
Wprowadzenie
Google Ngram Viewer to narzędzie zbudowane na podstawie ogromnego zbioru zdigitalizowanych i OCR-owanych książek, pozwalające na analizowanie częstości występowania wybranych słów i fraz w czasie. Udostępnione w 2010 roku, wciąż wykorzystywane jest w badaniach językowych, literackich, historycznych i kulturowych.
W 2004 roku firma Google zaczęła projekt masowego skanowania książek - do 2010 roku zeskanowano ponad 15 mln publikacji, jak się szacuje - około 11 proc. wszystkich książek opublikowanych drukiem od XV w. (pierwsza publikacja w Google Books pochodziła z 1473 roku), pisanych w 478 językach. Z tej puli w 2010 roku wybrano ponad 5 mln tytułów, które poddano procesowi OCR (rozpoznawanie tekstu ze skanów) i z których wygenerowano korpus. Ostatnia aktualizacja danych w Google Ngram Viewer miała miejsce w 2020 roku.
Podstawy Google Ngram Viewer wyjaśnia schemat zamieszczony w publikacji Quantitative Analysis of Culture Using Millions of Digitized Books (2010):
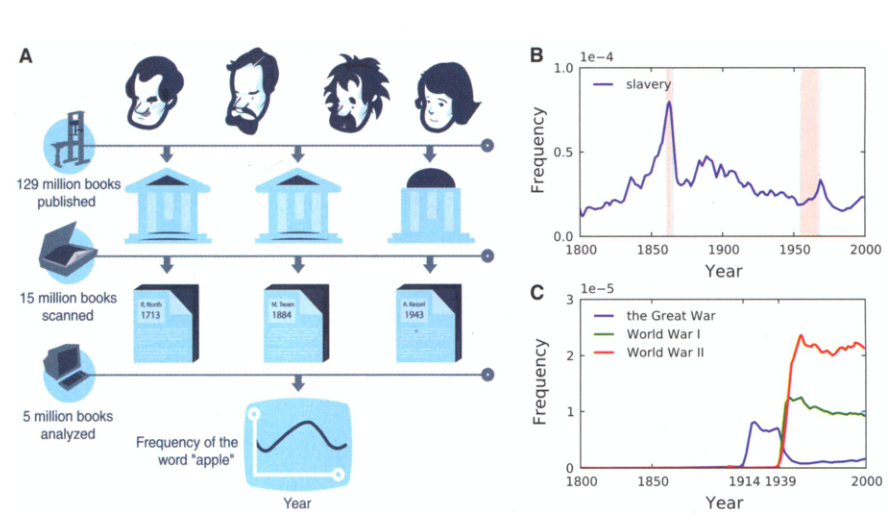
Google Ngram Viewer - jak sama nazwa wskazuje - pozwala przeglądać nie tylko pojedyncze słowa, ale zbitki słów. W Google Ngram Viewer n-gramy to sekwencje kolejnych n słów, np. bigram to sekwencja dwóch słów (“dziedzictwo kulturowe”), trigram - trzech (“cyfrowe dziedzictwo kulturowe”) itd.
Cele lekcji
Celem lekcji jest przedstawienie podstawowych metod pracy z Google Ngram Viewer, w tym podstaw interpretowania wyników. Dostępność tego narzędzia i łatwość generowania wykresów częstości określonych słów i fraz powoduje, że łatwo zapomnieć o ograniczeniach wynikających nie tylko z jakości danych wejściowych Google Ngram Viewer, ale też o wadach analiz języka, kultury i historii, opierających się przede wszystkim na danych ilościowych.
Efekty
Dzięki lekcji będziemy w stanie odpowiednio krytycznie interpretować dane udostępniane przez Google Ngram Viewer oraz lepiej przygotowywać własne analizy z wykorzystaniem tego narzędzia.
Wymagania
W tej lekcji korzystać będziemy wyłącznie z przeglądarki internetowej.
Część merytoryczna
Około 2010 roku Google Ngram Viewer był prawdziwą obietnicą rewolucji w humanistyce. Oto digitalizacja na prawdziwie globalną skalę umożliwiła każdemu przeszukiwania milionów książek i generowanie statystyk na temat tego, jak popularne w wybranym okresie były dowolne słowa.
Obietnice kulturomiki
Analiza komputerowa tego korpusu pozwala nam obserwować trendy kulturowe i poddawać je ilościowym badaniom. “Kulturomika” poszerza granice naukowego badania o szeroki zakres nowych zjawisk
— pisali autorzy i autorki opracowania opublikowanego wraz z Google Ngram Viewer. Zaproponowano nawet nowe pojęcie kulturomika (culturomics):
Kulturomika to wykorzystanie gromadzenia i analizowania dużych ilości danych do badania kultury. Książki to dopiero początek, powinniśmy uwzględnić też gazety, rękopisy, mapy, dzieła sztuki i wiele innych ludzkich wytworów. Oczywiście wiele głosów - już utraconych - pozostanie na zawsze poza naszym zasięgiem. Wyniki badań kulturomicznych są nowym rodzajem dowodu w naukach humanistycznych. Podobnie jak skamieniałości starożytnych stworzeń, wyzwaniem kulturomiki jest interpretacja tych dowodów.
U podstaw nowego zwrotu w humanistyce leżeć miała szeroka dostępność zdigitalizowanych zasobów kultury i dziedzictwa oraz łatwość ich przeszukiwania - także w celach statystycznych. Dwa lata przed uruchomieniem Google Ngram Viewer, Chris Anderson, dziennikarz magazynu “Wired”, znany ze swojego bardzo optymistycznego podejścia do nowych rozwiązań technologicznych, przekonywał nawet, że dostęp do ogromnych zbiorów danych może sprawiać, że teoretyzowanie przestanie mieć sens:
Nasza zdolność do przechwytywania, magazynowania i rozumienia ogromnych ilości danych zmienia naukę, medycynę, biznes i technologię. W miarę rosnącego zbioru faktów i liczb, wzrośnie także możliwość znalezienia odpowiedzi na fundamentalne pytania.
Zdaniem Andersona metoda naukowa oparta na hipotezach przechodziła do historii - modele, teorie i przybliżenia nie są potrzebne, kiedy możemy tak łatwo sięgnąć po bezpośrednie dane. Przykładowo, zamiast SZACOWAĆ, o czym pisano w XV w., dzięki masowym programom skanowania i OCR-owania książek, będziemy mogli kiedyś pokazać statystykę wszystkich słów i tematów ze wszystkich książek i WIEDZIEĆ, o czym pisano przed setkami lat. To zdecydowanie Duża Obietnica dla humanistyki, mającej być może jakiś kompleks wobec nauk empirycznych.
To oczywiście nie jest tak, że statystyka nie ma żadnej wartości w badaniach nad kulturą:
Jeśli jedno zjawisko występuje częściej niż inne, zakładamy, że ma to “jakieś znaczenie”
piszą autorzy krytycznego opracowania na temat Google Ngram Viewer - The impact of lacking metadata for the measurement of cultural and linguistic change using the Google Ngram data sets—Reconstructing the composition of the German corpus in times of WWII (2017) (artykuł dostępny jest też w SciHub). Jeśli mamy w danych informacje o tym, że w określonym czasie spada sprzedaż kapeluszy, możemy wnioskować, że ma to związek ze zmianiającą się modą. Podobnie spadek liczebności rasistowskich określeń w prasie codziennej sugeruje pewne zmiany społeczne.
Praca z procentami
Spróbujmy sprawdzić to na konkretnym przykładzie. Wchodzimy na stronę Google Ngram Viewer i w pole wyszukiwania wpisujemy socrealism. Korzystamy ze słowa kluczowego po angielsku, bo w Google Ngram Viewer nie znajdziemy korpusu książek w języku polskim - to już pierwsze poważne ograniczenie tego narzędzia. Jeśli chcemy w ten sposób badać język polski, możemy skorzystać z Narodowego Korpusu Języka Polskiego, którego ostatnią wersję opublikowano w 2012 roku…
Wróćmy jednak do Google Ngram Viewer. Spodziewamy się, że pojęcie ‘socrealizm’ pojawi się w korpusie nie wcześniej niż w XX wieku, więc ograniczmy zakres analizy do lat 1900-2019 - użyjemy korpusu English (2019).
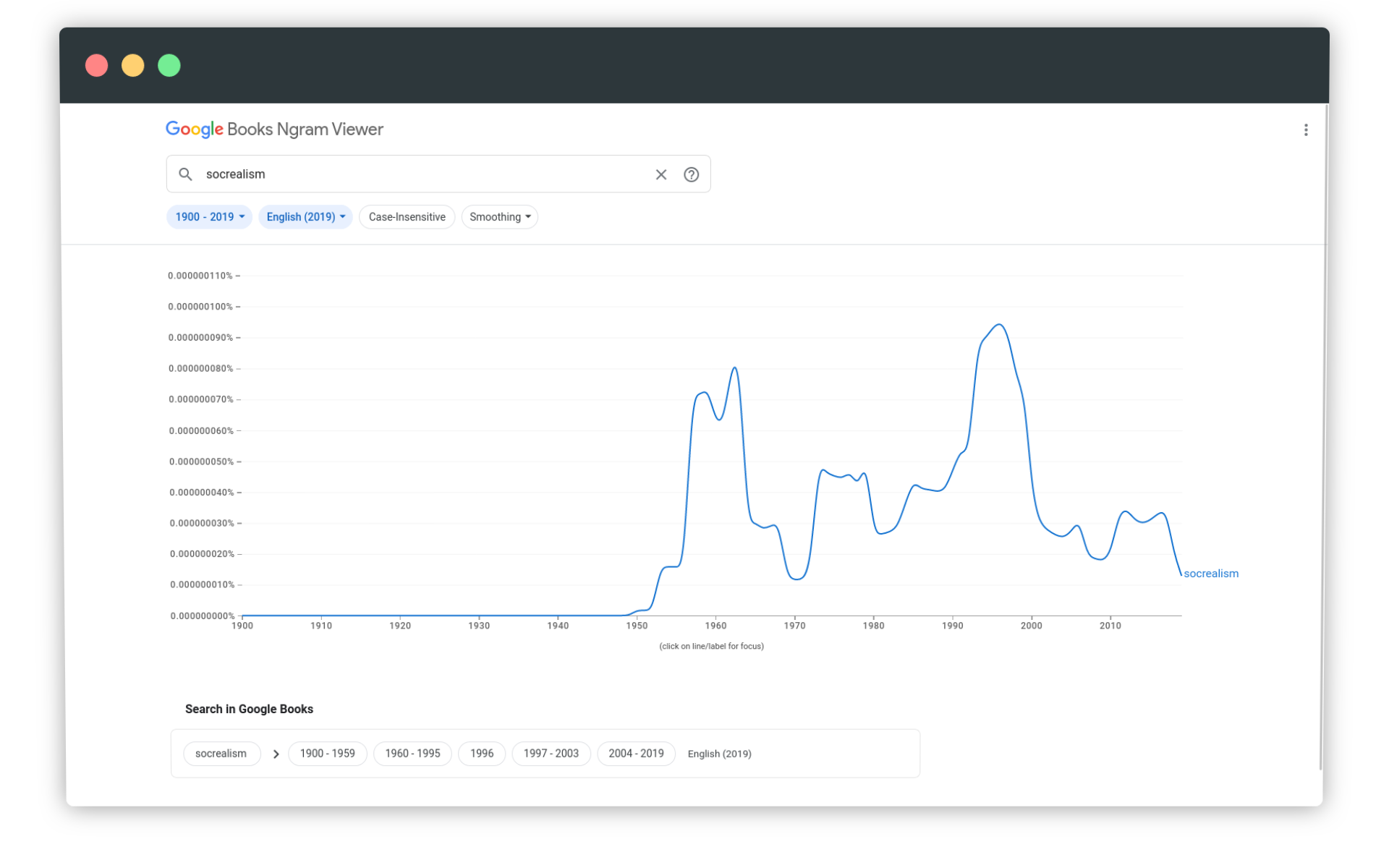
W efekcie wyszukania otrzymujemy wykres, w którym osią poziomą jest linia czasu (zakres lat 1900-2019), a oś pionowa to procentowy udział wybranego n-grama we wszystkich n-gramach rozpoznanych w zbiorze książek w określonym roku i w określonym korpusie językowym.
Zwróćmy też uwagę, że standardowo nieaktywna jest opcja Case-Insensitive - Google Ngram Viewer domyślnie uwzględnia wielkość liter przy generowaniu danych. Poniżej porównałem wyszukiwania dla różnych form zapisu frazy socrealism. Już na tym etapie łatwo zrobić błąd, myląc wpisaną frazę z wszystkimi jej wersjami.
| Fraza | Metoda | Wystąpienia (1960 r.) |
|---|---|---|
| socrealism | Case-Sensitive | 0.0000000628% |
| Socrealism | Case-Sensitive | 0.0000000346% |
Po wpisaniu frazy socrealism i wybraniu opcji ignorowania wielkości znaków, dostajemy wszystkie postaci zapisu danej frazy - w przypadku pojęcia ‘socrealizm’ są tylko dwie. Oznacza to, że chcąc zbadać obecność wszystkich wersji badanej frazy w korpusie, musimy dodać procenty. Aby dodać wartości procentowe, najpierw musimy przekształcić je w formę numeryczną: przekształcamy je na ułamki dziesiętne (0.0000000628 i 0.0000000346), dodajemy (0.0000000974) i mnożymy przez 100, aby uzyskać postać procentową. Po obliczeniach wiemy już, że wszystkie postaci frazy socrealism stanowią 0.00000974% wszystkich unigramów w korpusie English (2019) za rok 1960.
Takie liczenie ‘na piechotę’ z jakiegoś powodu nie jest potrzebne dopiero jeśli porównujemy dwie lub więcej fraz. Poniżej wykres z użyciem fraz socrealism i socialist realism i włączonym ignorowaniem wielkości znaków:
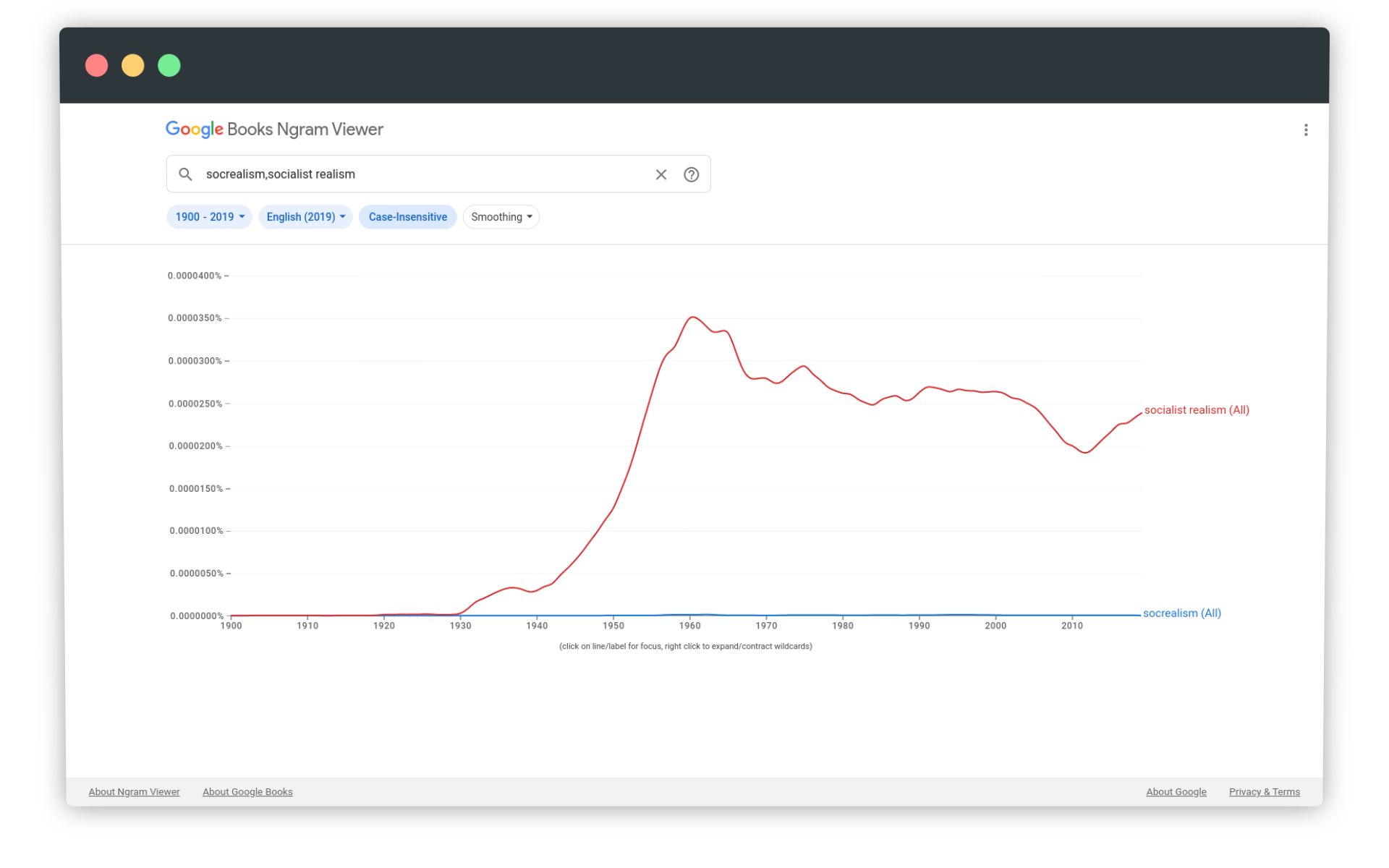
Okazuje się, że w naszym badaniu wykorzystaliśmy błędną frazę. Chociaż - co można sprawdzić w Google - fraza socrealism pojawia się w publikacjach naukowych i na niektórych stronach internetowych, dominuje zdecydowanie socialist realism - taki tytuł ma nawet anglojęzyczna strona na Wikipedii. Pracując z Google Ngram Viewer musimy odpowiednio krytycznie przygotować frazy do analizy i wiedzieć, w jakim kontekście są wykorzystywane.
O czym ma świadczyć trend?
Sarah Zhang w opublikowanym w 2015 roku artykule The Pitfalls of Using Google Ngram to Study Language wymieniła najważniejsze ograniczenia Google Ngram Viewer jako narzędzia do analizowania kultury i języka. Jak pisze Zhang,
jedną z pułapek wykorzystywania ngramów do badania popularności osób, idei lub koncepcji jest to, że w korpusie książka pojawia się tylko raz — bez względu na to, czy została przeczytana raz czy milion razy.
Korzystając z Google Ngram Viewer badamy nie tyle zmienną popularność idei i pojęć czy też nawet ich rzeczywistą obecność w języku, ale ich występowanie w dość mocno sprofilowanej bazie literatury (głównie naukowej), której źródłem były przede wszystkim bilioteki akademickie zachodnich uczelni. Bez wątpienia zawartość lektur może być sygnałem pewnych procesów społecznych, ale przecież idee i pojęcia doskonale sobie bez nich radzą. Wspomniana na wstępie lekcji analiza odchodzenia od rasistowskiego języka w przestrzeni publicznej byłaby bardziej skuteczna, gdyby analizowano ją na korpusie prasowym a nie na książkach naukowych.
I dalej - zmiany w popularności bigramu socialist realism są świadectwem nie tylko współczesnej socrealizmowi dyskusji (naukowej?) wokół tego nurtu w sztuce, literaturze i architekturze, rozwijającego się już od lat 30. XX wieku. W latach 90. w oczywisty sposób muszą być już świadectwem rozrachunków z dziedzictwem socrealizmu i w żaden sposób nie dowodzą jego pozycji we współczesnej kulturze.
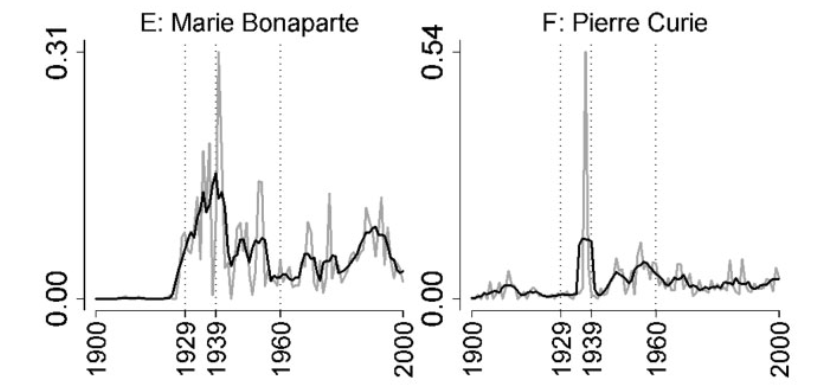
Ze względu na ograniczenia wynikające z prawa autorskiego, Google Ngram Viewer nie informuje o tym, jakie książki zostały użyte do budowy korpusu. Brakuje metadanych i kontekstu, co wytykają autorzy i autorki wspomnianego już wyżej opracowania The impact of lacking metadata for the measurement of cultural and linguistic change using the Google Ngram data sets—Reconstructing the composition of the German corpus in times of WWII (2017). Analizując dane Google Ngram Viewer dla czasów nazistowskich Niemiec, wskazują oni na niebezpieczne błędy wynikające z naiwnej intrpretacji wykresów. Na przykładzie takich osób jak Maria Bonaparte czy Pierre Curie pokazują, że widoczny wzrost liczby n-gramów identyfikujących te osoby w danych za okres hitleryzmu w żaden sposób nie powinien być interpretowany jako dowód na sympatie tych postaci dla niemieckiego totalitaryzmu, ponieważ wzrost ten jest jedynie efektem wysokiej widoczności naukowej w tym czasie. Na poniższym wykresie linie szare oznaczają dane surowe Google Ngram Viewer, a czarne dane opracowane z wykorzystaniem średniej ruchomej, wyliczonej dla okresu 5 lat - w obu przypadkach widać wyraźny wzrost liczebności fraz w publikacjach wydanych w interesującym nas okresie (wartości osi Y są podawane względnie na milion tokenów dwuelementowych).
Jaka jest reprezentatywność korpusu?
Reprezentatywność korpusu językowego (a tym jest Google Ngram Viewer) wskazuje, w jakim stopniu zbiór tekstów w korpusie odzwierciedla rzeczywiste użycie języka w określonym kontekście lub w określonej populacji. Im bardziej reprezentatywny jest korpus, tym dokładniej odzwierciedla różnorodność języka używanego przez daną grupę ludzi lub w określonym środowisku lub w określonym czasie. Bardzo łatwo to zrozumieć, przypominając sobie, że Narodowy Korpus Języka Polskiego (NKJP) nie jest rozwijany od 2012 roku i nie zawiera tekstów pozyskanych z mediów społecznościowych, dlatego nie da się w nim badać języka współczesnego polskiego internetu. Źródła NKJP to:

Aby korpus językowy był reprezentatywny, musi uwzględniać różnorodne aspekty języka, takie jak różnice regionalne, społeczne, kulturowe i stylistyczne. Powinien on zawierać różnorodne gatunki tekstów, takie jak artykuły prasowe, książki, rozmowy, eseje, pisma urzędowe itp. oraz uwzględniać różnorodność tematyczną.
korpus reprezentuje nie tyle język jako taki, ile określoną populację tekstów, i to właśnie teksty powinny stanowić punkt odniesienia przy określaniu modelu reprezentatywności
— tymczasem brak metadanych uniemożliwia nam krytyczne spojrzenie na reprezentatywność Google Ngram Viewer. Wiemy, że narzędzie to jest dostępne jedynie dla niektórych języków (nie dla języka polskiego), a badania wskazują, że używa korpusów zbudowanych przede wszystkim z publikacji naukowych.
Garbage in, garbage out
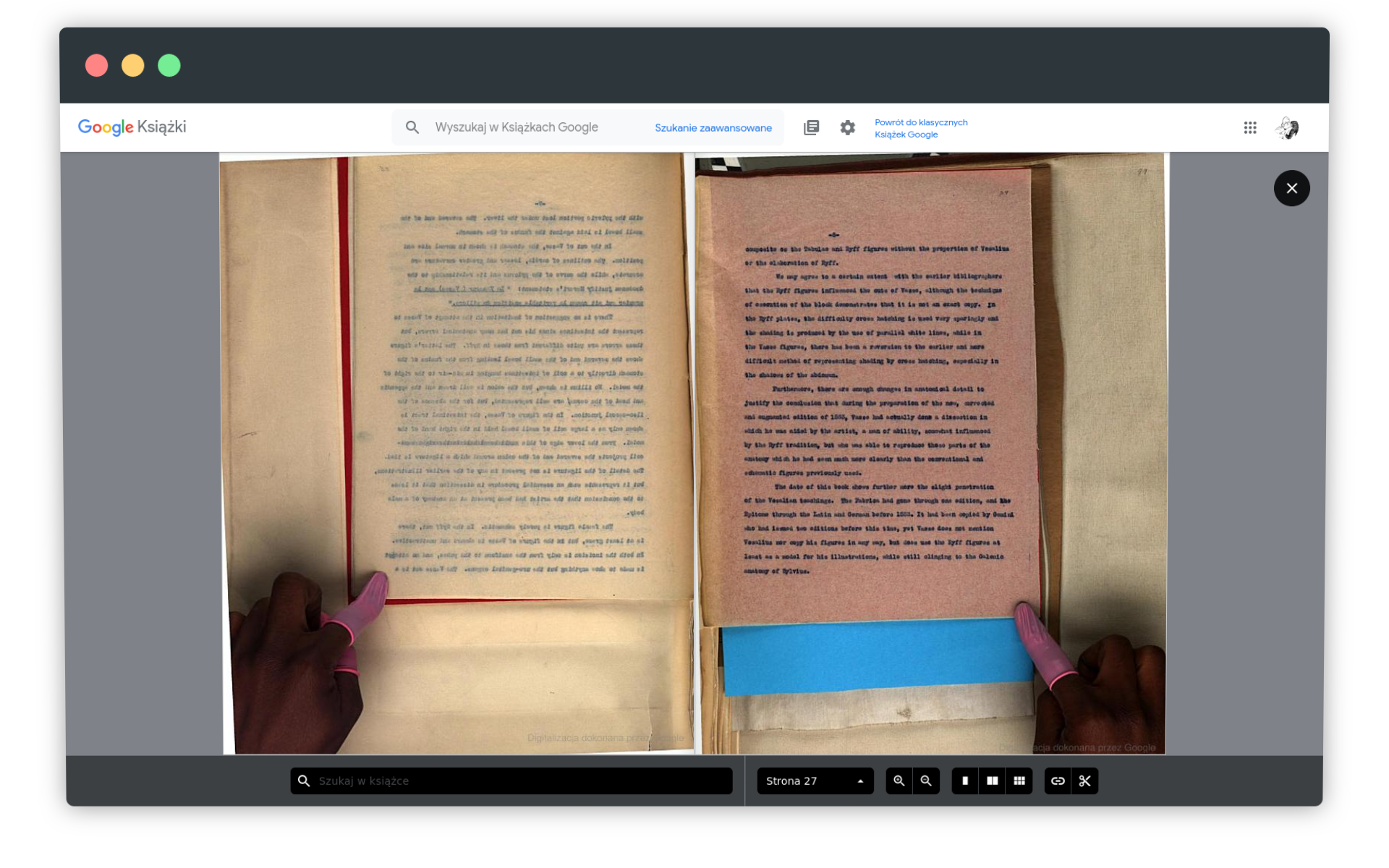
W Google Books znajduje się wydana w 1553 roku książka The Anatomy of Loys Vasse, według Google Books o objętości 16 stron, w rzeczywistości udostępniana jako 150 stronicowa publikacja, zawierająca oryginalne karty wydrukowane w XVI wieku, ale też współczesny maszynopis z opisem /tłumaczeniem dzieła. Fraza Museum pojawia się w niej osiem razy, przy czym - jak mi się wydaje - ani razu na oryginalnych XVI-wiecznych kartach.
Dane Google Ngram Viewer za 1533 rok informują, że ngram Museum jest obecna w korpusie anglojęzycznym w roku 1553 - dla roku 1553 to też jedyna forma zapisu tego pojęcia w korpusie.
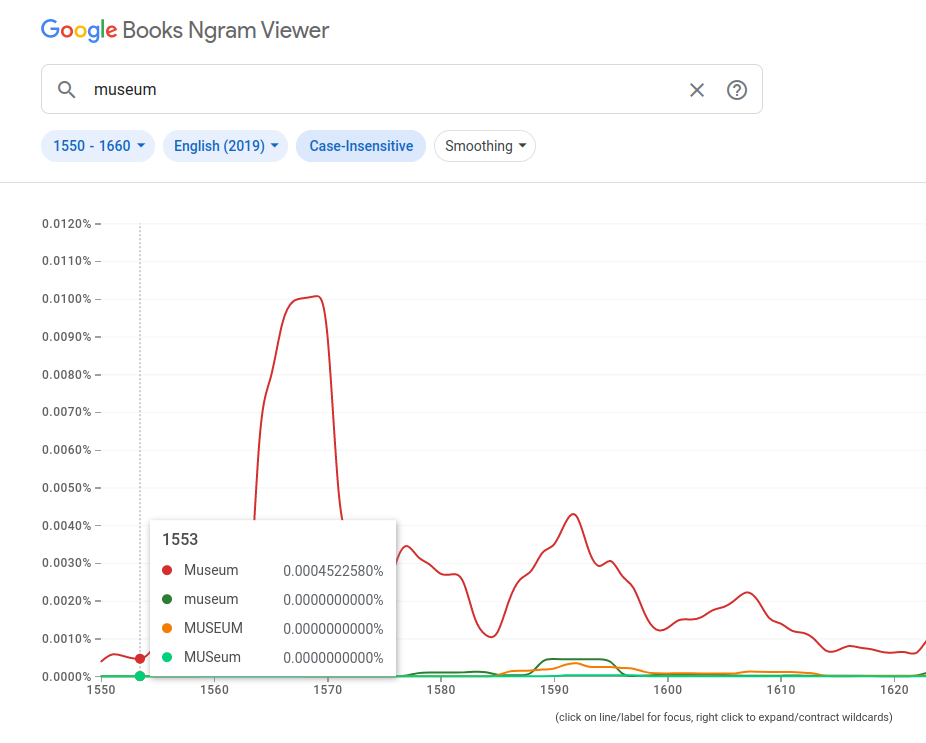
Jak możemy ufać tym danym, skoro interesująca nas fraza nie jest obecna na kartach oryginalnej publikacji z XVI wieku, tylko w jej późniejszym opracowaniu? British Museum - bo to ta fraza jest sztucznie obecna w The Anatomy of Loys Vasse - założono w 1753 roku! Co więcej, czy te dane mogą być dla nas wiarygodne, skoro nie wiemy nawet, czy The Anatomy of Loys Vasse weszła w skład korpusu wykorzystywanego przez Google Ngram Viewer.
Garbage in, garbage out (GIGO) to popularny zwrot mówiący o tym, że jeśli dane wejściowe są nieodpowiednie lub złej jakości, to końcowy efekt ich przetwarzania również będzie miał niską jakość albo po prostu będzie błędny. W takim przypadku nawet najlepszy system przetwarzania danych nie będzie w stanie wygenerować poprawnych wyników. To wielkie wyzwanie w korzystaniu z Google Ngram Viewer.
Podsumowanie
Spróbujmy zebrać podstawowe ograniczenia Google Ngram Viewer, które wpływają na możliwość wykorzystywania go do analiz kultury i języka:
- dostępność tylko kilkunastu wybranych języków (brak języka polskiego),
- niska reprezentatywność korpusu, zbudowanego przede wszystkim z książek naukowych dostępnych w bibliotekach zachodnich uczelni,
- chaotyczne przełączanie między wyszukiwaniem ignorującym wielkość znaków i biorącym je pod uwagę,
- minimalna liczba wystąpień każdego ngrama to 40 / rok (trudno więć badać bardzo niszowe frazy),
- brak czytelnego oznaczenia, że wyszukujemy wśród n-gramów a nie w liczbie opublikowanych książek,
- słowa oznaczające te same pojęcia mogą być różnie obecne w korpusie (socrealism, socialist realism),
- ignorowanie popularności publikacji w generowaniu trendu - niszowe książki naukowe traktowane tak samo jak bestsellery,
- brak metadanych i kontekstu dla obecności n-gramów w określonym roku.
Mimo tych ograniczeń Google Ngram Viewer umożliwia szybkie przeglądanie milionów książek - to wyjątkowy zbiór, którego nie mają narodowe korpusy językowe. Google Ngram Viewer stał się też zjawiskiem kulturowym i funkcjonuje w internecie w setkach memów takich jak te, dostępne na TikToku jeszcze w 2021 roku:
Wykorzystanie metod
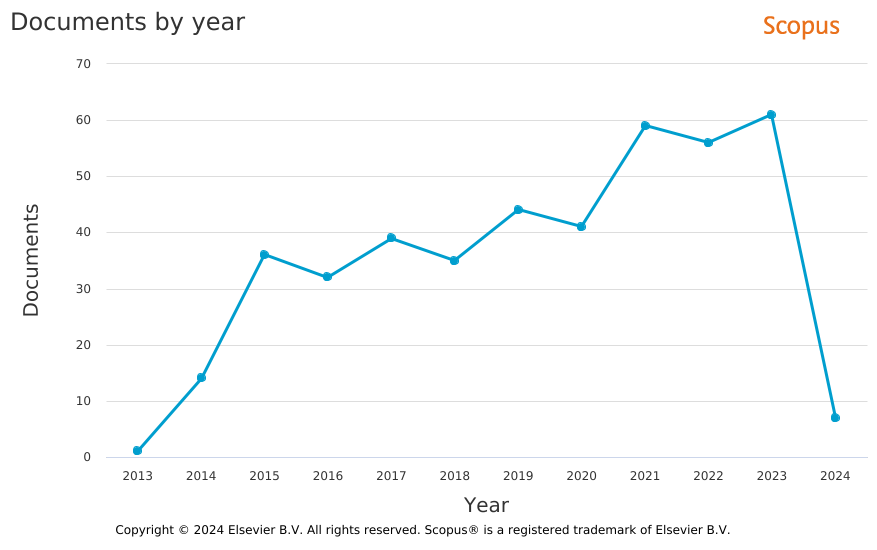
W bazie artykułów naukowych Scopus można wygenerować dane na temat liczby artykułów naukowych, które w przypisach przywołują adres https://books.google.com/ngrams/. Jak widać, liczba takich tekstów nieustannie wzrasta - dane za 2024 są oczywiście niepełne:
Pomysł na warsztat
Google Ngram Viewer to ciekawe narzędzie warsztatowe - łatwo dostępne i niewymagajace programowania, a dające dostęp do ogromnej ilości danych:
- analiza trendów językowych: niech uczestnicy i uczestniczki warsztatów wybiorą kilka słów kluczowych związanych z określonym tematem (np. technologią, modą, polityką, sztuką) i poproś o zbadanie zmian w częstotliwości ich występowania w Google Ngram Viewer. Wyniki tej analizy przedyskutujcie, zwracając uwagę na ograniczenia narzędzia i danych,
- analiza porównawcza języka w określonych dekadach: dobrym pomysłem na warsztat może być próba uchwycenia powtarzalności pewnych trendów w modzie czy muzyce,
- analiza trendów popularności określonych osób w korpusie i spojrzenie na te trendy z historycznego punktu widzenia (zob. np. jak dane dotyczące Lecha Wałęsy nakładają się na ważne wydarzenia z historii Polski lat 70. i 80.),
- zebranie słów kluczowych identyfikujących określone problemy czy zagadnienia (ekologia, moda, gatunki literackie) i sprawdzenie, które z tych słów jest najsilniej obecne w korpusie Google Ngram Viewer. Za pomocą jakich słów literatura w określonym języku omawiała problem ekologii? Przez kontekst dziury ozonowej, lasów deszczowych, katastrof ekologicznych, katastrofy klimatycznej?
- możecie wyszukiwać błędy w danych Google Ngram Viewer, inspirując się memami - np. fraza internet jest obecna w danych nawet dla publikacji z XVI-XVIII wieku 😉


