
Wprowadzenie
W pierwszej lekcji poświęconej budowie korpusów udało nam się pobrać treści do korpusu na temat archiwów społecznych oraz skomplikować ten korpus w Sketch Engine. Wygenerowaliśmy też podstawowe statystyki korpusu, które wykazały, że nadreprezentowane są w nim źródła naukowe i edukacyjne.
W tej lekcji będziemy analizować nasz korpus, starając się odpowiedzieć na pytania o to, jak definiuje się archiwa społeczne, jakie wartości się im przypisuje i z jakimi aktywnościami łączy. W ten sposób będziemy w stanie spojrzeć na archiwa społeczne ponad ich ogólną definicją, proponowaną przez Centrum Archiwistyki Społecznej:
Archiwa społeczne gromadzą fotografie, dokumenty, wspomnienia po to, aby je szeroko udostępnić. Archiwiści społeczni i archiwistki społeczne pukają do domów prywatnych, żeby zapytać o cenne archiwalia, przeglądają stare kroniki szkolne, nagrywają wspomnienia mieszkańców i mieszkanek. Dzięki temu docierają do historii autentycznej, widzianej z wielu perspektyw.
Cele lekcji
Celem lekcji jest poznanie podstawowych narzędzi analizy korpusowej i nauka korzystania z nich w aplikacji Sketch Engine. W tej lekcji zajmiemy się generowaniem list frekwencyjnych i konkordancji. W kolejnych poznamy inne metody analiz korpusowych.
Efekty
Efektem lekcji będą dane i treści uzupełniające ogólną definicję archiwów społecznych (i archiwistyki społecznej). Ponieważ nasza praca nie ma charakteru naukowego, koncentrować się będziemy bardziej na korzystaniu z narzędzi niż budowaniu interpretacji, która mogłaby zostać umieszczona w artykule naukowym.
Wymagania
Do skorzystania z tej lekcji konieczne jest zapoznanie się z opublikowanym wcześniej wprowadzeniem do budowy korpusów w Sketch Engine oraz przygotowanie korpusu.
Warto także przeczytać artykuł Victorii Kamasy Techniki językoznawstwa korpusowego wykorzystywane w krytycznej analizie dyskursu. Przegląd, dostępny w repozytorium Biblioteki Uniwersyteckiej UAM. Będziemy odwoływać się do niego w treści lekcji.
Część merytoryczna
Odpowiednio przygotowany i skompilowany korpus jest gotowy do analizy. Narzędzia udostępniane przez Sketch Engine nie wymagają programowania - wiele rzeczy możemy uzyskać wybierając odpowiednie opcje, ustawiając parametry itp. Sketch Engine nie da nam oczywiście jednoznacznych odpowiedzi i gotowych interpretacji - interpretujemy korpus samodzielnie na podstawie wyliczonych przez program danych i statystyk.
Jedną z najprostszych metod analizy korpusu jest budowanie i interpretacja list frekwencyjnych. Zacznijmy od tego naszą lekcję. Oczywiście musimy zalogować się w Sketch Engine.
Analiza list frekwencyjnych
Jak przypomina autorka przywoływanego w naszych lekcjach opracowania, lista frekwencyjna to
lista wszystkich słów pojawiających się w korpusie wraz z częstotliwością ich występowania i procentowym udziałem w korpusie.
Aby przygotować listę frekwencyjną w Sketch Engine, wybieramy widok Wordlist. Z lekcji poświęconej generowaniu chmury słów kluczowych wiemy, jak ważne jest odpowiednie przekształcenie słów, które chcemy zliczać. Budowanie statystyk w oparciu o nieprzetworzone słowa spowoduje, że zliczone będą błędnie słowa mające to samo znaczenie, ale występujące w różnych odmianach (np. słowa archiwum i archiwów zostaną policzone oddzielnie). Aby uniknąć takiej sytuacji, powinniśmy sprowadzić wszystkie słowa do form słownikowych.
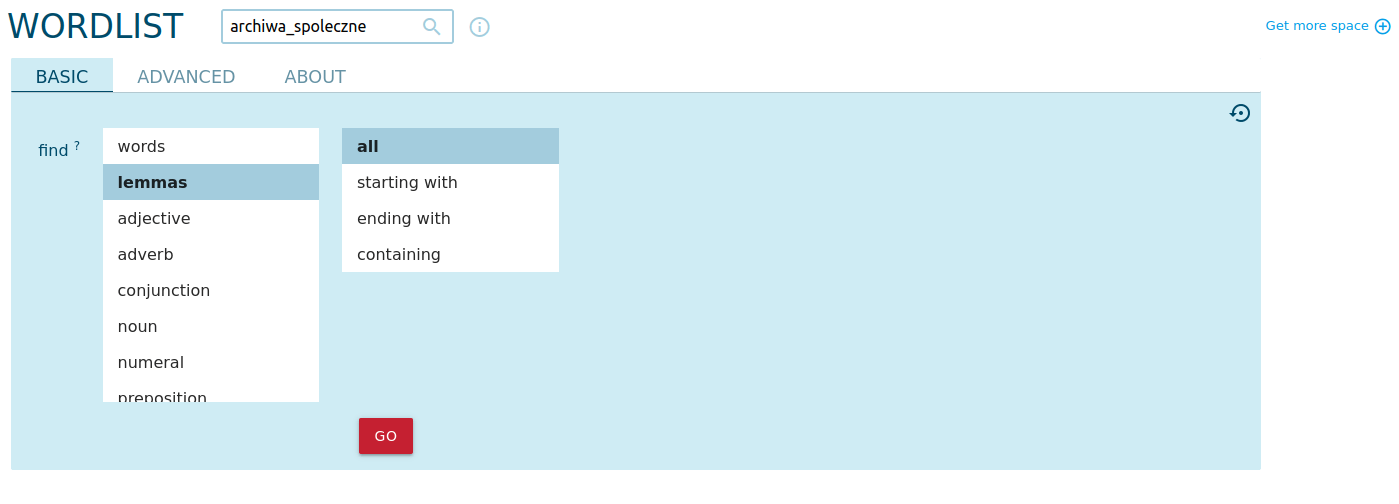
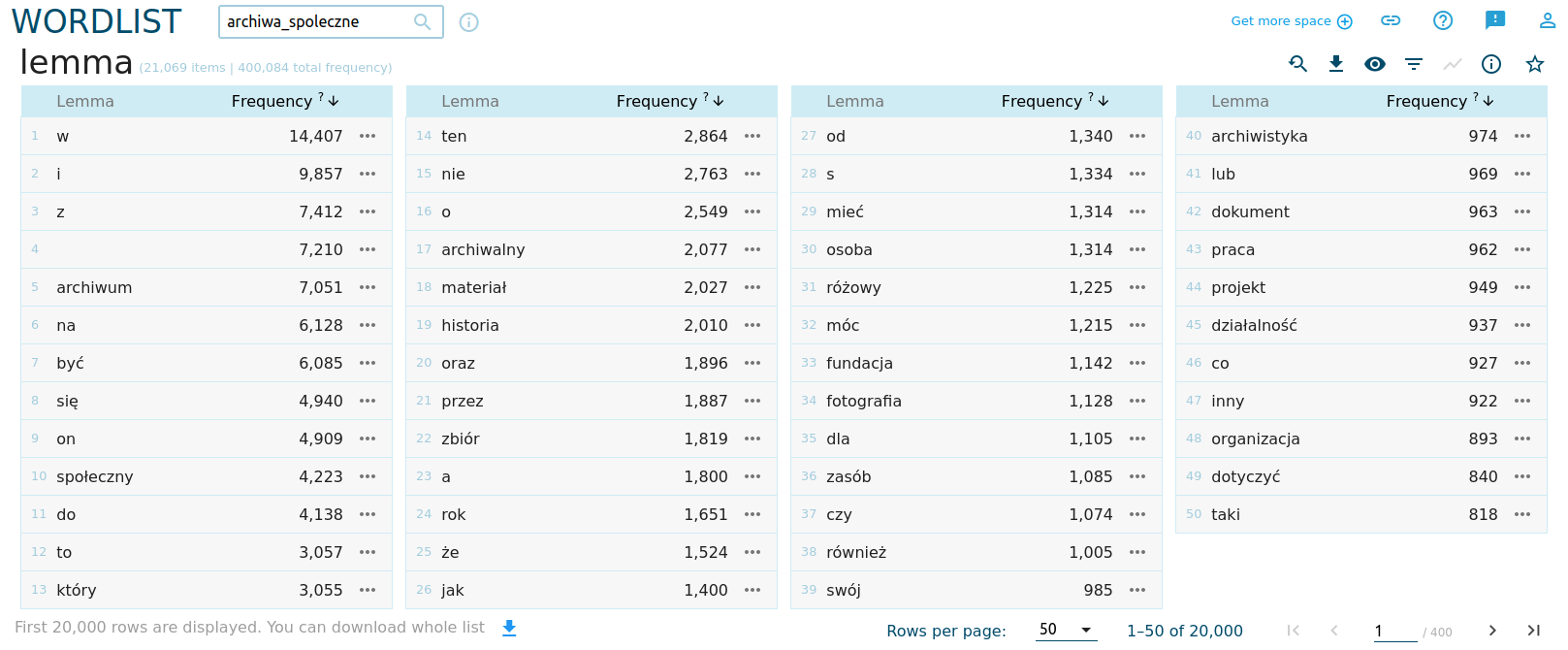
Jak widać, Sketch Engine daje bardzo szeroki wybór możliwości budowania list frekwencyjnych. Skorzystajmy najpierw ze statystyk form słownikowych (lemma), potem sprawdźmy przymiotniki.
Statystyka form słownikowych (przynajmniej dane o najczęściej pojawiających się słowach w korpusie) nie mówi nam jeszcze zbyt wiele, chociaż na liście pojawiają się ciekawe elementy:
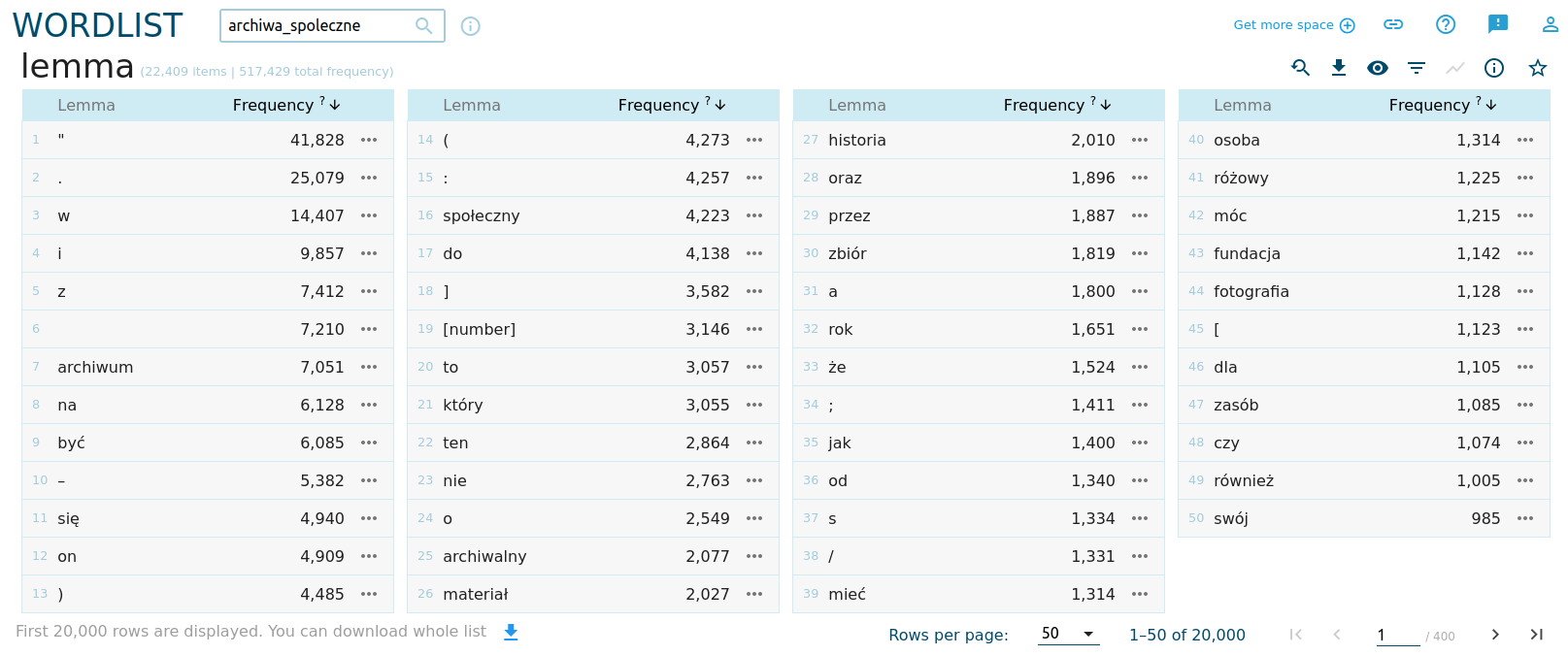
Prawo Zipfa się sprawdza
Zgodnie z prawem Zipfa, im częściej słowo występuje w korpusie, tym jego ranga jest mniejsza. Widzimy to doskonale w wygenerowanych danych: przyimki, spójniki, zaimki, partykuły czy czasowniki posiłkowe występują najczęściej, ale nie znaczą nic w naszej analizie (chociaż można je wykorzystać w stylometrii, ale to już inny temat). W korpusie dominują też słowa takie jak archiwum, archiwalne, społeczne - to oczywiste, biorąc pod uwagę temat, na podstawie którego gromadziliśmy teksty do analizy.
Na uwagę zasługują takie słowa jak materiał czy zasób, wskazujące na znaczenie zawartości archiwów, oraz fundacja, wskazująca na instytucjonalną postać wielu archiwów. Słowo różowy w naszym zestawieniu okazało się… zaskakującym błędem Sketch Engine 😢. Słowo to nie występuje w korpusie, kliknięcie w widok konkordancji ujawnia, że chodzi o skrót r. (od roku):
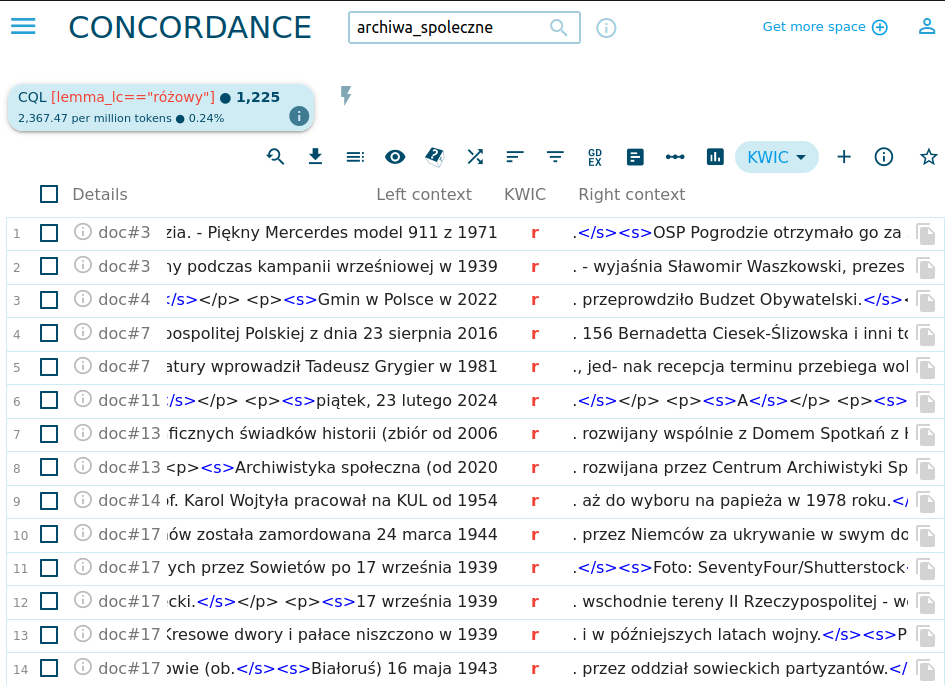
Zawsze krytycznie analizujmy dane generowane automatycznie i w ograniczony sposób ufajmy oprogramowaniu.
Bardziej wartościową listę otrzymamy, korzystając z ustawień zaawansowanych. Tutaj standardowo filtrowane są nonwords: liczby, znaki interpunkcyjne oraz słowa poprzedzone liczbami:
Tak wygenerowana lista wydaje się ciekawsza. Widzimy tutaj ważne dla naszej analizy słowa takie jak dokument, projekt, organizacja. Znów nie są to słowa, które w istotny sposób wzbogacałyby naszą wiedzę o archiwach społecznych, chociaż wysoka pozycja słowa projekt może wiele mówić o formie funkcjonowania tych inicjatyw:
Plik z pełnymi danymi dostępny jest na GitHubie.
Statystyka czasowników i przymiotników
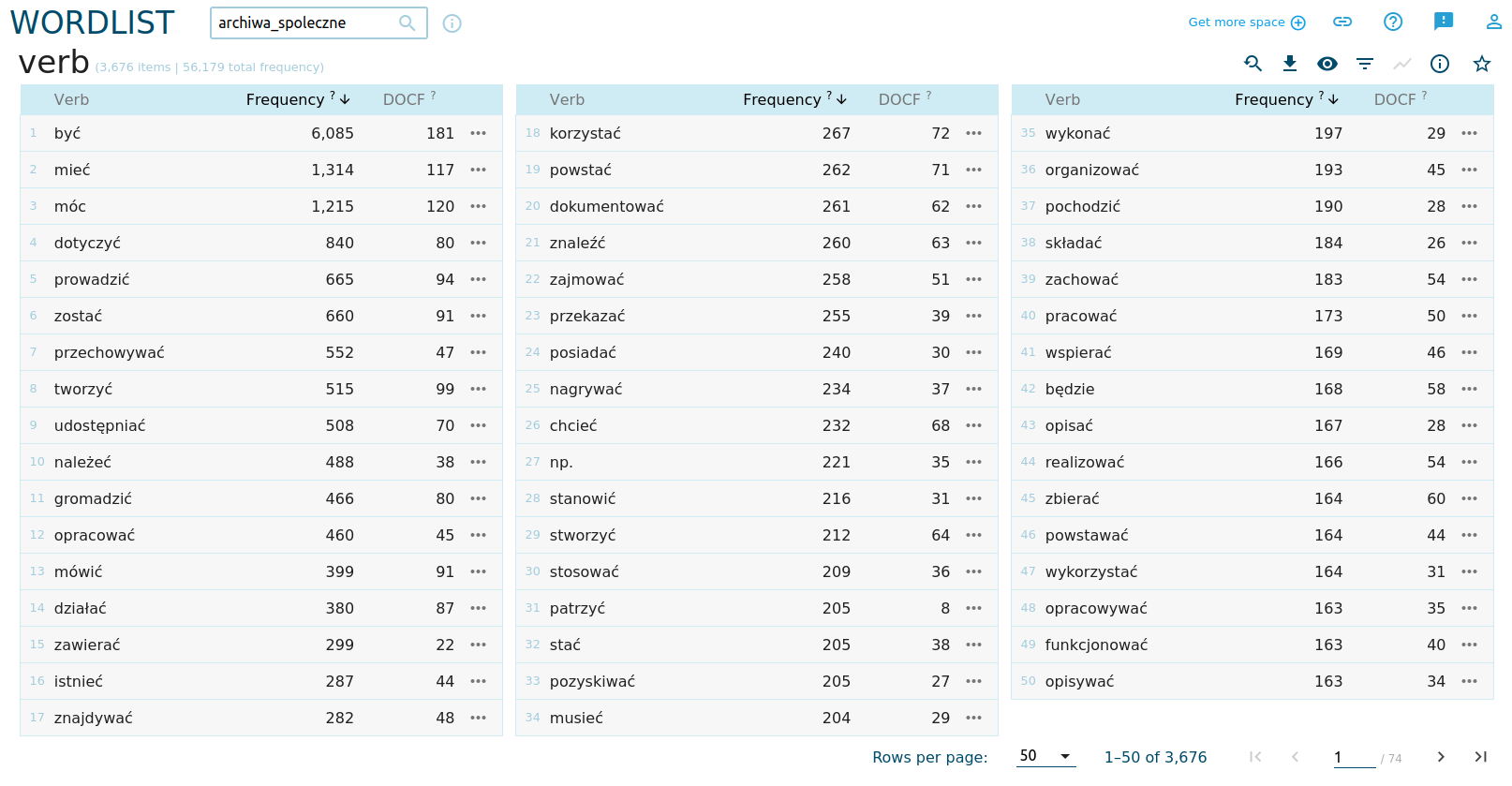
Spróbujmy dowiedzieć się, co archiwa społeczne robią i jakie mogą być aktywności wokół archiwów społecznych. W tym celu zbudujmy listę frekwencyjną, w której analizować będziemy wyłącznie czasowniki: na liście filtrów wybieramy opcję verb i otrzymujemy takie wyniki:
Plik z pełnymi danymi dostępny jest na GitHubie.
Widzimy tutaj przynajmiej kilka interesujących pozycji: wysoka pozycja słowa przechowywać akcentuje fizyczne zabezpieczanie i ochronę zbiorów, pamiętać (pozycja 59) może zwracać uwagę na znaczenie archiwów dla zachowywania pamięci o przeszłości, ale też może na rolę świadków, którzy przekazują archiwom swoje wspomnienia.
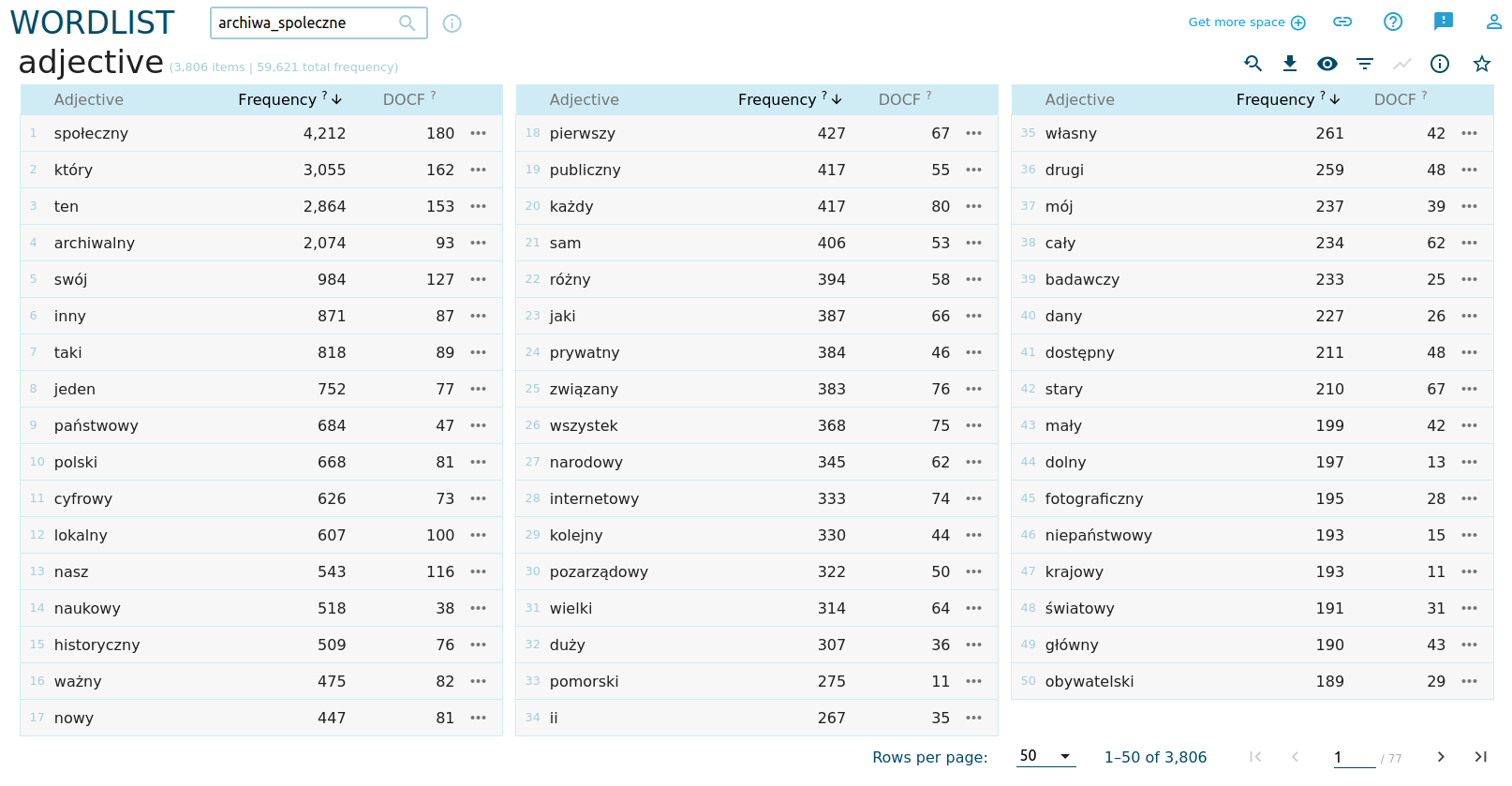
Podobnie wygenerowana lista przymiotników (opcja adjective) da nam następujące wyniki:
Plik z pełnymi danymi dostępny jest na GitHubie.
Widzimy tutaj odwołania do cyfrowej postaci zbiorów archiwów społecznych, ich lokalności (prywatności), oddolnego, obywatelskiego charakteru, dużego znaczenia zbiorów fotograficznych. Znów nie są to cechy, o których byśmy nie wiedzieli lub nie spodziewali się po lekturze definicji archiwów społecznych.
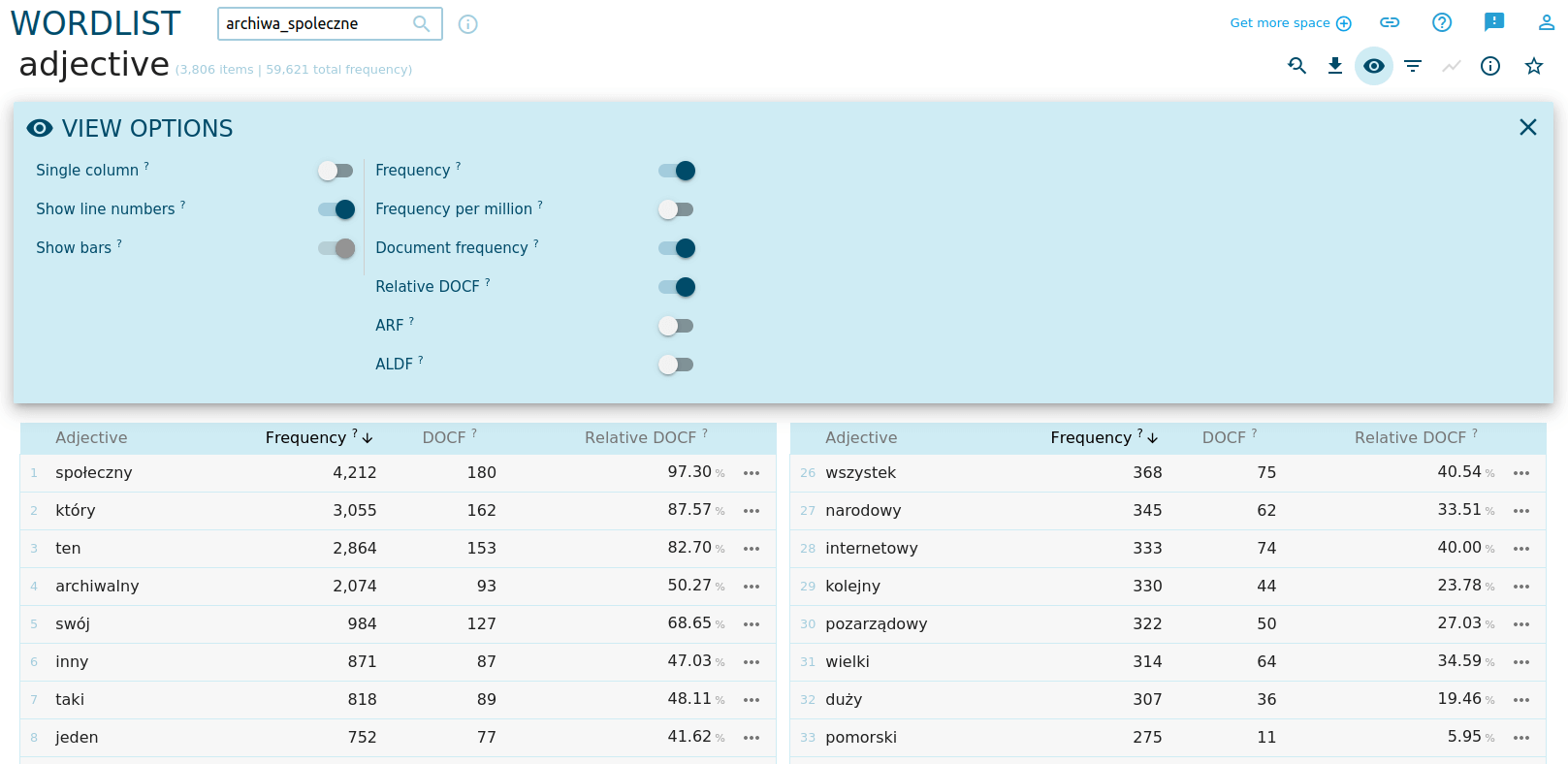
Warto zwrócić uwagę, że na tej liście obok bezwzględnej liczebności wystąpień słowa w korpusie (Frequency) pojawiła się kolumna DOCF. To liczba dokumentów korpusu, w której znajduje się określone słowo. Zwróćmy uwagę na przymiotnik pomorski. Znajduje się on zaskakująco wysoko na liście frekwencyjnej, chociaż występuje tylko w jedenastu dokumentach! Trudno uwzględniać go w ogólnej interpretacji korpusu.
Aby włączyć kolumnę DOCF, wybieramy ikonę oka w prawym górnym rogu ekranu i opcję Document Frequency. Opcja Relative DOCF pozwoli zobaczyć, że przymiotnik pomorski występuje jedynie w 5 proc. dokumentów w tekście.
Konkordancje
Z widoku listy frekwencyjnej możemy bardzo łatwo przejść do widoku konkordancji. Konkordancja to, jak przypomina Victoria Kamasa, to
lista wszystkich wystąpień poszukiwanego terminu w korpusie, zaprezentowaną wraz z kontekstem, w którym termin ten się pojawia
Pozostańmy przy tajemniczym przymiotniku pomorski. Po prawej stronie słowa znajduje się trzykropek, który otwiera menu kontekstowe. Wybieramy z niego opcję Concordance:
W efekcie przechodzimy do widoku listy fragmentów tekstów z naszego korpusu, w których pojawia się ten przymiotnik (w różnych odmianach):
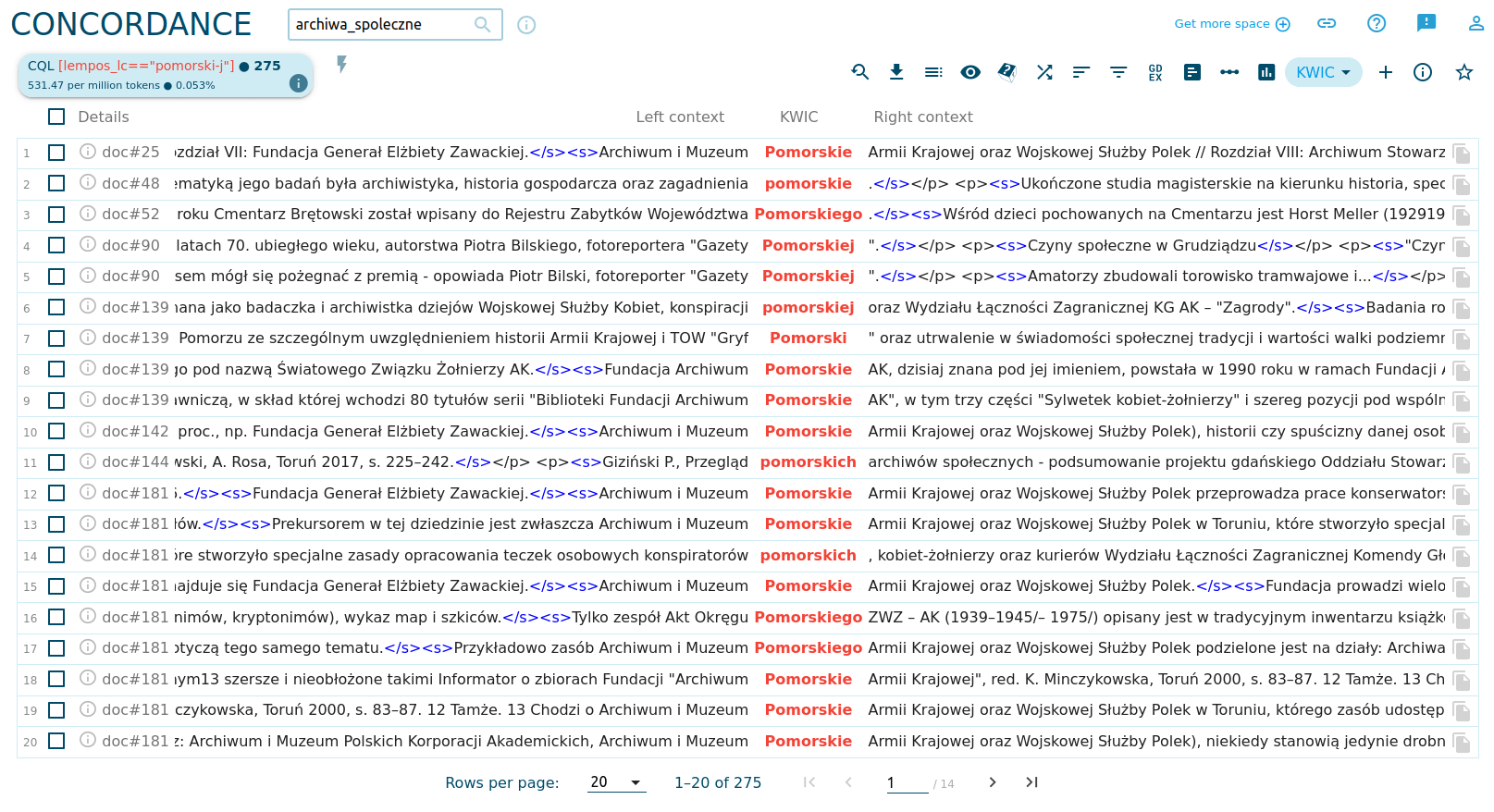
Od razu widzimy, że w korpusie mowa jest o kilku archiwach (nie tylko społecznych), których nazwa zawiera ten przymiotnik. Czy wysoka pozycja przymiotnika pomorski wskazuje na wagę tego regionu dla archiwistyki społecznej w Polsce? Trudno bezpośrednio przekładać liczebność konkretnego słowa na jego znaczenie dla analizowanego tematu - w naszym przypadku pomorski na pewno nie ma takiego znaczenia dla materii archiwów społecznych jak cyfrowy czy choćby fotograficzny. To właśnie miejsce, w którym wygenerowane automatycznie dane musimy krytycznie zinterpretować - wartość analizy polega nie na tym, że te dane uzyskaliśmy (to przecież proste), ale na tym, że byliśmy w stanie odrzucić te, które mogłyby zafałszować obraz badanego tematu.
Cyfrowe archiwa społeczne?
Konkordancje w Sketch Engine są doskonałym narzędziem do badań jakościowych w korpusie. Nie zawsze musi nam zależeć na danych, czasem podstawą naszej pracy może być występowanie wybranego słowa w określonym kontekście. Spróbujmy zrobić to dla słowa cyfrowy:
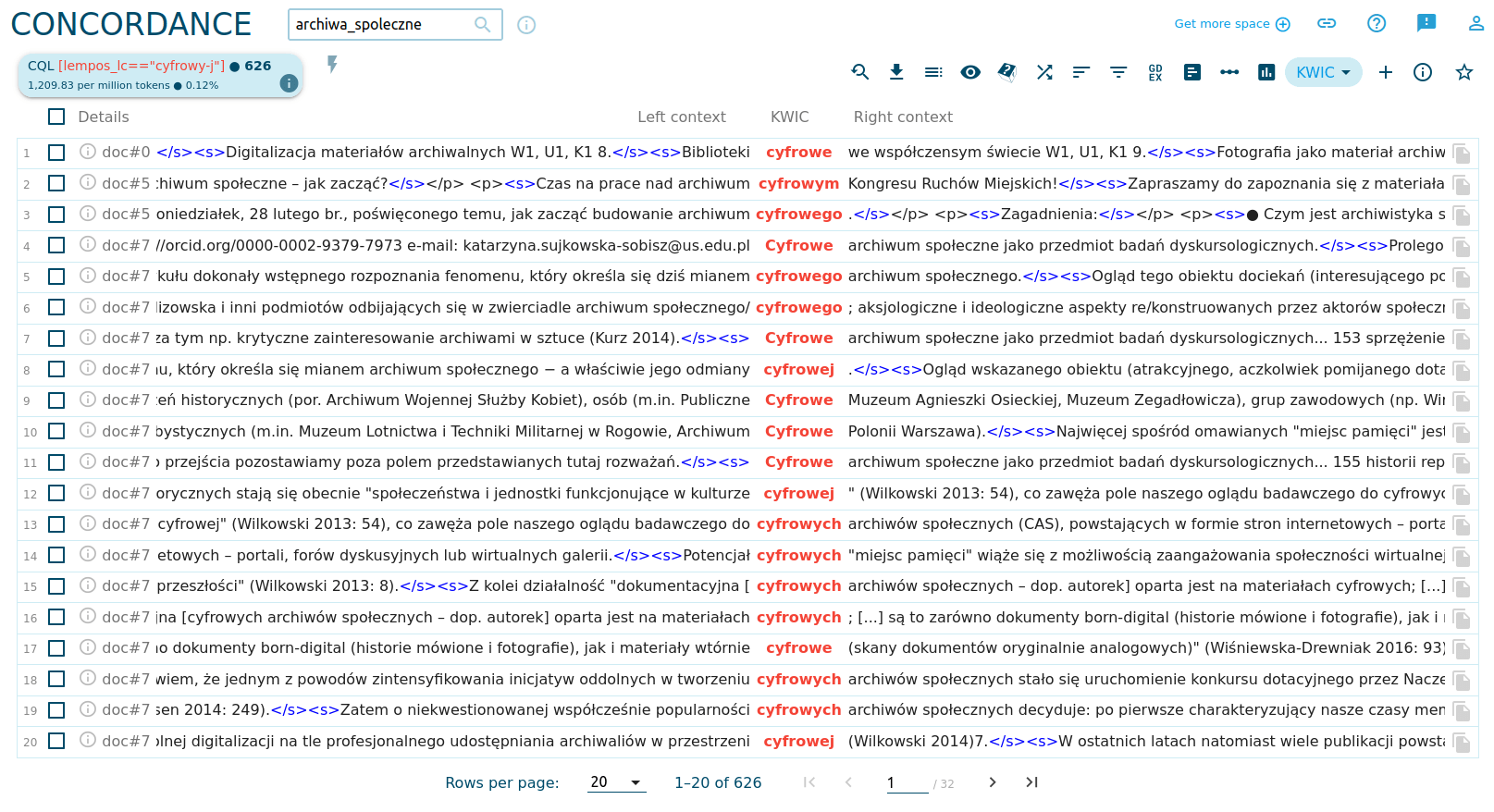
Widzimy, że w literaturze pojawia się pojęcie cyfrowego archiwum społecznego, odniesienia do kultury cyfrowej, cyfrowe miejsca pamięci oraz szereg nazw archiwów społecznych, zawierających słowo cyfrowe, np. Cyfrowe Archiwum Łodzian oraz projekt Cyfrowe Archiwa Tradycji Lokalnej.
W jednym miejscu zebraliśmy treści, które pozwalają nam opisać, czym może być cyfrowość w kontekście archiwów społecznych. Wydaje się, że to nie tylko forma działania tych archiwów (gromadzenie i publikowanie zbiorów w postaci cyfrowej), ale też wykorzystanie internetu jako przestrzeni, w której eksplorować można pamięć i dziedzictwo. Archiwa społeczne funkcjonują też w kulturze cyfrowej, co pozwala nam zadawać pytania np. o to, jakie metody wykorzystują do upowszechniania swoich zbiorów czy o to, jak współczesny internet ułatwia lub utrudnia pracę z historią i dziedzictwem. W pewien sposób wychodzimy tu już poza definicję archiwów społecznych - a może po prostu ją rozbudowujemy.
Oddajmy ponownie głos Victorii Kamasie:
Do zalet analizy konkordancji należy możliwość zbadania kontekstu występowania słów istotnych ze względu na stawiane pytanie badawcze nawet w bardzo dużych korpusach tekstów. Możliwość automatycznego wygenerowania listy wszystkich wystąpień wybranego słowa wraz z jego najbliższym kontekstem znacząco skraca proces analizy, a także podnosi jego stopień trafności (istnieje pewność, że zanalizowane zostały wszystkie wystąpienia danego słowa) i powtarzalności (różni badacze dla tego samego korpusu uzyskają zawsze tę samą listę konkordancji). Poszukiwanie wzorców wśród uzyskanych konkordancji prowadzi badaczy do identyfikacji dominujących dyskursów i sposobów dyskursywnej reprezentacji analizowanych zjawisk. Wadą jest natomiast skupienie się na słowie/słowach, nie zaś problemach, o których w tekście może być mowa, bez użycia wyszukiwanego słowa (np. przy pomocy zaimków).
Porównywanie list frekwencyjnych
Jak pamiętamy z poprzedniej lekcji, nasz korpus składa się z dwóch głównych grup treści: pierwsza to teksty naukowe i edukacyjne (w folderze upload), druga to teksty stron internetowych z wyników wyszukiwania Google (zebrane w katalogu web_sources). Sketch Engine pozwala nam na generowanie list frekwencyjnych nie tylko na podstawie całego korpusu, ale wybranych tekstów. Filtrem może być katalog, w którym je umieścimy, ale też nazwa pliku czy - w przypadku tekstów ściągniętych ze stron internetowych - wybrany element adresu.
Spróbujmy porównać dwie listy frekwencyjne dla wybranych treści. Znów - zrobimy to przede wszystkim po to, żeby zobaczyć, jak budować filtry list frekwencyjnych, a nie w celu znalezienia odpowiedzi na jakieś pytania badawcze.
Najpierw przygotujemy listę frekwencyjną z treści Podręcznika dla archiwistów społecznych (2023) opublikowanego przez Centrum Archiwistyki Społecznej. W tym celu w widoku zaawansowanych ustawień Wordlist klikamy w Text types i w panelu File name wybieramy nazwę pliku Podrecznik-dla-archiwistow-spolecznych-CAS.pdf:
Podobnie wygenerujmy listę frekwencyjną dla tekstów z portalu Histmag - tym razem używamy filtra Domain name. W efekcie otrzymamy dwie listy, które można porównać (są też dostępne na GitHub). Porównanie przygotowane za pomocą narzędzia DiffChecker pierwszych 50 słów na obu listach wykazało, że:
- w podręczniku wśród najczęściej pojawiających się słów znalazły się zbiór, materiał, fotografia, osoba, dokument czy cyfrowy. Słowa te nie pojawiły się w pierwszej pięćdziesiątce listy frekwencyjnej z tekstów Histmaga o archiwach społecznych,
- na Histmagu pojawiły się na pierwszych 50 miejscach listy frekwencyjnej (a nie pojawiły się na takiej liście wygenerowanej dla podręcznika) słowa takie jak dziedzictwo, instytucja, lokalny, kultura, archiwistyka. Na liście znalazła się także reklama, ale najpewniej możemy to słowo zignorować, bo do korpusu automatycznie pobraliśmy całą treść strony, w tym nagłówki, reklamy czy tekst stopki redakcyjnej (to duża wada automatyczego importu stron do Sketch Engine).
Na GitHubie dostępne są listy frekwencyjne dla podręcznika i tekstów z portalu Histmag.
Jeśli spróbujemy to jakoś zinterpretować, możemy zauważyć, że tekst podręcznika opisuje materię pracy archiwów społecznych (stąd pojęcia takie jak zbiór, dokument czy materiał), a artykuły na Histmagu podkreślają specyfikę działania tych archiwów (lokalny, archiwistyka) i odwołują się do określonych wartości (dziedzictwo, kultura).
Pamiętajmy, że nasze porównanie bazuje wyłącznie na pierwszych pięćdziesięciu słowach z list frekwencyjnych - to filtr nałożony zupełnie arbitralnie. Jeśli chcielibyśmy wykorzystać takie porównania w pracy badawczej czy analitycznej, konieczne byłoby bardziej uważne zanalizowanie obu list, np. zidentyfikowanie kategorii, do których przypisywać będziemy wybrane słowa. Zebrane z obu list słowa w kategoriach takich jak wartości, metody, odbiorcy, cele możnaby ze sobą zestawić i sprawdzić, jaki obraz archiwów społecznych budują.
Podsumowanie
W tej lekcji udało się nam poznać wyłącznie dwie metody pracy z korpusami - generowanie i analizowanie list frekwencyjnych i konkordancji (ale wyłącznie dla jednego słowa). W kolejnej lekcji poznamy inne metody, pozwalające głębiej przeglądać treść korpusu.
Praca ze Sketch Engine nie jest trudna, więcej kłopotów sprawia odpowiednie przygotowanie korpusu i interpretacja danych. Podstawą takiej pracy musi być jednak konkretny pomysł badawczy - musimy wiedzieć, czego szukamy i na jakie pytania chcemy zebrać odpowiedzi.
Wykorzystanie metod
W artykule Victorii Kamasy znajdziemy wiele przykładów wykorzystania korpusów w analizach. Przykładowo,
takie dane [z list frekwencyjnych] zostały wykorzystane na przykład przez Chen (2012) w badaniach dotyczących wpływu zmian politycznych w Chinach na prasę. Wpływ ten jest obserwowany przez częstotliwość użycia pozytywnie i negatywnie nacechowanych oraz neutralnych słów porównujących w diachronicznym korpusie artykułów prasowych. Z kolei Mohamad i współpracownicy (2012) wykorzystali listy frekwencyjne stworzone dla dwóch subkorpusów tekstów z podręczników do matematyki do porównania reprezentacji płci w anglojęzycznych podręcznikach wydawanych w Katarze i poza jego granicami. Analiza częstotliwości występowania wybranych zaimków, nazw zawodów czy określeń pokrewieństwa umożliwiła autorom odpowiedź na pytanie dotyczące poziomu seksizmu w obu grupach podręczników.
W artykule Brand Personality Traits of World Heritage Sites: Text Mining Approach autorzy i autorki zanalizowali korpus zawierający ponad 5.5 tys. opinii na temat Obiektów Światowego Dziedzictwa UNESCO, aby wskazać, na jakich wartościach budowana jest marka tych miejsc.
Pomysł na warsztat
Prostym warsztatem, który zrealizować można nawet bez korzystania z narzędzi takich jak Sketch Engine czy Excel jest zbudowanie list frekwencyjnych z kilkunastu-kilkudziesięciu clickbaitowych tytułów artykułów z popularnych portali. Niech teksty te dotyczą historii lub dziedzictwa - dobrym źródłem jest tutaj portal Ciekawostki historyczne.
Uczestników i uczestniczki warsztatów podzielić można na grupy, analizujące wybrane części mowy (np. rzeczowniki, przymiotniki, czasowniki) - niech każda grupa opisze dominujące słowa w analizowanych tekstach w kilku kategoriach (np. tematu, emocji, odniesień do wiedzy historycznej). Po skończonej analizie grupy mogą zapronować wspólnie przepis na clickbait historyczny, odwołując się do badanych przykładów.
Taki warsztat zorganizować można ze wsparciem aplikacji Voyant Tools, która nie wymaga zakładania konta i logowania. Jej ograniczeniem jest jednak brak możliwości lematyzacji analizowanych słów.


