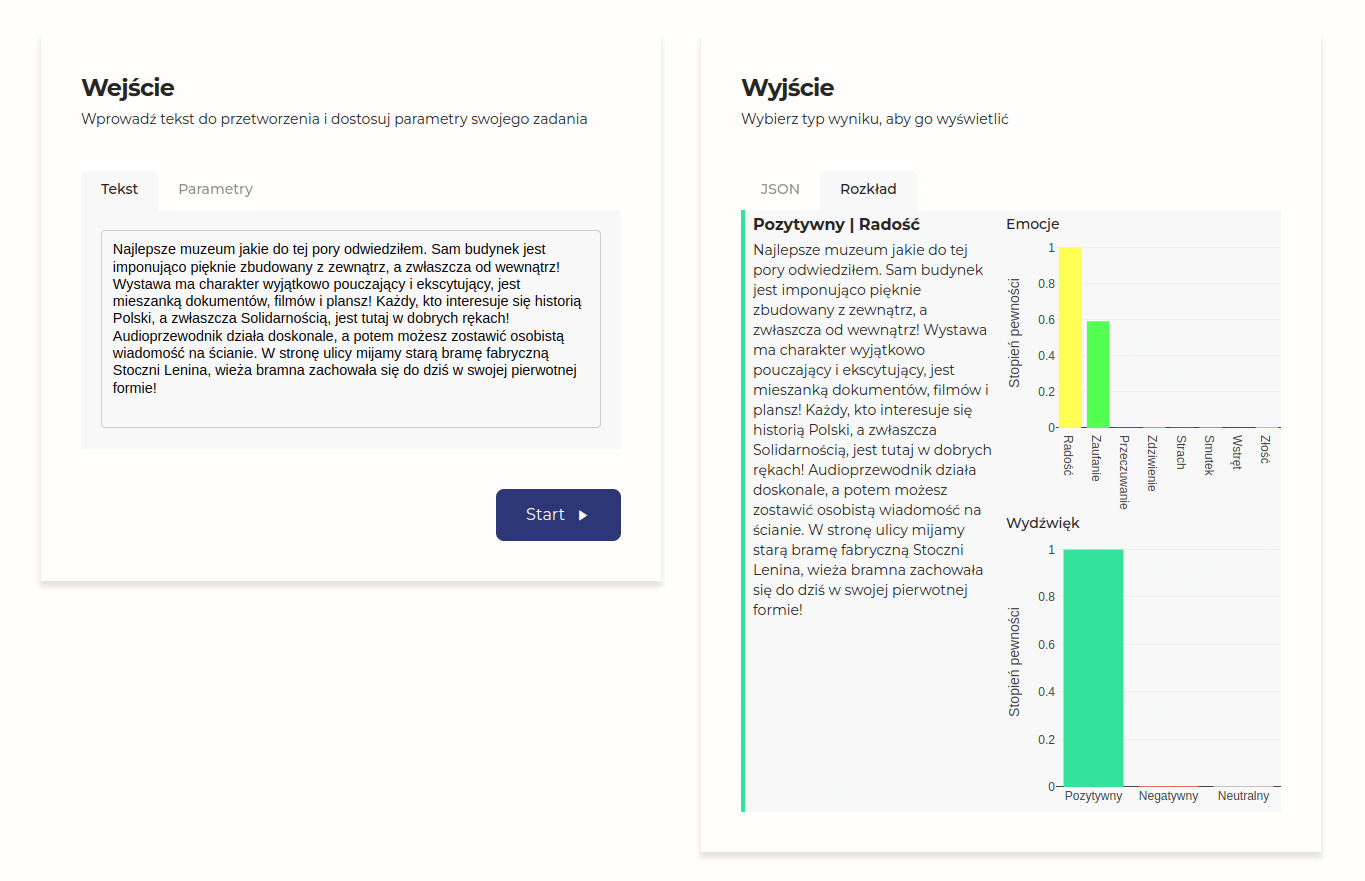
Analiza sentymentu - czy mamy pewność?
Wiedza ta w maszynowej postaci może być przedstawiona w postaci danych JSON:
{
"text": "Najlepsze muzeum jakie do tej pory odwiedziłem. Sam budynek jest imponująco pięknie zbudowany z zewnątrz, a zwłaszcza od wewnątrz! Wystawa ma charakter wyjątkowo pouczający i ekscytujący, jest mieszanką dokumentów, filmów i plansz! Każdy, kto interesuje się historią Polski, a zwłaszcza Solidarnością, jest tutaj w dobrych rękach! Audioprzewodnik działa doskonale, a potem możesz zostawić osobistą wiadomość na ścianie. W stronę ulicy mijamy starą bramę fabryczną Stoczni Lenina, wieża bramna zachowała się do dziś w swojej pierwotnej formie!\n",
"joy": 0.9999872446060181,
"trust": 0.5912981033325195,
"anticipation": 0.0007495625177398324,
"surprise": 0.0003001787408720702,
"fear": 0.00019326567417010665,
"sadness": 0.0002534256491344422,
"disgust": 0.0001839000906329602,
"anger": 0.00013662288256455213,
"positive": 0.9999749660491943,
"negative": 0.00009907654748531058,
"neutral": 0.00008507283200742677
}W takiej właśnie postaci otrzymamy dane o wydźwięku wszystkich analizowanych przez nas komentarzy. Wartości zbliżające się do 1 sugerują większe prawdopodobieństwo występowania określonych emocji. W przypadku naszego komentarza, emocjami dominującymi mają być radość i zaufanie, nie ma też tam mowy o strachu czy gniewie.
Powinniśmy przyzwyczaić się do tego, że efektem analizy maszynowej może być wiedza w różnej postaci. Przykładowo, analizując zbiory cyfrowe muzeum, możemy:
- badać, czy na obrazach znajdują się wizerunki ludzkich twarzy czy nie (wyniki w postaci binarnej, prawdopodobieństwo 100 proc. lub 0 proc., lub w postaci określonego prawdopodobieństwa),
- badać, jakie obiekty znajdują się na obrazach (wyniki w postaci przybliżeń dla zamkniętego katalogu obiektów, analiza jakościowa),
- badać, ile obrazów ma układ portretowy a ile horyzontalny (wyniki w postaci liczb naturalnych opisujących liczebność określonych zbiorów).
Niestety, kosztem tego, że badamy naprawdę duże zbiory treści (distant reading), jest to, że musimy zrezygnować z indywidualnej, bezpośredniej analizy każdego obiektu (close reading) i zamiast bazować na własnym doświadczeniu i zdolności do interpretacji, część naszych kompetencji - jako badacza i badaczki - musimy oddać maszynie. Stąd tak ważne jest cytowanie oprogramowania w pracach naukowych - musimy udostępnić czytelnikom pełną wiedzę na temat podstaw, na jakich działa wykorzystywany przez nas program.
Oczywiście nie oznacza to, że nie powinniśmy starać się zrozumieć przynajmniej podstawowych zasad działania tego oprogramowania. Jak pisze Banjamin M. Schmidt w tekście Do Digital Humanists Need to Understand Algorithms? (2016):
Fundamentalna złożoność komputerów sprawia, że pewien stopień niewiedzy jest nieunikniony. Po przekroczeniu pewnego poziomu, humaniści z pewnością nie muszą rozumieć algorytmów generujących wyniki, z których następnie korzystają; biorąc pod uwagę złożoność współczesnego oprogramowania, jest mało prawdopodobne, by mogli to zrobić. Mimo wszystko, chociaż istnieją aspekty oprogramowania, które możemy bezpiecznie ignorować, pewne podstawowe standardy zrozumienia są konieczne, aby analiza danych humanistycznych była działalnością naukową, a nie jedynie techniczną.
Jeśli nasza praca bazuje na Emotaggerze, cytujmy artykuł CLARIN-Emo: Training Emotion Recognition Models Using Human Annotation and ChatGPT (2023).
Emotagger - przetwarzanie korpusu
Przejdźmy teraz na stronę Magazynu Danych w aplikacji CLARIN-PL - tutaj udostępnimy jako korpus plik text_translated_split_rows.zip:
Dzięki temu możemy używać naszych treści swobodnie w wybranych narzędziach językowych. Wróćmy na stronę Emotaggera i wybierzmy tryb kreatora. Zaznaczmy wybrany plik zip z treściami komentarzy i wybierzmy opcję analizy całego tekstu.
Uruchamiamy zadanie i po chwili możemy pobrać archiwum zip, zawierający plik Excela - emotagger_stats.xlsx (plik dostępny jest też na GitHub). Znajdziemy w nim statystyki opisujące emocje rozpoznane w tekstach naszych komentarzy. Nagłówki wynikowej tabeli to:
filename, chunk id, text, joy, trust, anticipation, surprise, fear, sadness, disgust, anger, positive, negative, neutralZaimportujmy plik do Google Sheets albo Excela i zacznijmy pracę nad interpretacją danych.
Próba interpretacji
Zależy nam, żeby uchwycić wszystkie komentarze jako całość i odpowiedzieć na pytanie, jaki jest ogólny wydźwięk opinii zagranicznych turystów na temat Europejskiego Centrum Solidarności i jakie emocje u nich wzbudza to muzeum.
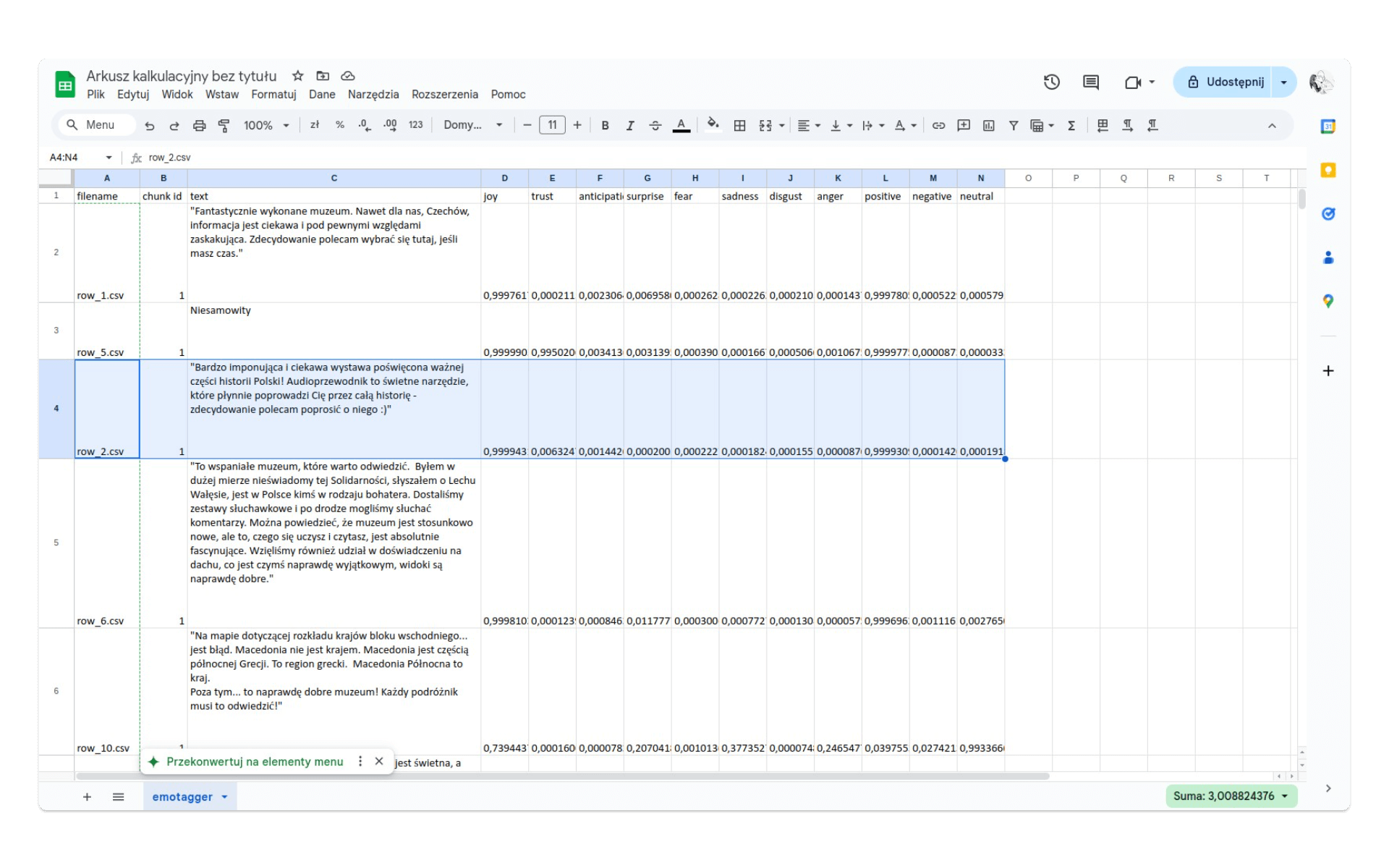
W tym celu wyliczmy średnią procentową z każdej kolumny opisującej prawdopodobieństwa emocji i wydźwięku w tekście. Można to łatwo zrobić, zaznaczając wartości wybranej kolumny i z menu Wstaw wybrać opcję Funkcja i AVERAGE - następnie warto skopiować tę funkcję do kolejnych kolumn, tak aby wygenerowała średnie procentowe dla każdej emocji i każdego wydźwięku:

Mając już te dane, wygenerujmy wykres kolumnowy (zaznaczamy wszystkie komórki z nagłówkami i wartościami opisującymi emocje i wybieramy z menu Wstaw opcję Wykres). Przed wygenerowaniem wykresu możemy zaokrąglić wartości procentowe:
emotion,average percentage
joy,92.5
trust,18.7
anticipation,2.5
surprise,5.9
fear,0.5
sadness,19.8
disgust,1.0
anger,3.3Wykres kolumnowy będzie bardziej poprawny niż kołowy, ponieważ nie będziemy sugerować, że wartości procentowe każdej emocji sumują się do 100 proc.

Wykres właściwie nie jest nam potrzebny (nawet nie wygląda najładniej 🥲). Interpretacja wydaje się łatwa: dominującą emocją, która wypływa z komentarzy zagranicznych turystów odwiedzający ECS, jest radość. To radość i zaufanie tworzą bardzo pozytywny wydźwięk komentarzy (91 proc.!). Obok pozytywnych emocji pojawia się jednak smutek - około 10 proc. komentarzy zawiera opis jakichś negatywnych doświadczeń związanych z wizytą w muzeum. Zagraniczni zwiedzający ECS wyraźnie się nie nudzą, brakuje opinii neutralnych, nic ich też radykalnie nie odrzuca.
Co można zrobić z takimi danymi? Zespół mógłby automatycznie wyznaczyć komentarze, dla których wyznaczono wysoki poziom emocji smutku i zanalizować je. Co można poprawić w organizacji ekspozycji, systemie sprzedaży biletów, dostępności miejsc parkingowych czy przestrzeni dla dzieci? Jeśli zaś badamy instytucje kultury, dane o emocjach, jakie wzbuda przebywanie w ich przestrzeniach, mogą być ciekawie odniesione do tematyki muzeum. Jakie emocje generować będzie wizyta w ECS, jakie w Muzeum II Wojny Światowej, a jakie w Muzeum Powstania Warszawskiego?
Podsumowanie
Udało nam się pobrać treści i metadane komentarzy z Google Maps i zbadać ich nacechowanie emocjonalne. Nie korzystaliśmy z programowania, a jedyną część zadania, która naprawdę go wymagała, obeszliśmy, programując w języku naturalnym w ChatGPT.
Doświadczenie pracy z danymi Google Maps pokazuje, jak wiele informacji o nas zbiera Google. Pobierając komentarze, wybierając odpowiednią opcję scrapera Apify, zrezygnowaliśmy z pozyskiwania danych osobowych - ochrona prywatności to ważny wątek w pracy z danymi platform społecznościowych. W razie potrzeby anonimizacji zbiorów danych, możemy skorzystać z narzędzia CLARIN-PL - Anonymizer:
Zanonimizowane dane nie podlegają pod RODO i nie stwarzają innych zagrożeń dla prywatności – dzięki temu można je archiwizować bez ryzyka i swobodnie przekazywać je między działami lub do firm zewnętrznych bez stosowania umów powierzeniowych. Anonimizer posiada trzy tryby: trwałe usunięcie danych wrażliwych, tymczasowe podstawienie tagów cenzurujących wrażliwe dane, a także tymczasowe zastąpienie prawdziwych danych sztucznymi.
Wykorzystanie metod
Komentarze z Google Maps to cenne źródło wiedzy dla instytucji kultury, miejsc dziedzictwa kulturowego czy nawet całych miast, rozumianych jako przestrzenie turystyczne. Można włączyć te dane do badań nad publicznością i analizować za ich pomocą odbiór poszczególnych elementów ekspozycji czy użyteczność wybranych przestrzeni.
Ciekawym przykładem badania z wykorzystaniem takich danych jest analiza ponad 1 tys. recenzji (określanych tu jako Online Travellers Reviews (OTRs)), którymi w latach 2016-2023 turyści oceniali portugalskie Aveiro i hiszpańską A Coruñę pod kątem dostępności. W artykule Perceived image of accessible tourism destinations: a data mining analysis of Google Maps reviews (2023)
Wykorzystano metody analizy treści i eksploracji tekstu za pomocą oprogramowania RapidMiner. Wyniki ujawniają korelację między warunkami dostępu a satysfakcją odwiedzających. Do najczęściej zgłaszanych przez podróżnych problemów należą dostępność miejsc parkingowych i ułatwienia dla osób niepełnosprawnych. Poprawy wymagają takie obszary jak udostępnianie informacji i oznakowanie przestrzeni.
Badanie obejmowało m.in. automatyczną kategoryzację komentarzy i analizę sentymentu.
Pomysł na warsztat
Warsztat może dotyczyć podstaw analizy sentymentu i można przeprowadzić go bez programowania i komputerów (wystarczy komputer osoby prowadzącej). Uczestników i uczestniczki warsztatów dzielimy na grupy - każda z nich przygotować ma krótki, kilkuzdaniowy komentarz o określonym nacechowaniu emocjonalnym i wyrażający określone emocje. Następnie analizujemy wspólnie te teksty za pomocą Emotaggera, działającego w trybie interaktywnym. Podstawą pracy warsztatowej jest porównanie tego, jak w języku naturalnym subiektywnie wyrażamy emocje z tym, jak maszynowa analiza emocji spłaszcza je do wymiaru kilku podstawowych emocji w modelu Plutchika.
Kolejną częścią warsztatu jest już próba shackowania Emotaggera, czyli takiego przygotowania treści komentarza, który sprawi, że automatyczne rozpoznanie emocji okaże się całkowicie błędne. Można użyć ironii, metafor, idiomatyczności, eufemizmów, sarkazmu i rozmaitych aluzji i odniesień do kultury. Narzędzia do maszynowej analizy sentymentu są wartościowe i potrzebne, ale warto wiedzieć, jakie mają słabe strony i jak bardzo trudno przetworzyć kulturę języka na dane.


