
Wprowadzenie
Archiwa społeczne gromadzą fotografie, dokumenty, wspomnienia po to, aby je szeroko udostępnić. Archiwiści społeczni i archiwistki społeczne pukają do domów prywatnych, żeby zapytać o cenne archiwalia, przeglądają stare kroniki szkolne, nagrywają wspomnienia mieszkańców i mieszkanek. Dzięki temu docierają do historii autentycznej, widzianej z wielu perspektyw
— czytamy na stronie Centrum Archiwistyki Społecznej.
Dzięki bazie archiwów społecznych możemy poszukać archiwum dokumentującego historię naszej miejscowości, bliskiej nam organizacji lub własnej rodziny. Digitalizacja i internet pozwoliły oddolnym inicjatywom historycznym na zdobycie nowych odbiorców i upowszechnianie własnych zbiorów poza lokalnym kontekstem. Misją Centrum Archiwistyki Społecznej jest wspieranie takich inicjatyw - warto skorzystać z ich oferty.
Archiwistyka społeczna,
jeszcze do niedawna rzadko podejmowana przez badaczy i badaczki, obecnie wykładana jest na uniwersytetach; archiwistyka społeczna jest także przedmiotem licznych badań naukowych i konferencji.
Jeśli tak, to spróbujmy dowiedzieć się więcej na jej temat. Skorzystajmy z możliwości, jakie daje analiza korpusowa, czyli sposoby maszynowego badania dużych zbiorów tekstów w celu zbadania właściwości wykorzystywanego w nich języka i zidentyfikowania kluczowych wątków, wartości czy problemów w nich poruszanych. Taką analizę przeprowadzić można np. wobec ogromnych zbiorów prasy, tweetów czy stron internetowych - w tej lekcji wykorzystamy kilka publikacji (książek i podręczników) oraz około 200 stron internetowych, wyodrębnionych z wyników wyszukiwania Google dzięki usłudze Google Search API.
Cele lekcji
Celem lekcji jest zdobycie umiejętności przygotowania korpusu w programie Sketch Engine. Podzielimy ją na dwie części:
- w pierwszej poznamy podstawy projektowania korpusu oraz metodę budowania go w Sketch Engine,
- w drugiej sprawdzimy dostępne narzędzia, które pozwalają na analizę korpusu i dają podstawy do zbudowania pewnych interpretacji na interesujący nas temat.
Efekty
Efektem pierwszej lekcji ze Sketch Engine będzie korpus gotowy do analizy. Zanim zbudujemy korpus, poznamy najważniejsze reguły dotyczące jego projektowania.
Wymagania
Będziemy potrzebować konta w Sketch Engine - konto jest darmowe i w pełni funkcjonalne przez 30 dni, a jego rejestracja nie wymaga podawania danych karty płatniczej. Uwaga: osoby studiujące i pracujące na Uniwersytecie Warszawskim mają darmowy nielimitowany dostęp do pełnej wersji programu. W tym celu należy zalogować się przez konto w domenie uw.edu.pl (Institutional Login).
Część merytoryczna
Teoretycznym wsparciem naszej pracy będzie artykuł Victorii Kamasy Techniki językoznawstwa korpusowego wykorzystywane w krytycznej analizie dyskursu. Przegląd, dostępny w repozytorium Uniwersytetu im. Adama Mickiewicza w Poznaniu. Autorka opisuje tam podstawy budowania korpusów i przedstawia najważniejsze narzędzia analityczne, bazujące na przetwarzaniu języka naturalnego do odpowiednich zestawień i statystyk.
Czym jest korpus?
Krytyczna analiza dyskursu to nurt z pogranicza socjologii i językoznawstwa, który skupia się na badaniu relacji władzy. Nie to będzie nas teraz interesować, chociaż relacje władzy można badać także wobec archiwów społecznych, zadając pytania o to, kto decyduje, jakie treści mogą stać się zbiorami archiwalnymi, albo co podkreśla się a co ukrywa w opisach tych zbiorów.
W naszym projekcie chcemy zbadać, z jakimi pojęciami wiąże się archiwistyka społeczna. Jakie są (albo mają być) cechy archiwów? Jaką historię eksplorują? To tylko niektóre z pytań, na jakie może odpowiedzieć analiza korpusowa.
Analiza korpusowa nie da nam jednoznacznych odpowiedzi, zresztą nie byłoby to specjalnie potrzebne. Jeśli nie wiemy, czym są archiwa społeczne, możemy przeczytać stronę CAS albo publikowany przez tę instytucję podręcznik. Korpus nie da nam jednoznacznych definicji - możemy je wypracować na podstawie pozyskanych danych i porównać z tymi, które są wyrażone wprost w podręcznikach i tekstach naukowych.
Sam korpus definiowany jest przeważnie jako zbiór tekstów, które podlegają obróbce maszynowej […]. Zwraca się także uwagę na jego reprezentatywność i zrównoważenie, przy czym ta pierwsza rozumiana jest jako obecność wszystkich elementów analizowanej odmiany [języka] w korpusie […], zaś zrównoważenie jako zachowanie właściwych (uwzględniających częstotliwość i istotność) proporcji pomiędzy reprezentacją poszczególnych elementów badanej odmiany [języka] w korpusie […].
Korpus nie jest więc prostym zbiorem losowych tekstów czy tekstów, które po prostu da się łatwo znaleźć. Znów, podobnie jak w przypadkach innych zadań humanistyki cyfrowej, skorzystanie z narzędzi wydaje się prostsze i mniej angażujące niż prawidłowe i uważne przygotowania zasobów do analizy.
Spróbujmy teraz zaprojektować nasz korpus, biorąc pod uwagę konieczność zapewnienia odpowiedniej reprezentatywności i zrównoważenia.
Reprezentatywność i zrównoważenie
Nasz korpus będzie składał się z tekstów naukowych i merytorycznych oraz treści rozmaitych stron internetowych (m.in. stron archiwów społecznych, ale też bibliotek, portali regionalnych, magazynów online). Jego reprezentatywność będzie w ograniczonym stopniu zapewniona - będą to treści różnego rodzaju, pisane różnym językiem i w różny sposób dotykające zagadnienia archiwów społecznych i archiwistyki społecznej. Nie umieścimy w korpusie treści publikowanych w mediach społecznościowych, co na pewno jest dużą wadą naszego projektu - dziś to w tej przestrzeni archiwa informują o swojej działalności i wchodzą w relacje z odbiorcami.
Istnieją korpusy ogólne, które mają reprezentować bardzo szeroki zakres języka - jednym z nich jest Narodowy Korpus Języka Polskiego:
Lista źródeł korpusu zawiera nie tylko klasykę literatury polskiej, ale też prasę codzienną i specjalistyczną, nagrania rozmów, teksty ulotne i internetowe. Zróżnicowanie tematyczne i gatunkowe tekstów, dbałość o reprezentację rozmówców obu płci, w różnym wieku i z różnych regionów, są dla wiarygodności korpusu równie ważne jak jego wielkość.
Budowany przez nas korpus będzie zróżnicowany, ale w zdecydowanie mniejszym stopniu. Zresztą uczymy się pracować ze Sketch Engine, a nie prowadzimy badania naukowego 😊.
Wybór tekstów do korpusu
W artykule Victorii Kamasy znajdziemy fragment poświęcony sposobom wyboru tekstów do korpusu. Teksty do korpusu wybierać można na podstawie
- intuicyjnego przekonania o istotności tekstów,
- wysokiej pozycja tekstów w rankingach (np. wybór najczęściej czytanych tekstów z czasopism internetowych, dokonany na podstawie statystyk oglądalności),
- obecności określonych słów w tekstach,
- czasu powstania tekstów.
Nasz korpus zbudowany będzie m.in. na podstawie przekonania o istotności wybranych tekstów. Oto jego część naukowa i edukacyjna:
- Podręcznik dla archiwistów społecznych (2023) opublikowany przez Centrum Archiwistyki Społecznej, będący centralną instytucją wspierającą archiwistykę społeczną w Polsce. Z racji takiej roli CAS język podręcznika możemy uznać za wzorcowy dla dyskusji o tym zjawisku,
- Inaczej to zniknie. Archiwa społeczne w Polsce–wielokrotne studium przypadku (2019) to książka Magdaleny Wiśniewskiej-Drewniak, w której znajdziemy naukowy krytyczny język opisu zjawiska archiwów społecznych oraz raporty z badań tych archiwów. Publikacja dostępna jest w repozytorium UMK,
- Archiwa organizacji pozarządowych w Polsce (2015) - zbiór tekstów naukowych, wydany przez Naczelną Dyrekcję Archiwów Państwowych, udostępniany na serwerze CAS,
- Archiwistyka społeczna. Poradnik - jedno z pierwszych (2012) opracowań archiwów społecznych w Polsce, będące zaproszeniem do dyskusji dla badaczy i praktyków tej dziedziny, wydane przez Ośrodek KARTA.
Te cztery opracowania układają się w pewną historię publikowania naukowego i merytorycznego na temat archiwów społecznych (od 2012 do 2023 roku) - możemy wykorzystać to w naszej analizie. Są to też teksty obszerne - podręcznik CAS ma około 260 stron, książka Wiśniewskiej-Drewniak - ponad 600, zbiór artykułów - ponad 200, podręcznik KARTY - 150. To już zasób, dla którego racjonalne jest zastosowanie analizy korpusowej - trudno bowiem byłoby równolegle uważnie (close reading) przeczytać wszystkie te publikacje. Z drugiej strony analiza korpusowa nie wyklucza uważnego, samodzielnego czytania badanych tekstów - wtedy korzystamy z niej jako metody pomocniczej. Zazwyczaj jednak zasób tekstów jest tak duży, że nie da się go przeczytać samodzielnie. Warto w tym miejscu przypomnieć sobie też treść lekcji poświęconej Google Ngram Viewer, która wskazuje na ograniczenia maszynowych analiz tekstu.
Do czterech publikacji spróbujemy automatycznie dodać treści 279 stron internetowych na temat archiwów społecznych i archiwistyki społecznej, pozyskanych z usługi Google Search i Google News. Dzięki temu w łatwy sposób będziemy mogli wyjść poza przestrzeń języka naukowego i użyć tekstów mówiących o konkretnych archiwach. Kryterium wyboru tych tekstów to obecność określonych słów (archiwa społeczne, archiwistyka społeczna), a automatycznie zebrane linki prowadzą to tak różnych zasobów jak witryna Wikipedii, Patronite, “Tygodnik Powszechny”, strony archiwów oraz portale regionalne.
Problem praw autorskich i prywatność
Projektując korpus należy wziąć pod uwagę regulacje prawne. Prawo autorskie to duże wyzwanie dla budowania korpusów tekstowych. Jednym z głównych problemów jest ochrona praw majątkowych do utworów, które wchodzą do korpusu. Nie zawsze możemy mieć prawo do swobodnego kopiowania tekstów i przetwarzania ich. Projektując korpus, zwróćmy uwagę na możliwości, jakie daje nam dozwolony użytek - planowana reforma prawa autorskiego (zgodna z dyrektywą unijną 2019/790/UE) zakłada, że
Nowością będzie wprowadzenie do PrAut nowej postaci dozwolonego użytku na rzecz uczelni, organizacji badawczych oraz instytucji dziedzictwa kulturowego – zwielokratniania utworów w celu eksploracji tekstów i danych do celów badań naukowych (ang. text and data mining, TDM). […] Zwielokrotnione utwory, przedmioty praw pokrewnych i bazy danych będą mogły być przechowywane do celów badań naukowych, w tym weryfikacji wyników tych badań (projektowany art. 262 PrAut). Przechowywanie będzie musiało się odbywać z zachowaniem poziomu bezpieczeństwa zapewniającego dostęp do tych utworów wyłącznie upoważnionym osobom, z uwzględnieniem procedur uwierzytelniających. Eksploracja będzie możliwa bez względu na wolę uprawnionego i bez rekompensaty. Czynności w ramach TDM nie będą mogły być dokonywane w celu osiągnięcia bezpośredniej lub pośredniej korzyści majątkowej, co zgodnie z dyrektywą DSM należy rozumieć jako wymóg nienastawienia działalności beneficjenta na osiąganie zysku (Źródło).
Zwróćmy uwagę, że kluczowymi warunkami budowania i analizy korpusów jest cel naukowy i niekomercyjny oraz odpowiednie ograniczenie dostępu do utworów chodzących w skład korpusu. Teksty korpusu zawierać mogą też dane osobowe oraz informacje, które nie zawsze powinny być publicznie dostępne. Intymne fragmenty dziennika osobistego lub drastyczne opisy znajdujące się transkrypcji wywiadu historii mówionej z pewnością nie powinny znaleźć w publicznie dostępnym korpusie.
Import tekstów do Sketch Engine
Aby zbudować korpus w Sketch Engine, musimy zaimportować do tego programu wybrane teksty. Zacznijmy od tekstów naukowych / edukacyjnych, które zidentyfikowaliśmy wyżej. Oto bezpośrednie odnośniki do plików wszystkich czterech publikacji:
https://cas.org.pl/wp-content/uploads/2023/10/Podrecznik-dla-archiwistow-spolecznych-CAS.pdf
https://repozytorium.umk.pl/bitstream/handle/item/6105/Drewniak_Inaczej%20to%20zniknie%20-%20druk%201.pdf?sequence=6
https://cas.org.pl/wp-content/uploads/2021/03/Archiwa_organizacji_pozarzadowych.pdf
https://ksiegarnia.karta.org.pl/wp-content/uploads/2017/11/Archiwa_spoleczne_podrecznik.pdfImport tekstów do Sketch Engine jest bardzo wygodny, ponieważ:
- importujemy teksty w prosty sposób wgrywając je do systemu,
- możemy importować teksty podając wyłącznie listę adresów URL,
- możemy importować teksty w różnych formatach (w tym PDF i w postaci strony internetowej) - system automatycznie przetworzy je na postać tekstową.
Jeśli jesteśmy już zalogowani do systemu, przechodzimy na widok Dashboard. W prawym górnym rogu strony zobaczymy listę dostępnych korpusów - jest na niej m.in. duży korpus ogólny języka polskiego (zawierający ponad 22 tys. dokumentów i 7 mld słów!). Klikając w New Corpus przejdziemy do widoku pozwalającego na podanie podstawowych metadanych naszego nowego korpusu.
Sketch Engine pozwala na budowanie wielojęzykowych korpusów - nasz zawierać będzie tylko teksty w języku polskim - w opcjach wybieramy Single Language Corpus oraz język polski. Podajemy też nazwę korpusu (jest wymagana) oraz jego opis, który może przydać się, jeśli zamierzamy udostępniać korpus innym użytkownikom i użytkowniczkom Sketch Engine.
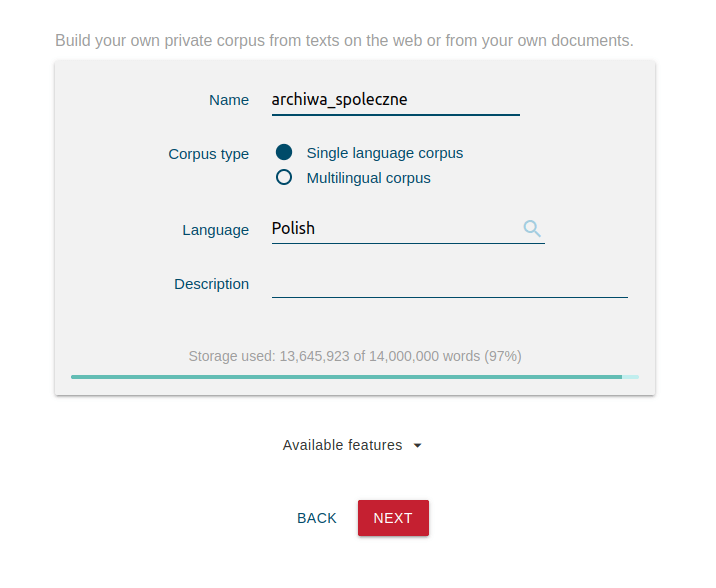
Po kliknięciu przycisku Next przejdziemy do widoku importu tekstów do korpusu. Ponieważ mamy gotowy zestaw adresów URL publikacji, jakie chcemy umieścić w korpusie, moglibyśmy użyć opcji Find texts on the web i podać tam adresy do pozyskania. Niestety, niektóre serwery automatycznie blokują maszynowy dostęp do swoich zasobów, więc import mógłby być nieskuteczny. Ponieważ mamy tylko cztery publikacje, łatwo możemy ręcznie umieścić je w systemie - kliknijmy I have my own texts.

Przy widżecie umieszczania plików znajduje się krótka informacja o prawach do plików korpusu:
Twoje korpusy są tylko twoje — inni użytkownicy nie mogą ich zobaczyć ani uzyskać do nich dostępu, chyba że wyraźnie zdecydujesz się udostępnić korpus. My (zespół Sketch Engine) nie wykorzystujemy ani nie eksploatujemy treści twoich korpusów w żaden sposób, nawet w celu poprawy statystycznych metod przetwarzania języka naturalnego. Jesteś odpowiedzialny za wszelkie problemy związane z własnością intelektualną (takie jak prawa autorskie) treści, które udostępniasz.
Oznacza to, że treścią naszych korpusów mogą być też materiały, które nie powinny być udostępniane - np. pełne relacje historii mówionej, dokumenty osobiste itp. Możemy przygotować korpus i analizę z takich materiałów, a potem wyeksportować korpus i skasować wszystkie dane w Sketch Engine.
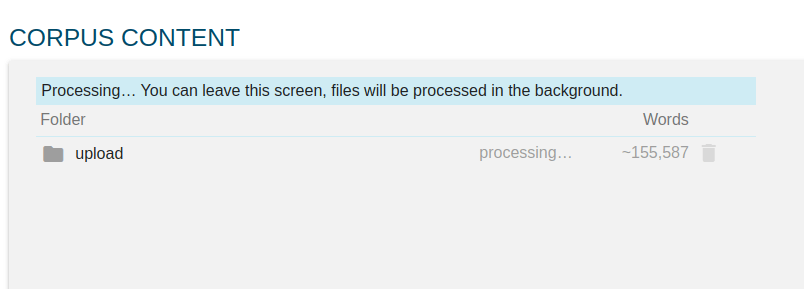
Upload kilku plików trwa tylko chwilę, po czym system przetwarza je do postaci korpusowej. Ten proces jest realizowany w tle, więc - w razie potrzeby, przy dużej liczbie importowanych plików - możemy zamknąć przeglądarkę, wyłączyć komputer i wrócić do korpusu po kilku godzinach. Oznacza to też, że możemy teraz równolegle dodać do korpusu nasze linki. Tym razem skorzystamy z opcji Find texts on the web.
Wybieramy opcję URLs i podajemy adresy URL stron (każdy w nowej linii), odznaczamy też opcję Compile when finished - poczekajmy, aż przetworzone zostaną ręcznie umieszczone przez nas w Sketch Engine teksty. Klikamy Go i system zaczyna pobierać i przetwarzać podane linki:
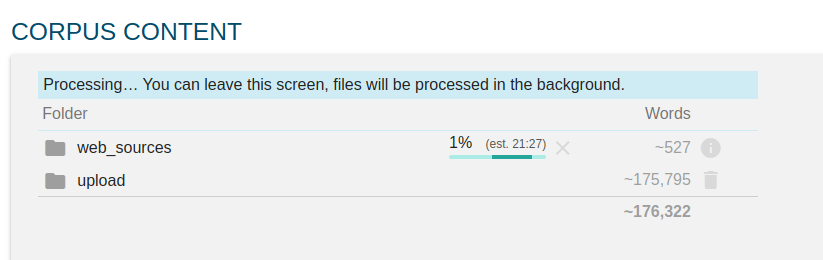
Treści stron są pobierane z wykorzystaniem oprogramowania WebBootCaT:
Dane pobrane z internetu są czyszczone, opcjonalnie deduplikowane, a materiały nietekstowe są eliminowane, aby uzyskać językowo wartościowy materiał tekstowy.
Pobieranie treści stron może być czasochłonne - na szczęście w każdej chwili możemy zamknąć okno przeglądarki i wrócić do Sketch Engine za jakiś czas, kiedy pobrany zasób będzie już gotowy i będziemy mogli skompilować korpus.
Przeglądanie zawartości korpusu
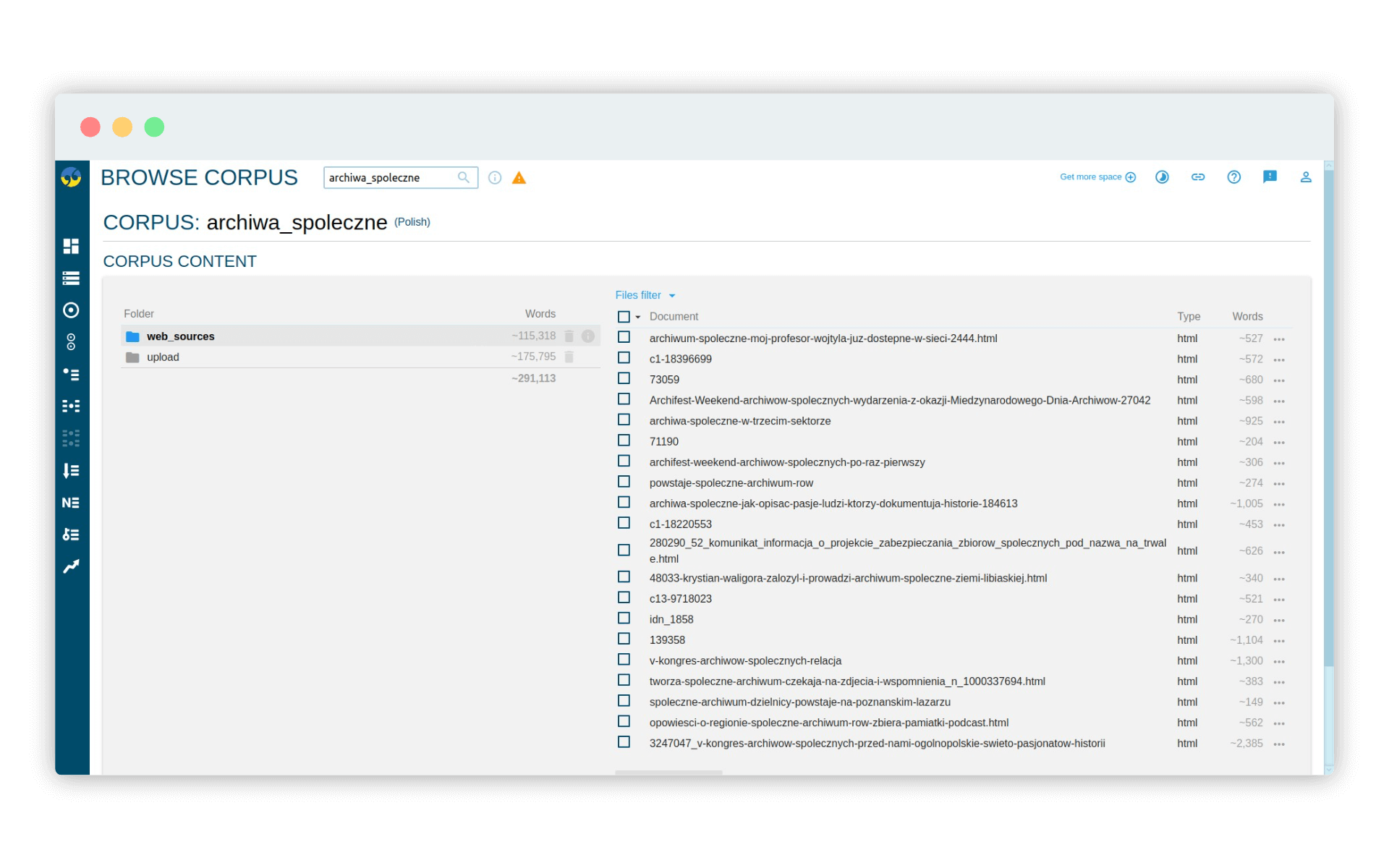
Jeśli proces uploadu i przetworzenia treści stron został już zakończony, możemy podejrzeć katalog web_sources. Sketch Engine pozwala na swobodne nadawanie nazw katalogom, dzięki czemu możemy przechowywać treści korpusowe w uporządkowany sposób.
Każdy dokument w koprusie może być opisany dowolnymi metadanymi. Aby je dodać, wystarczy kliknąć w trzykropek po prawej stronie wybranego dokumentu lub zaznaczyć wszystkie dokumenty i wybrać opcję Bulk actions - Edit metadata:
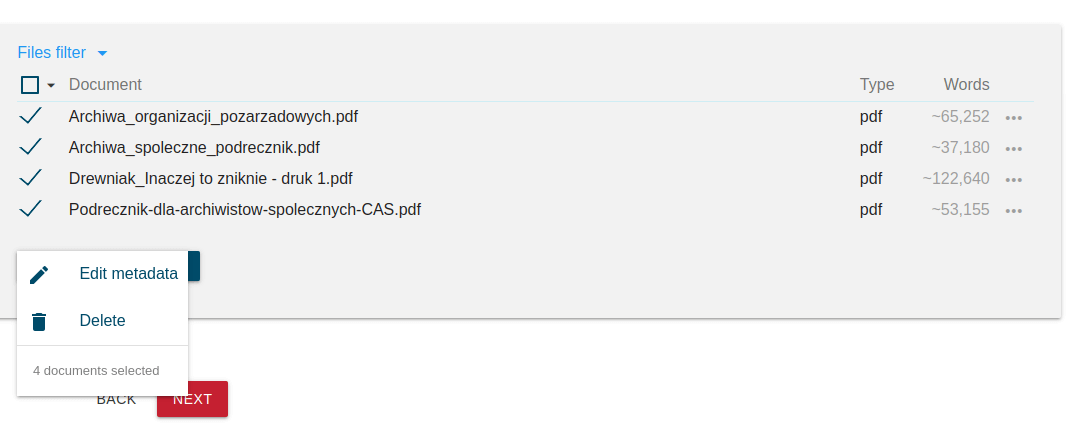
Korzystając z przeglądarki dokumentów korpusu możemy znaleźć w naszym zbiorze zasobów importowanych z internetu pliki PDF, zawierające teksty naukowe. Spróbujmy opisać te dokumenty w sposób, który pozwoli odróżnić je od tekstów popularnonaukowych czy reporterskich - dzięki temu będziemy mogli ograniczać naszą analizę wyłącznie do treści określonego typu.
Klikając Manage corpus - Browse wyświetlamy dwa katalogi, w których znajdują się nasze zasoby. Klikamy w katalog web_sources i filtrujemy dokumenty PDF (wystarczy kliknąć na nazwę kolumny Type):
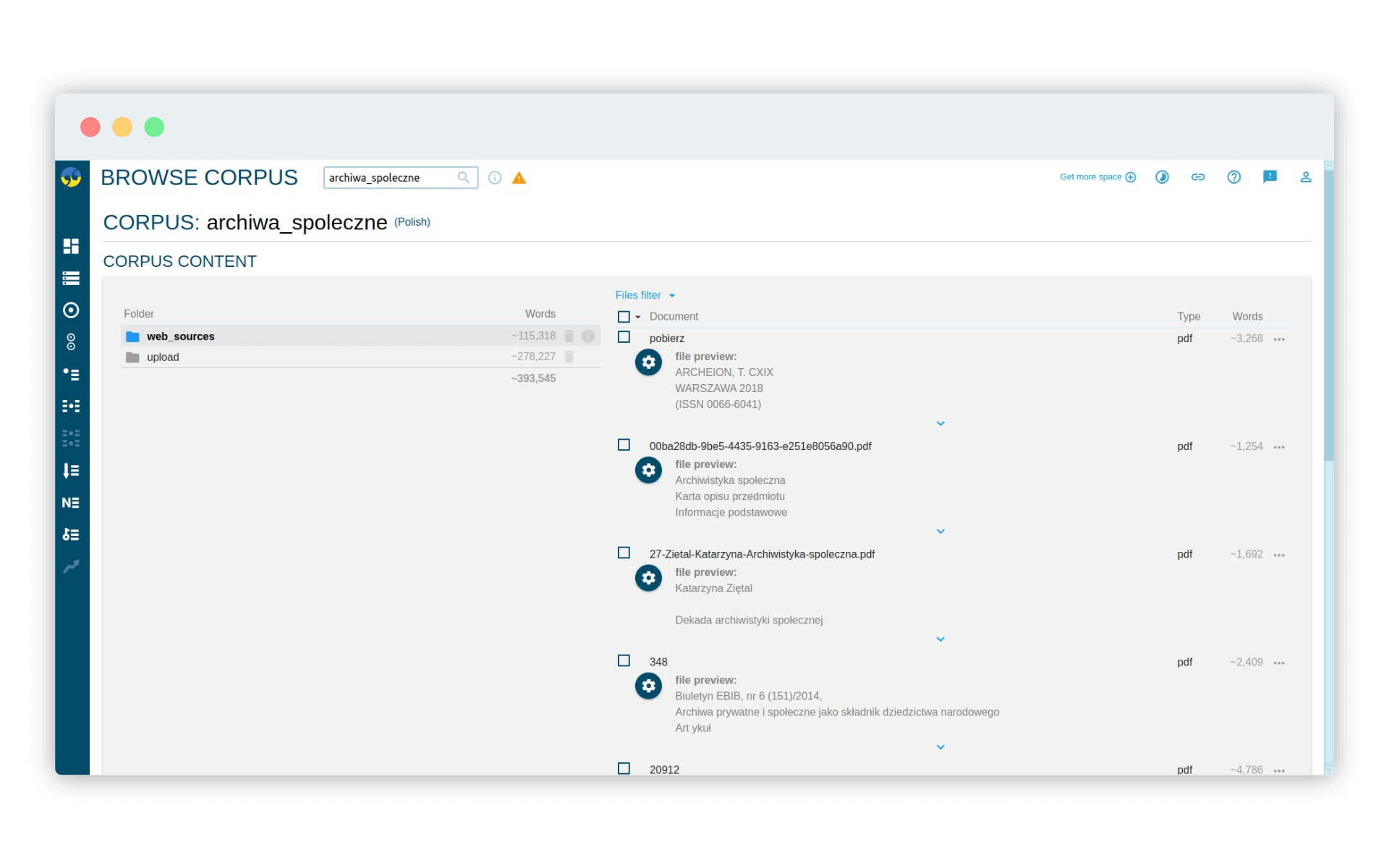
Zaznaczamy wszystkie dokumenty PDF i wybieramy opcję Bulk actions - Edit metadata. Dodajmy do naszych dokumentów PDF klasę academic:
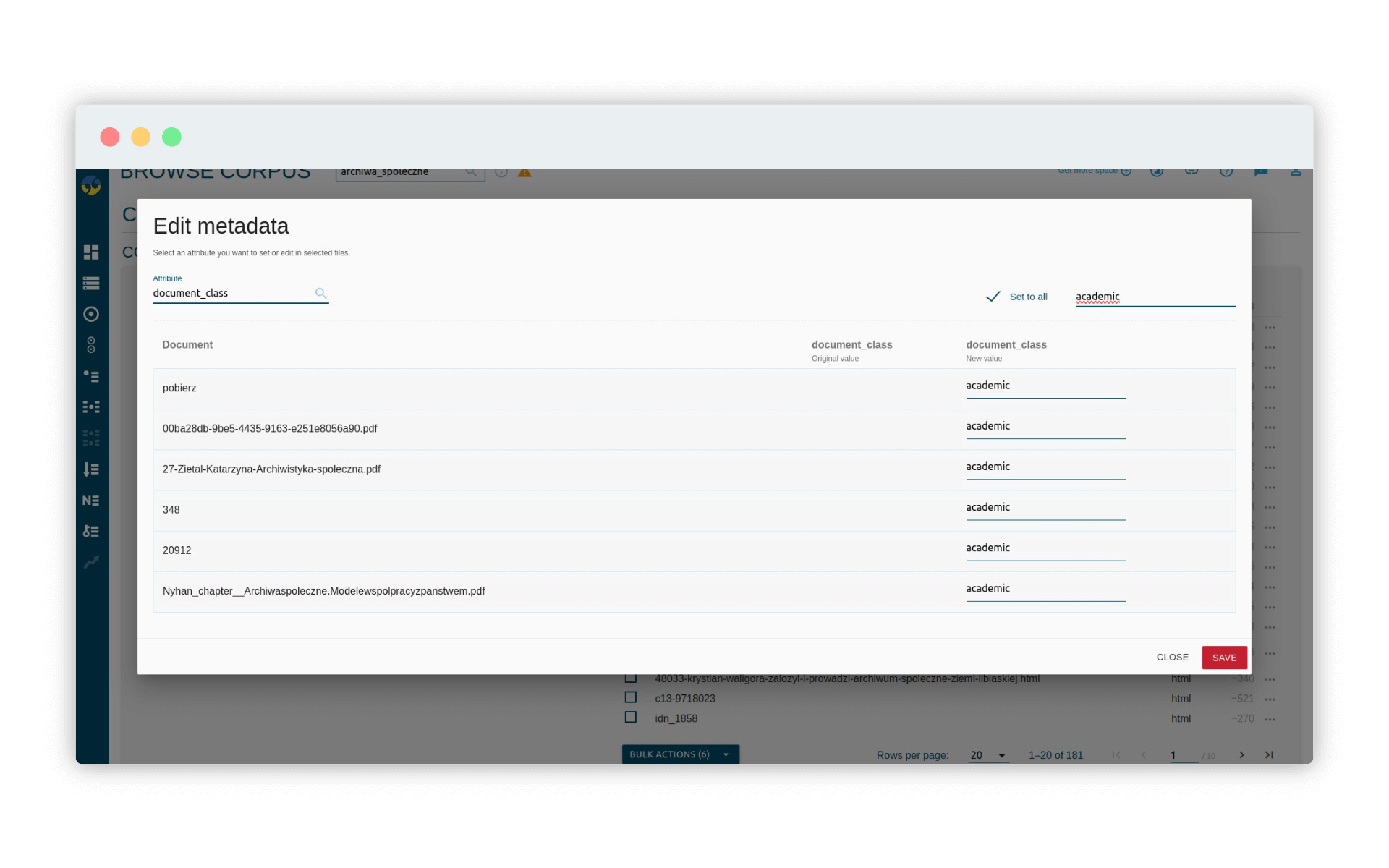
Uwaga: to samo musimy zrobić z dokumentami w katalogu Upload. Wszystkie dokumenty, które nie będą opisane taką wartością metadanych uznamy za teksty popularne. Jak widać, Sketch Engine pozwala też na sprawne zarządzanie zbiorem tekstów korpusowych.
Pozostaje nam teraz skompilowanie korpusu. W ustawieniach kompilacji możemy ustawić zasady usuwania podobnych tekstów oraz - co jest standardowo ustawione dla każdego korpusu monojęzykowego - usunąć wszystkie treści w innych niż główny językach. Deduplikacja może być wykonana na poziomie paragrafu (opcja p) lub zdania (s), lub na poziomie nazwy dokumentu.

Kilkamy Save and compile i uruchamiamy proces kompilacji:
Kompilacja polega na wykonaniu na tekstach korpusu wielu operacji językowo-statystycznych, które pozwalają na późniejsze analizowanie języka korpusu. W trakcie kompilacji Sketch Engine przetwarza także metadane.
Definiowanie subkorpusów
Efekty kompilacji możemy podejrzeć w widoku Corpus info. Jak widać, nie wszystkie treści z adresów URL udało się nam automatycznie pobrać - korpus zawiera tylko 185 dokumentów:
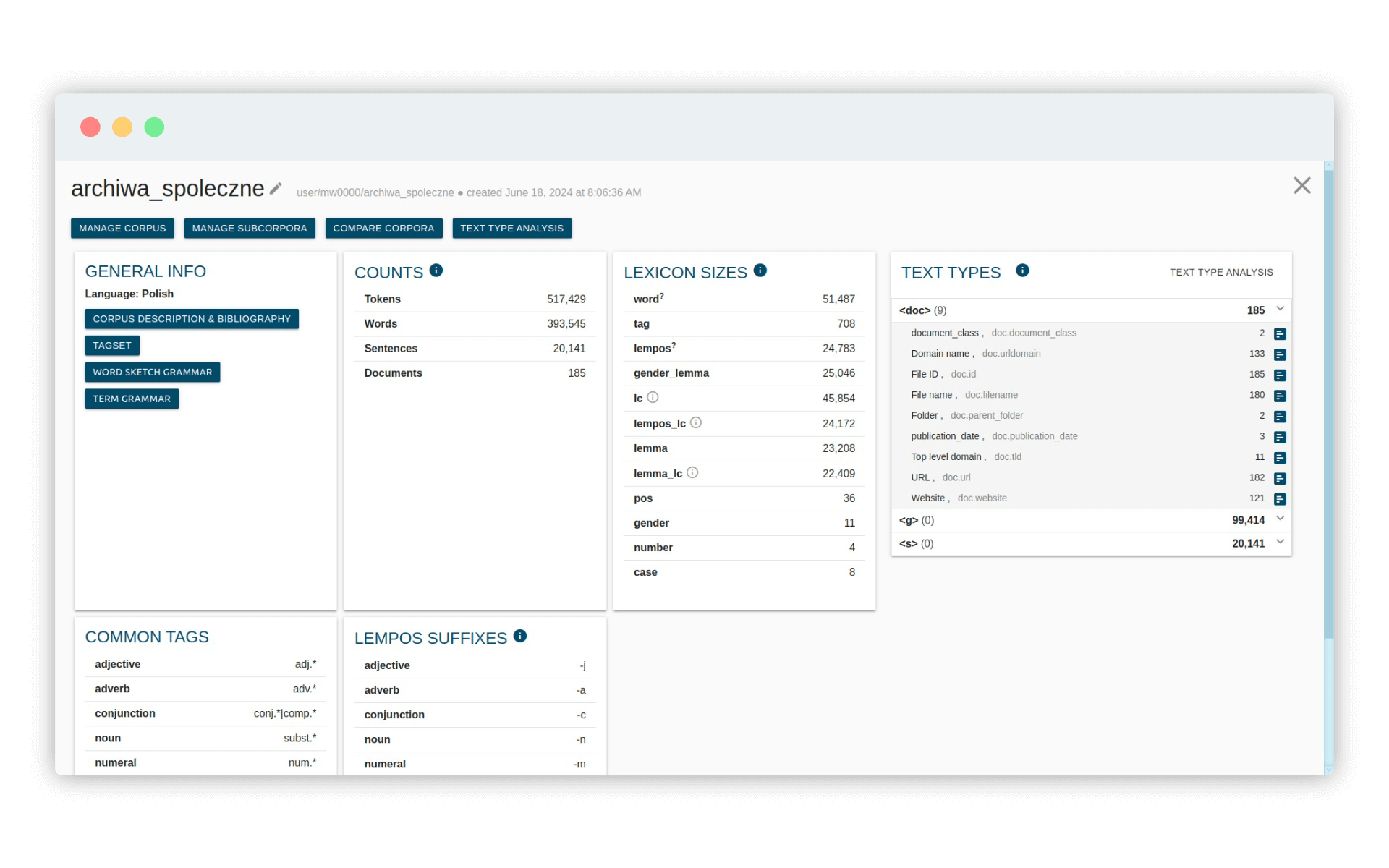
Ponieważ tekstom naukowym (i edukacyjnym) w naszym korpusie dodaliśmy dodatkową pozycję metadanych document_class, możemy na tej podstawie wydzielić subkorpusy tekstów akademickich (merytorycznych) i popularnych. W razie potrzeby będziemy w stanie analizować je osobno.
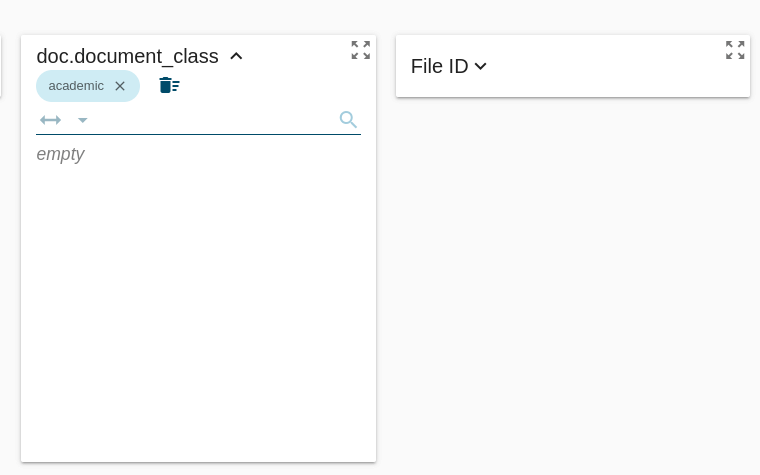
W widoku Manage info - Subcorpora klikamy przycisk Create subcorpus. Na liście wszystkich dostępnych metadanych wybieramy panel document_class i jego wartość academic.
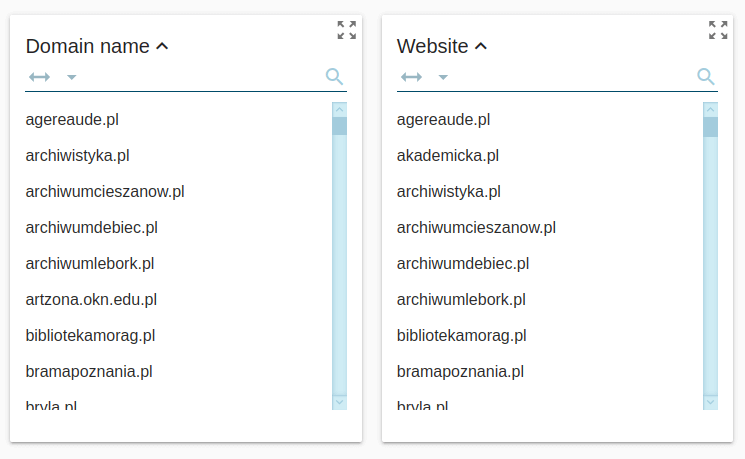
Możemy w razie potrzeby budować też subkorpusy na podstawie źródła importowanych z internetu tekstów (witryny czy domeny) lub na podstawie wybranego folderu:
Reprezentatywność korpusu?
Czy wydzielenie subkorpusu akademickiego miało sens? Jak najbardziej 🤓! Zależało nam na tym, żeby korpus był zróżnicowany, tymczasem zawiera on przede wszystkim treści naukowe i edukacyjne. Chociaż dokumenty tej klasy to jedynie niecałe 6 proc. dokumentów w korpusie (Structure frequency):
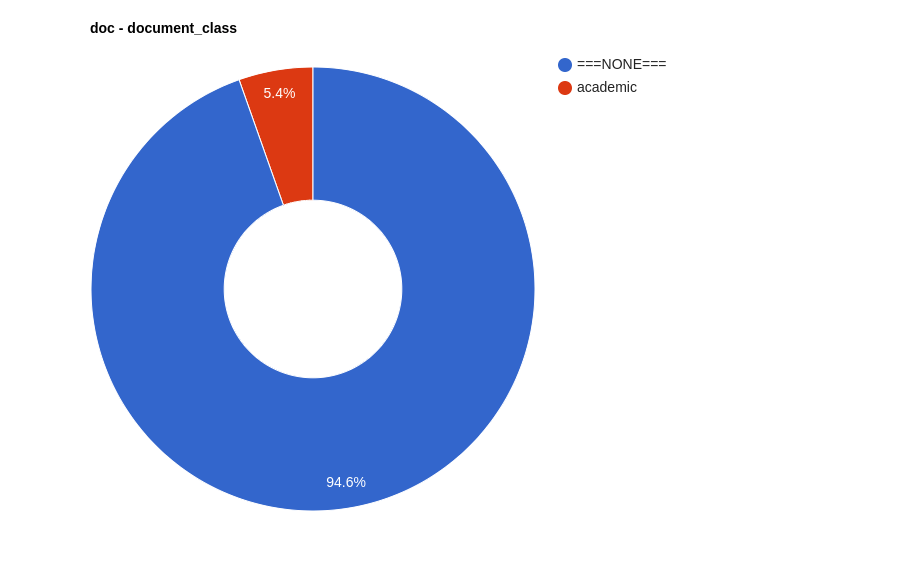
to ze względu na swoją objętość tworzą one aż 75 proc. treści korpusu (Token coverage):
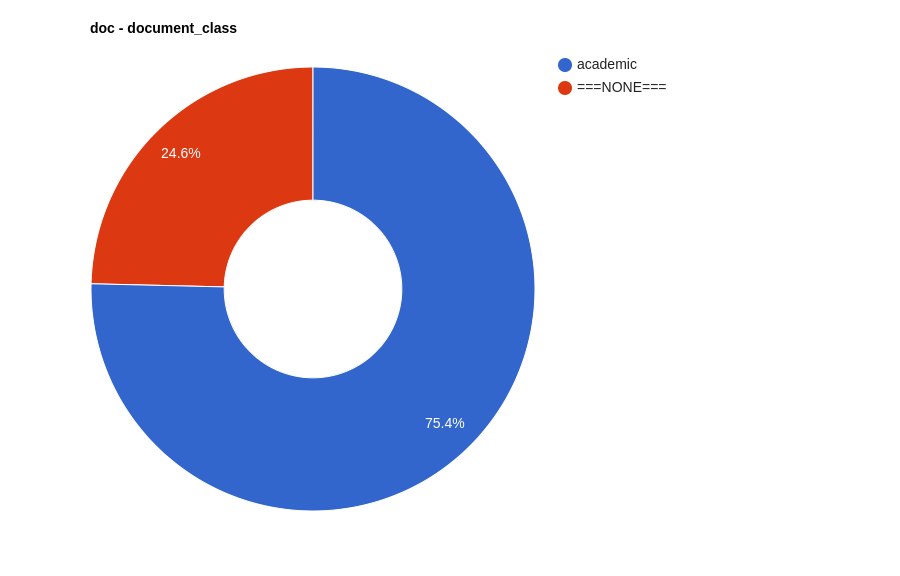
Nasz korpus nie będzie zrównoważony, a jego reprezentatywność będzie ograniczona. Zrównoważony korpus powinien zawierać teksty z różnych źródeł, gatunków i stylów językowych w sposób, który odzwierciedla ich rzeczywiste występowanie w danym języku. W naszym korpusie dominują teksty naukowe i edukacyjne, a przecież trudno oczekiwać, że o archiwach społecznych pisze się przede wszystkim językiem naukowym…
Z drugiej strony w naszym korpusie znajdują się treści popularnonaukowe i wypowiedzi na temat archiwów społecznych, pochodzące ze zróżnicowanych źródeł - w jakimś stopniu zapewniliśmy jego reprezentatywność, bo o archiwach społecznych pisze się w pracach naukowych i podręcznikach, ale też w czasopismach internetowych, portalach ogólnoinformacyjnych, na stronach bibliotek czy instytucji. Reprezentatywność naszego korpusu byłaby większa, gdybyśmy włożyli do niego treści z mediów społecznoścsiowych, transkrypcje materiałów audiowizualnych (np. z YouTube) i transkrypcje rozmów z osobami zaangażowanymi w budowanie i wspieranie archiwów społecznych - to już jednak zadanie na osobny projekt naukowy.
W razie potrzeby możemy jednak pracować na wybranym subkorpusie. W kolejnej lekcji zajmiemy się już analizowaniem korpusu i sprawdzimy, jak się pisze o archiwach społecznych 😊.
Podsumowanie
Sketch Engine to narzędzie, w którym od podstaw możemy przygotować korpus językowy. Okazuje się jednak, że większym wyzwaniem od obsługi programu jest odpowiednie przygotowanie treści i profilu korpusu. Zebranie tekstów do analizy może wymagać wiele pracy - nie zawsze możemy po prostu pobrać gotowy zestaw stron z internetu. Wyzwaniem jest też prawo autorskie - spodziewamy się jednak, że możemy swobodnie budować i analizować korpusy w ramach dozwolonego użytku. Pamiętajmy, że korzystanie z dozwolonego użytku nie oznacza, że możemy swobodnie republikować dokumenty korpusu.
Wykorzystanie metod
Korpusy językowe wykorzystywać można do wielu celów:
- analizy języka (np. badania nowomowy komunistycznej, języka korporacyjnego czy listów pasterskich episkopatu),
- wsparcia budowania słowników i tezaurusów,
- badań jakościowych na tekstach źródłowych (konkordancja pozwala zobaczyć wybrane słowa w kontekstach),
- wykrywania plagiatów, cytowań, inspiracji,
- analizy trendów językowych (zmiany języka w czasie, badane za pomocą korpusów diachronicznych, takich jak np. Elektroniczny korpus tekstów polskich z XVII i XVIII w. ),
- badań nacechowania emocjonalnego tekstów.
To tylko niektóre z zastosowań korpusów językowych. Obecnie zwraca się też uwagę na rolę dużych modeli językowych (LLM) jako narzędzi budowania słowników.
Pomysł na warsztat
W ramach pracy metodą projektu (WebQuest) możemy poprosić uczestników warsztatu o zaprojektowanie zrównoważonego i reprezentatywnego korpusu językowego na wybrany temat, nawet jeśli nie chcemy takiego korpusu przygotowywać w Sketch Engine. Do realizacji takiego zadania konieczne będzie rozpoznanie cech i odmian analizowanego języka i przestrzeni, w których można go znaleźć.
Ciekawym tematem takiej pracy może być np. język recenzji literackich i oceniania książek (od czasopism kulturalnych przez blogi aż do transkrypcji filmów z YouTube i wpisów w mediach społecznościowych) czy badanie różnych języków i stylów wypowiedzi generowanych automatycznie w ChatGPT na wybrany temat.


