
Wprowadzenie
W poprzedniej lekcji poznaliśmy dwie metody analizy korpusowej: listy frekwencyjne i konkordancje. W kolejnej części opracowania na temat podstaw pracy ze Sketch Engine zajmiemy się budową zaawansowanych konkordancji oraz analizą i wizualizacją kolokacji.
Cele lekcji
Celem lekcji jest poznanie kolejnych metod analizy korpusowej w aplikacji Sketch Engine.
Efekty
Bezpośrednim efektem są będą dane i treści uzupełniające ogólną definicję archiwów społecznych (i archiwistyki społecznej). Nasze analizy nie mają charakteru naukowego i koncentrować się będziemy przede wszystkim na praktyce korzystania ze Sketch Engine.
Wymagania
Aby skorzystać z tej lekcji, należy zapoznać się z poprzednimi lekcjami z cyklu:
- Jak się pisze o archiwach społecznych? Budujemy korpus!
- Jak się pisze o archiwach społecznych? Analizujemy korpus!
Niezbędne jest także założenie konta w Sketch Engine.
Część merytoryczna
Tematem, który analizować będziemy w naszej pracy, są archiwa społeczne. Analiza korpusowa pozwala nam zbadać to, w jaki sposób definiuje się archiwa społeczne i jakie wartości się z nimi identyfikuje. Może to być badanie jedynie uzupełniające uważną lekturę podręczników, monografii i tekstów publikowanych na stronach internetowych.
Nie zawsze jednak objętość treści przeznaczonych do analizy pozwala na samodzielne, ręczne zapoznanie się z nimi - analiza korpusowa może być wtedy jedyną szansą na poznanie najważniejszych cech dużego zbioru tekstów. Czytanie zdystansowane (distant reading) - termin zaproponowany przez Franco Morettiego - może być szansą na podjęcie badań jak najszerszej, inkluzywnej grupy tekstów i wypowiedzi. Moretti opisuje to na przykładzie badań XIX-wiecznych powieści: po co, badając literaturę światową, ograniczać się wyłącznie do kanonu i wybranych, dominujących literatur narodowych, skoro metody komputerowe pozwalają przeczytać o wiele więcej?
Zaawansowane ustawienia konkordancji
Wróćmy do naszego badania. Przypomnijmy za artykułem Victorii Kamasy, że konkordancja to
lista wszystkich wystąpień poszukiwanego terminu w korpusie, zaprezentowaną wraz z kontekstem, w którym termin ten się pojawi
Jeśli na konkordancję spojrzymy zupełnie technicznie, to kontekst jest po prostu liczbą słów, które poprzedzają wybrane słowo (termin) i które za nim występują. Sketch Engine pozwala w prosty sposób ustawiać metody generowania konkordancji. Spróbujmy przygotować prostą konkordancję dla słowa digitalizacja. Zależy nam na uwzględnieniu wszystkich odmian tego słowa, dlatego zastosujemy formę słownikową:
W efekcie otrzymamy listę 218 wystąpień tego słowa w całym korpusie. W widoku Concordance, ale też w plikach eksportu CSV lub XLSX znajdziemy wyróżnione słowo wraz z prawym i lewym kontekstem.
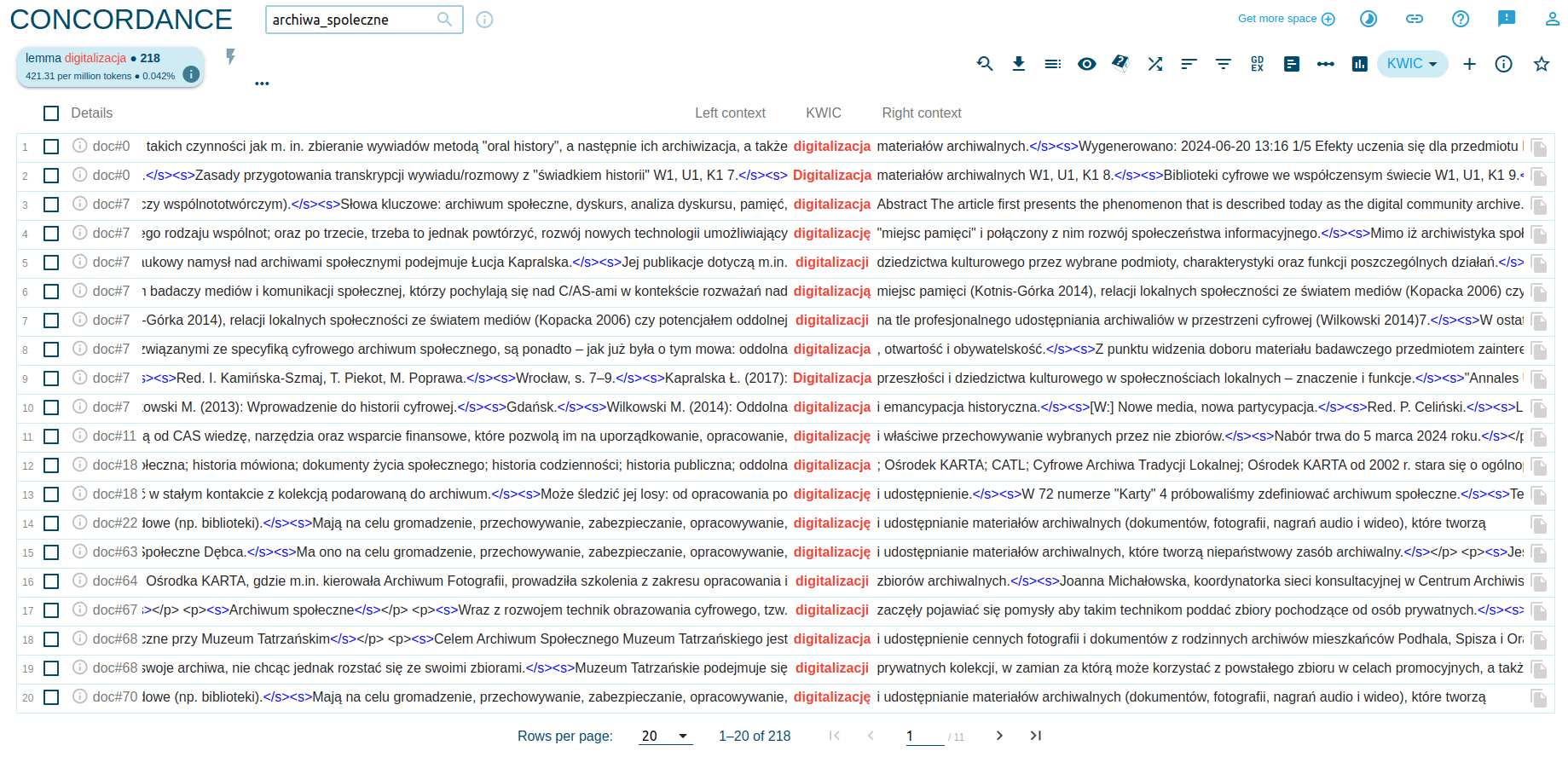
Możliwość eksportu konkordancji to duże ułatwienie w badaniach jakościowych - zamiast samodzielnie wyszukiwać określone słowa lub frazy, możemy w łatwy sposób wygenerować ich zestawienie i samodzielnie opisać, np. przypisując każde wystąpienie badanego słowa do wcześniej wypracowanych kategorii.
Sketch Engine pozwala filtrować wygenerowane konkordancje tak, aby zawierały wyłącznie zdania z określonymi słowami, oraz oczywiście z podstawowym słowem, na bazie którego wygenerowaliśmy zestawienie. W słowniku aplikacji Sketch Engine takie słowo to KWIC (Key Word in Context).
Aby przygotować filtry do konkordancji, wybieramy ikonę Filter (wśród ikonek w prawej górnej części strony). Załóżmy, że interesować nas będą tylko te wystąpienia słowa digitalizacja, w których pojawia się także słowo fotografia. Ustawiamy filtr dla formy słownikowej (lemma) i dla rzeczownika (fotografia, ale już nie fotograficzny). Wybieramy też zasięg (opcja Range), aby nasze zestawienie zawierało słowo fotografia w odległości najwyżej jednego zdania od zdania zawierającego słowo kluczowe (KWIC):

Po przefiltrowaniu zestawienia, otrzymamy 48 elementów - listę oczywiście możemy wyeksportować do pliku w wybranym formacie.
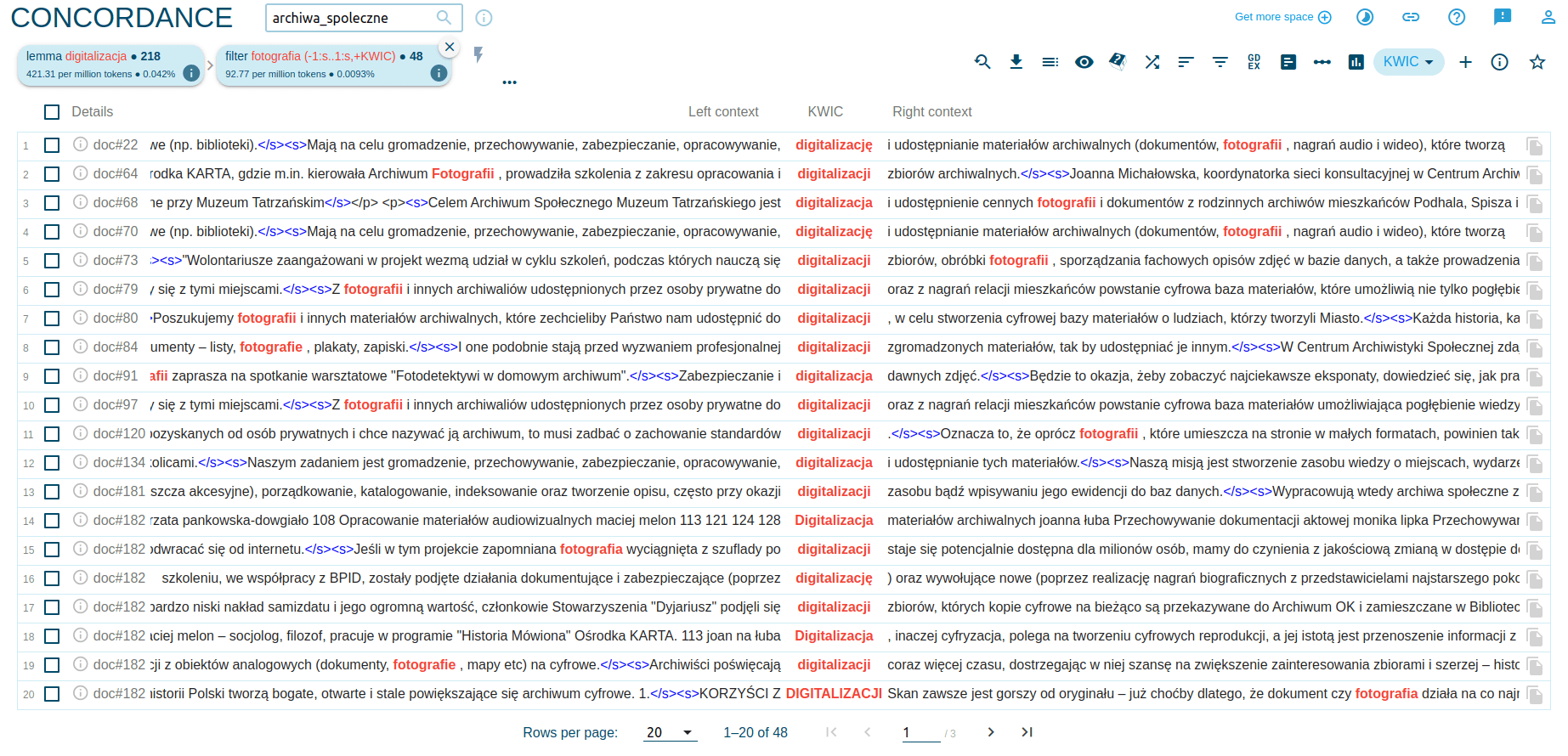
Dzięki Sketch Engine możemy wygodnie przygotować materiały np. do przeglądu literatury naukowej. W kontekście naszego badania archiwów społecznych, dzięki wygenerowanej w ten sposób konkordancji, możemy sprawdzać, czy fotografia nie jest dominującą postacią zbiorów, które digitalizują (lub miałyby digitalizować) archiwa społeczne. Oczywiście nie chodzi tutaj o dane statystyczne ale pewne akcenty w narracji na temat działalności archiwów.
Analiza kolokacji
Kolokacja jest przez badaczy KAD [Korpusowej Analizy Dyskursju - przyp. MW] definiowana zgodnie z tradycją językoznawstwa korpusowego jako częste współwystępowanie (Stubbs 2001). Dla wybranego słowa określa się więc zasięg (ang. span), a następnie przy pomocy oprogramowania wykorzystującego określone miary statystyczne (test t, wskaźnik MI i inne) generuje się listę słów występujących istotnie częściej w określonym zasięgu od słowa bazowego.
— pisze Victoria Kamasa. Kolokacją jest na przykład samo pojęcie archiwów społecznych, ale też połączenia mniej oczywiste (digitalizacja dziedzictwa, fotografie historyczne) lub nawet zaskakujące (archiwum obywatelskie czy amatorska digitalizacja). Dane na temat kolokacji w korpusie generujemy za pomocą narzędzia Word Sketch:
W efekcie otrzymamy listę kolokacji dla rzeczownika archiwum i jego odmian:
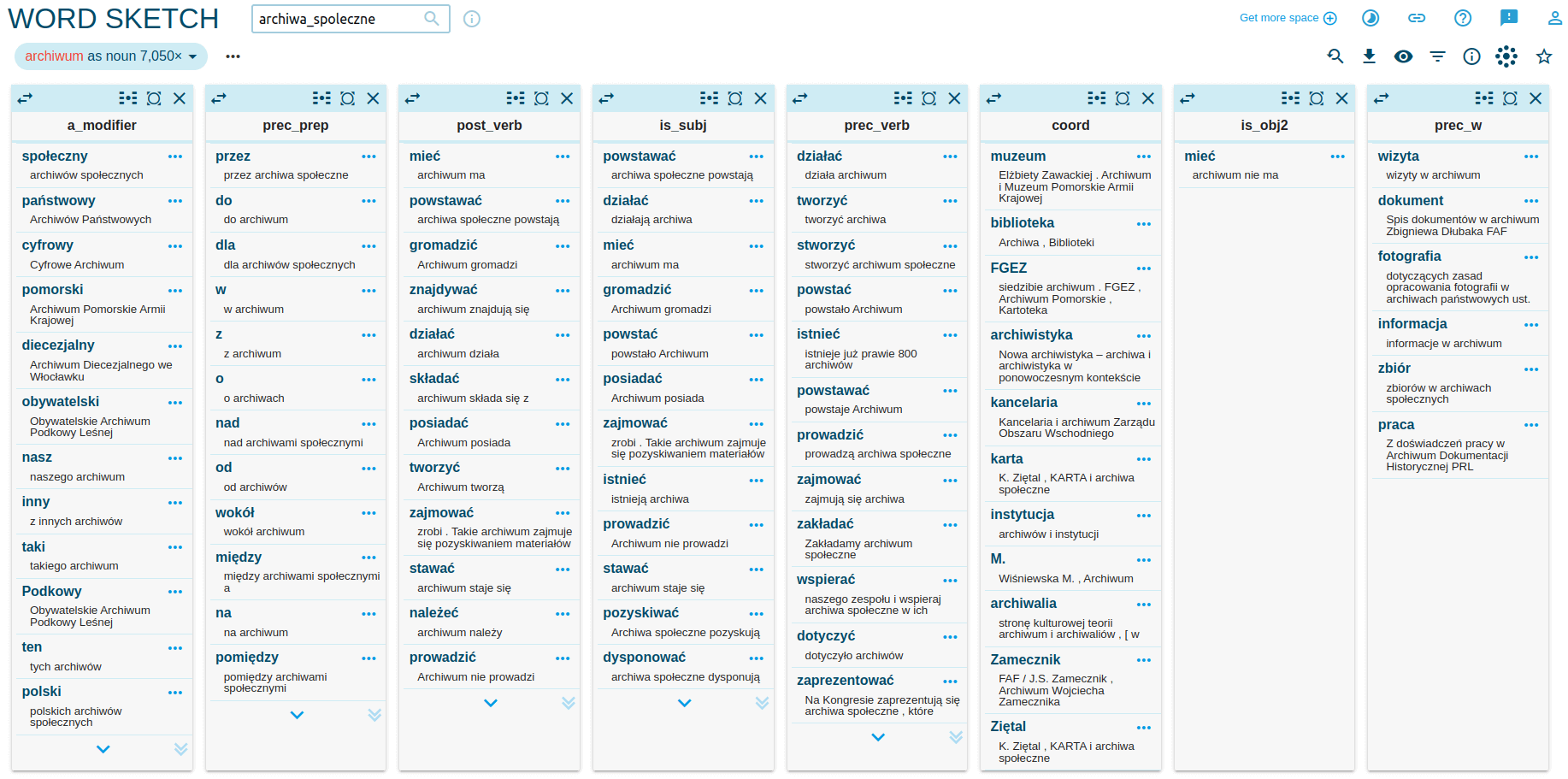
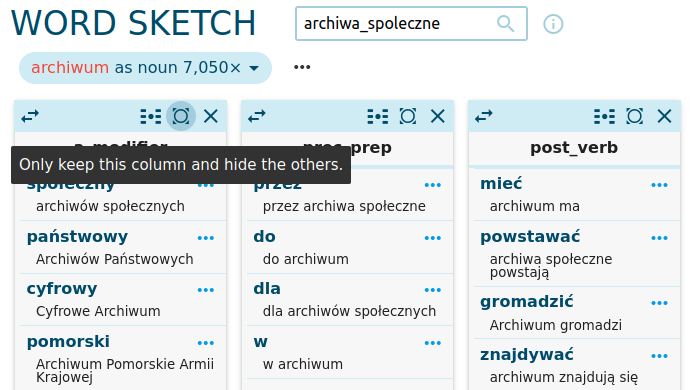
W systemie Sketch Engine kolokacje wydzielane są na podstawie typów relacji, jakie występują między słowem kluczowym i drugim słowem w kolokacji. Przykładowo, relacje w kolumnie post_verb opisywać będą połączenia między słowem kluczowym archiwum i występującym za nim czasownikiem (archiwum powstaje, archiwum gromadzi, archiwum pozyskuje), a relacje w kolumnie prec_verb mogą opisywać czynności, których archiwum jest podmiotem (to połączenia czasownik + słowo kluczowe), np. stworzyć archiwum, prowadzić archiwum, wspierać archiwum. W kolumnie is_subj mamy natomiast zestawienia, w którym słowo kluczowe archiwum jest podmiotem w zdaniu. Jak widać, te same kolokacje mogą pojawiać się w różnych kolumnach.
W kolumnie a_modifier znajdują się kolokacje, w których słowo archiwum jest poprzedzone jakimś modyfikatorem, np. przymiotnikiem. Znajdziemy tutaj wiele propozycji alternatywnych czy równoległych dla archiwów społecznych określeń tego typu oddolnej działalności: archiwum domowe, archiwum prywatne, archiwum niezależne, archiwum osobiste. W naszym badaniu moglibyśmy analizować relacje między pojęciem archiwum społecznego a tymi określeniami: w jaki sposób oddają one istotę archiwum społeczego? Jakie różnice są między nimi?
Zwróćmy uwagę, że z jednego zestawu kolokacji bardzo łatwo wygenerować kolejny. Zbadajmy kolokacje, w ktorych funkcjonuje zbitka archiwum społeczne i jakieś dodatkowe słowo. Aby to zrobić, klikamy w trzykropek po prawej stronie wybranej frazy. W podobny sposób możemy wygenerować konkordancję, która pokaże nam frazę archiwum społeczne w określonym kontekście.
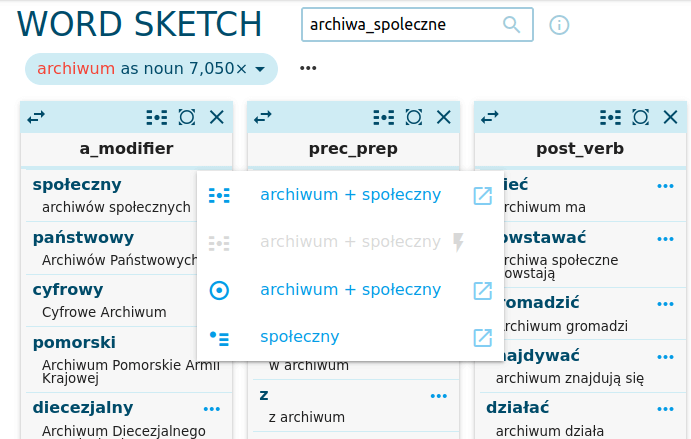
Taka lista kolokacji pokaże nam np. aktywności, które - w analizowanych tekstach - łączy się z archiwami społecznymi:
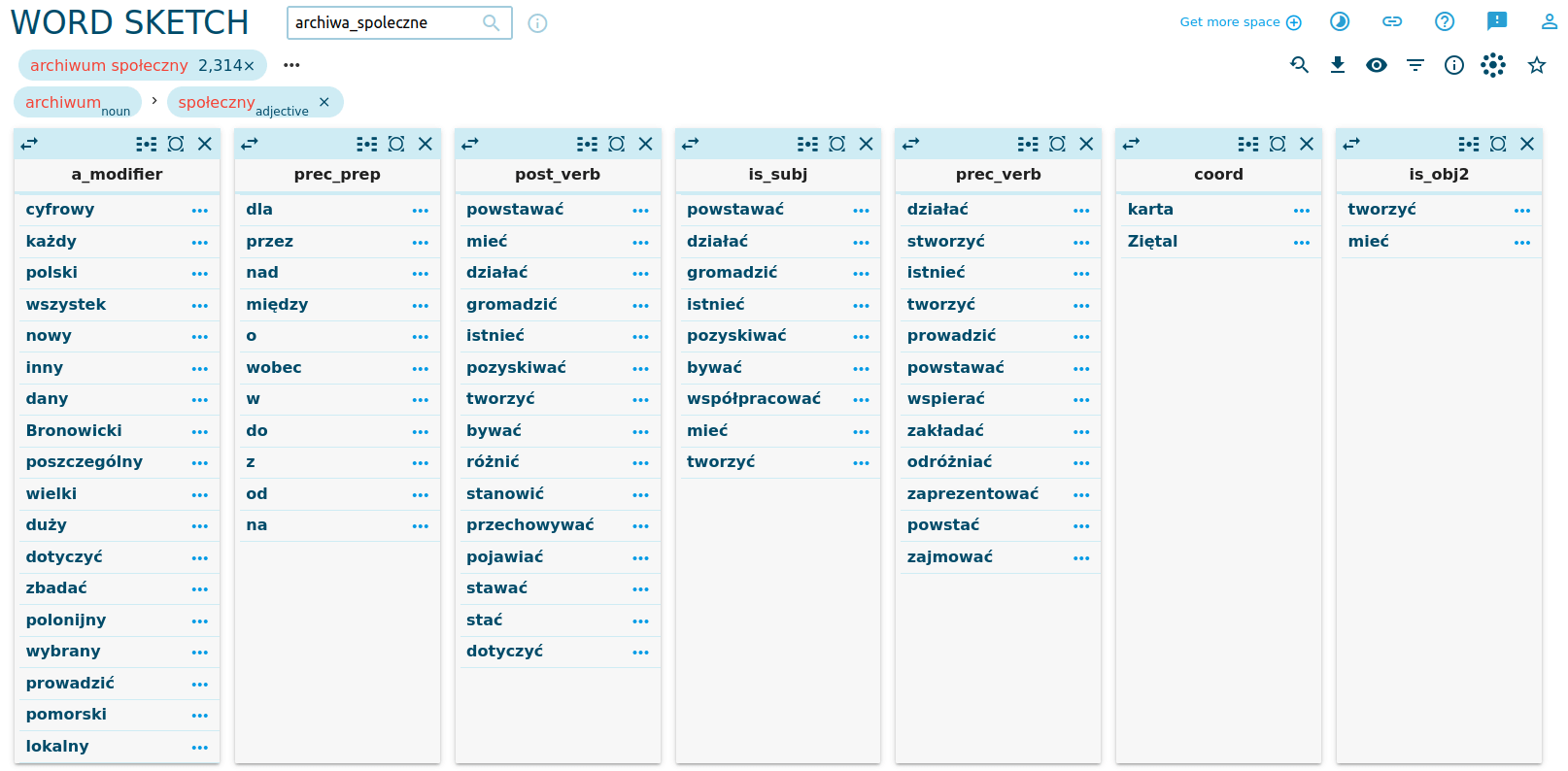
Spójrzmy na kolumny kolokacji post_verb, is_subj i prec_verb: archiwum społeczne może powstawać (być zakładane), ale może też działać, gromadzić, pozyskiwać. Czy nasz korpus mówi przede wszystkim o zakładaniu / tworzeniu archiwów społecznych, czy raczej opisuje ich działania? Aby to sprawdzić, wybierzmy ikoną Change view options opcję Show scores, wskazującą jak silne są dane kolokacje.
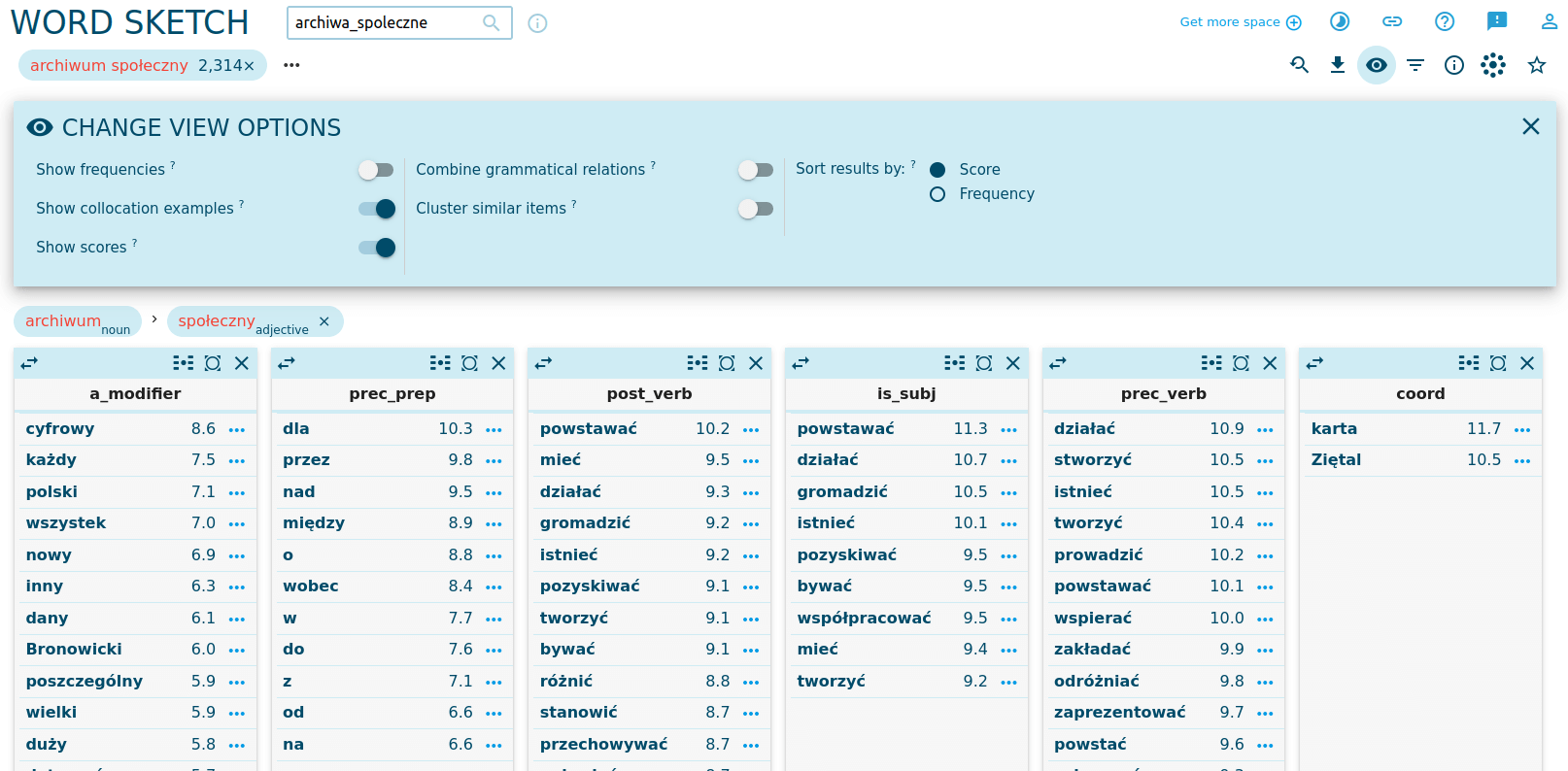
Wydaje się, że nasz korpus podobnie intensywnie opisuje tworzenie archiwów jak ich działalność. A jak powstają archiwa społeczne? Dowiedzmy się tego, generując konkordancję:
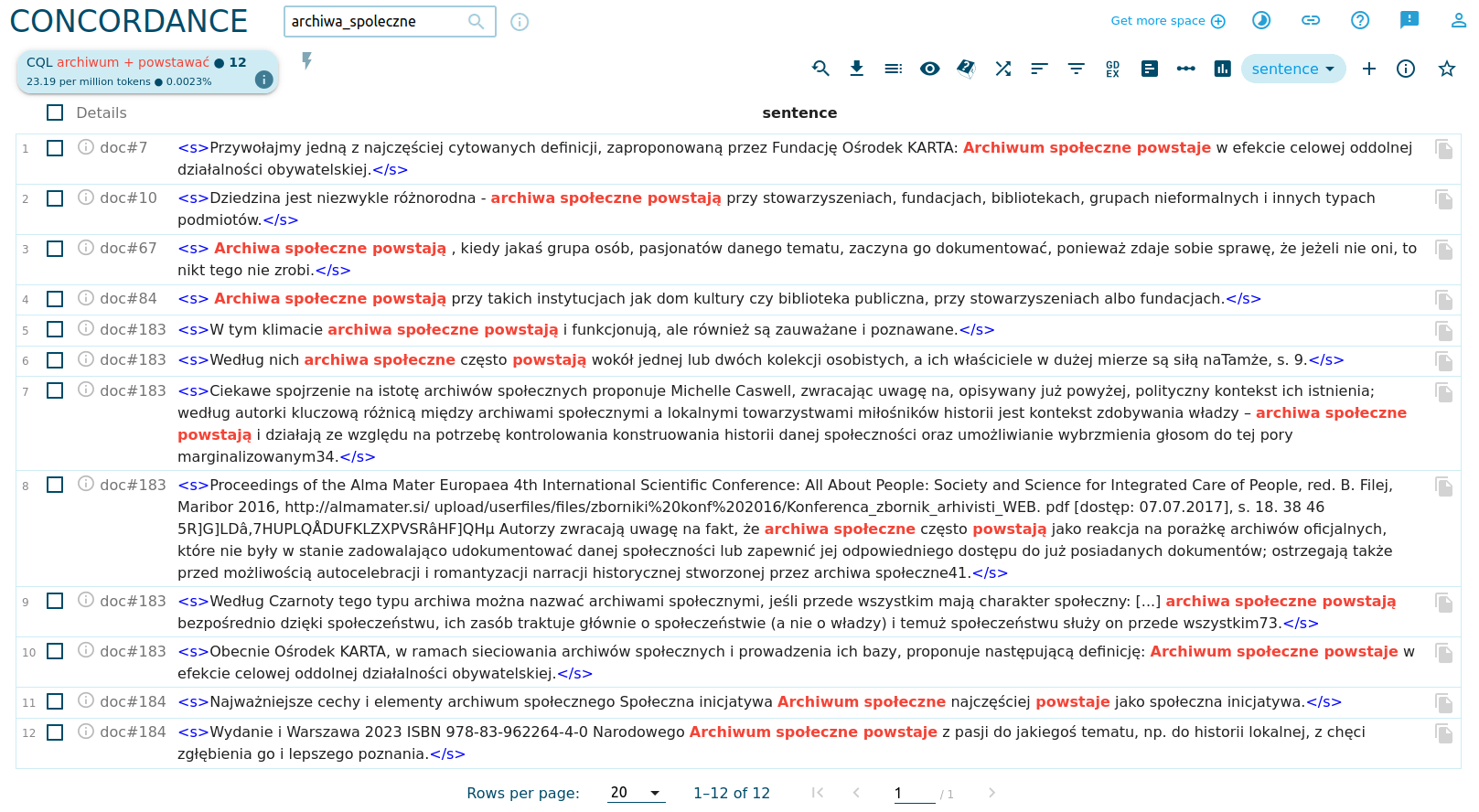
Wizualizacja kolokacji
Wygenerujmy teraz ponownie listę kolokacji dla rzeczownika archiwum. W kolumnie a_modifier znajdziemy kolokacje, które wskazują na to, w jakim archiwalnym kontekście opisuje się archiwa społeczne. Możemy analizować relacje między archiwami społecznymi a państwowymi, znaczenie archiwów cyfrowych, prywatnych czy zakładowych oraz archiwów prowadzonych przez konkretne instytucje takie jak Ośrodek KARTA czy Kościół Katolicki (np. archiwa diecezjalne).
Wybierając jedną z ikon w nagłówku kolumny możemy ukryć pozostałe kolumny z listami kolokacji:
Następnie klikamy ikonę Show visualization i w efekcie otrzymujemy podstawową wersję wizualizacji:

Odpowiednio modyfikując widocznością kolumn z różnymi kategoriami kolokacji, możemy tworzyć bardziej skomplikowane zestawienia:
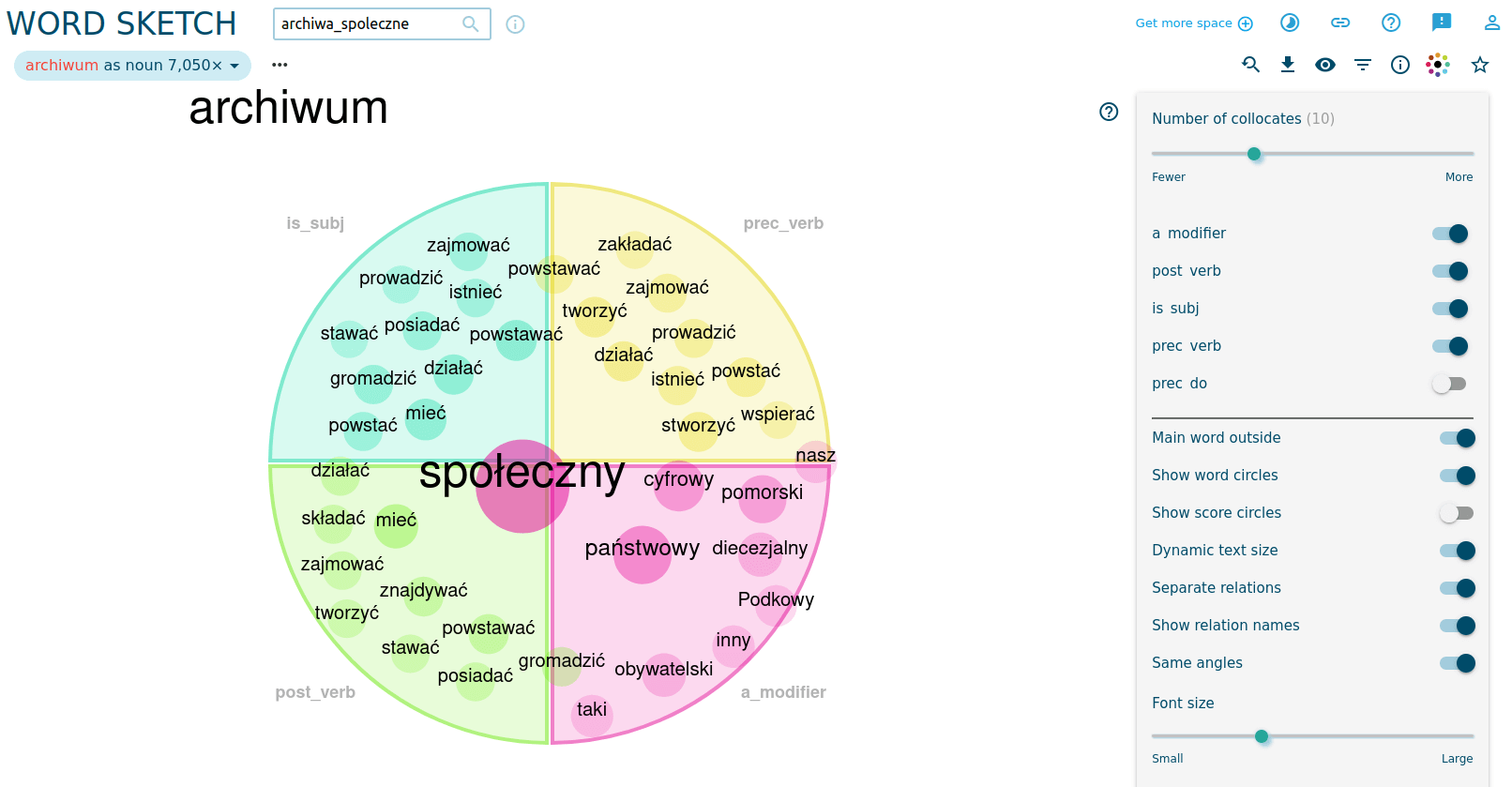
Jak widzimy, na wizualizacji przedstawione są cztery kategorie kolokacji oraz wyróżnione dominujące połączenia. Pamiętajmy jednak, że wizualizacja nigdy nie jest neutralna - to zawsze jakaś interpretacja danych. Za pomocą ustawień zaawansowanych możemy dopracować naszą wizualizację i przy prezentacji na konferencji odpowiednio opisać znaczenie poszczególnych elementów. Wizualizację pobrać możemy na dysk w postaci plików SVG, PNG lub PDF.
Oczywiście, generowanie i prezentowanie takich wizualizacji ma sens tylko wtedy, kiedy możemy je odpowiednio opisać - w tekście albo podczas wystąpienia na konferencji.
Generowanie listy N-gramów
N-gramy to sekwencje n elementów z danego ciągu tekstowego, gdzie n oznacza liczbę elementów w sekwencji. Połączenie archiwa prowadzą to 2-gram (bigram), archiwa prowadzą warsztaty to 3-ngram (trigram) itd. O możlwościach i pułapkach analizy n-gramów mówiliśmy już w jednej z poprzednich lekcji.
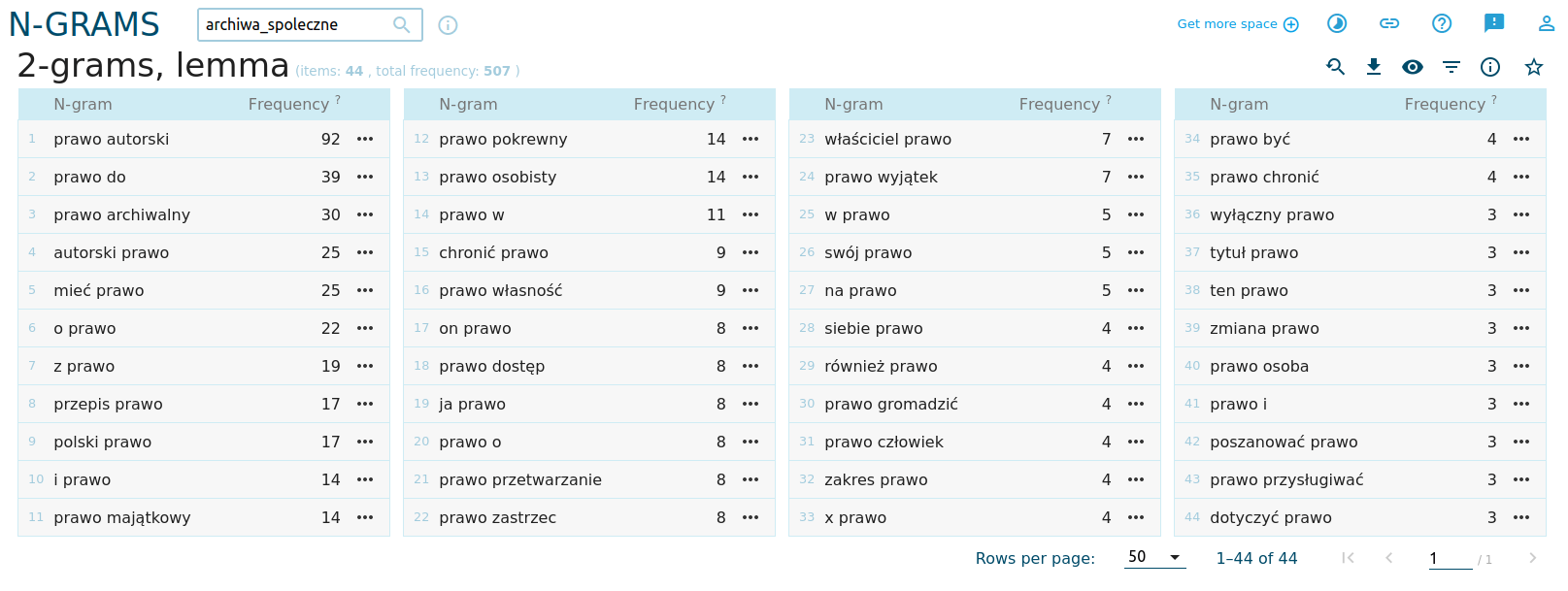
Archiwa społeczne, nawet jako projekty oddolne, muszą funkcjonować w granicach prawa. Spróbujmy zbadać, jakie prawo (jakiego rodzaju przepisy) dotykają materii archiwów społecznych. W tym celu wygenerujmy sobie listę bigramów, zawierających słowo prawo:
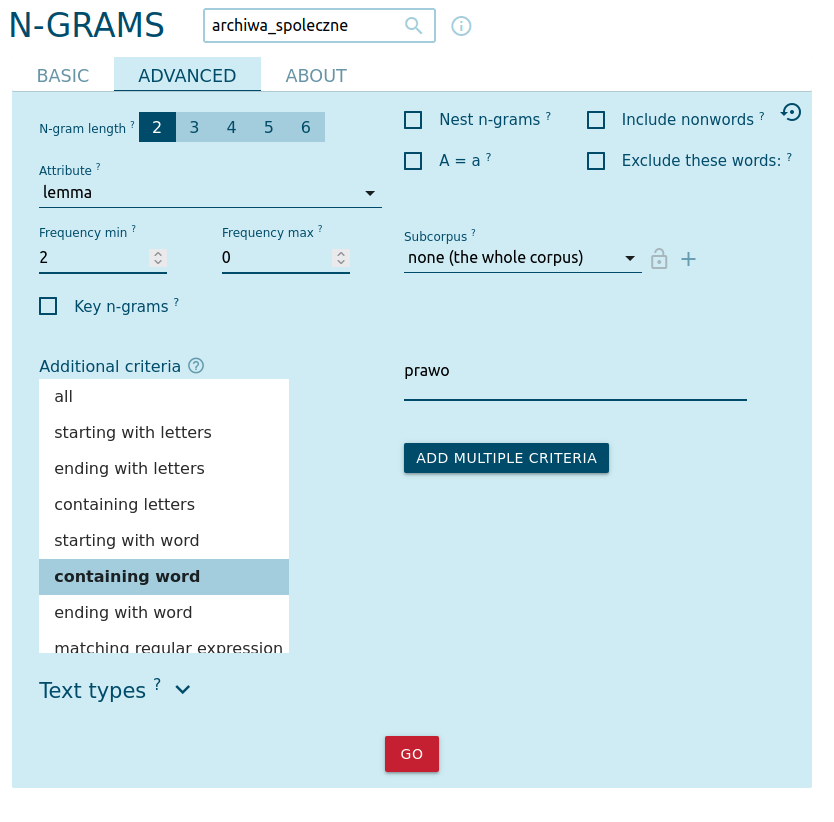
W efekcie otrzymamy listę bigramów z informacją o ich liczebności. Wydaje się, że to przede wszystkim prawo autorskie stanowi wyzwanie dla archiwów społecznych (a nie np. prawo archiwalne).
Podobne dane pozyskalibyśmy generując zestaw kolokacji dla słowa prawo:
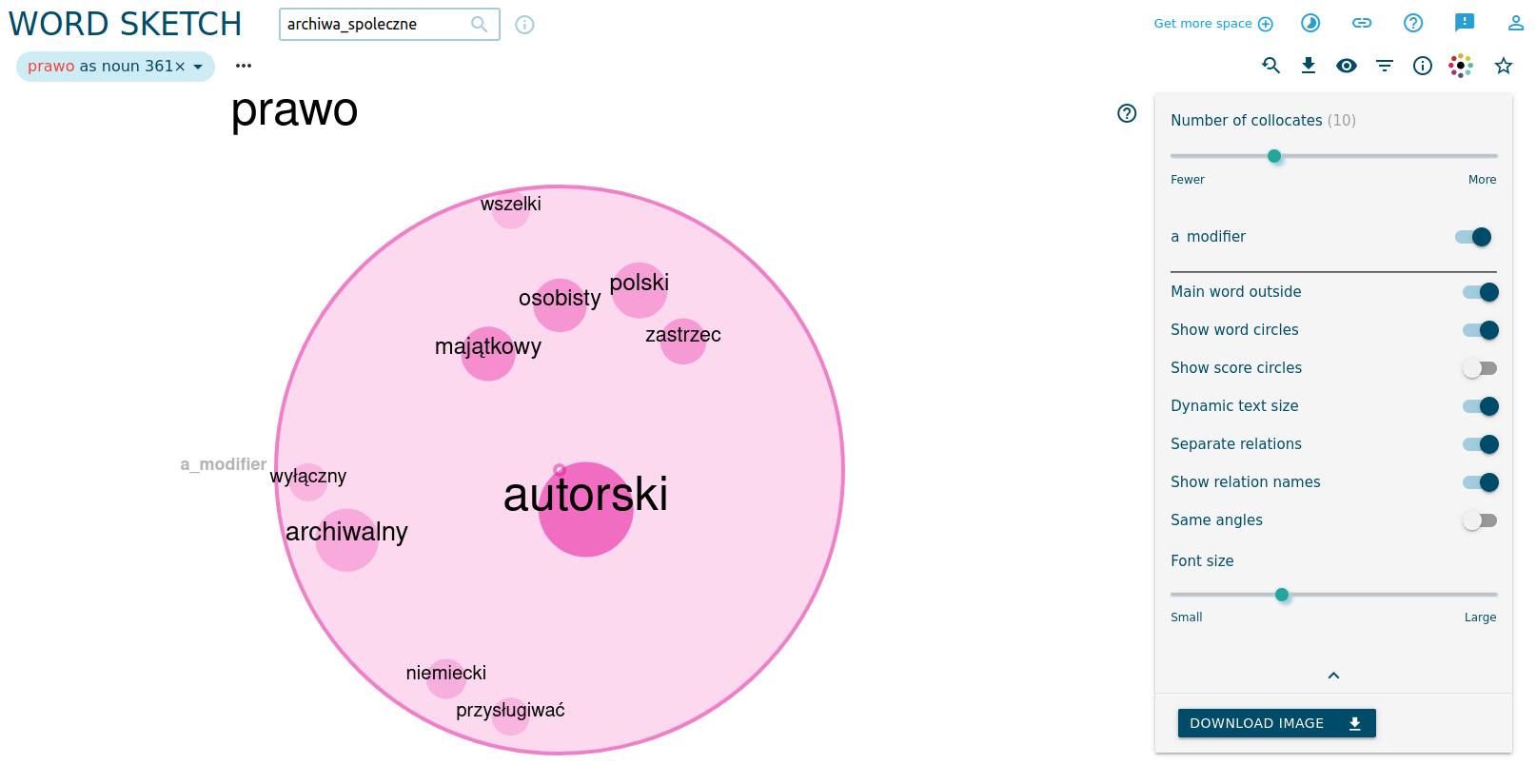
Jak widać, w narracji o archiwach społecznych prawo autorskie zajmuje ważne miejsce. Znów oczywiście konieczne jest krytyczne spojrzenie na wygenerowane dane: słowo zastrzec (jak możemy to zobaczyć w konkordancji) to fraza z informacji o licencji Creative Commons i innych oznaczeń praw autorskich (np. w stopce analizowanych stron). Powinniśmy usunąć te frazy już na etapie przygotowywania tekstów do korpusu.
Podsumowanie
Sketch Engine to aplikacja udostępniająca bardzo wiele narzędzi, użytecznych nie tylko w analizach językowych, ale też zwykłej pracy badawczej z tekstami. Nie są to jednak narzędzia, które same z siebie wygenerują dla nas określoną wiedzę. Dlatego fundamentalne jest nie tylko odpowiednie przygotowanie korpusu, ale też wypracowanie odpowiednich pytań badawczych lub zestawów treści, które mogą być realnie przydatne w analizie jakościowej.
W naszych opracowaniach Sketch Engine bardziej potwierdzał podstawowe intuicje na temat archiwów społecznych niż proponował jakieś nowe spojrzenia. Nie prowadziliśmy tu jednak badania naukowego, ale ćwiczenia z metod udostępnianych przez tę aplikację.
Wykorzystanie metod
Czytanie zdystansowane (distant reading) to nie tylko metoda umożliwiająca analizę olbrzymich zbiorów tekstów, ale przede wszystkim takie podejście badawcze, w którym za cenę rezygnacji z pewnego rodzaju dokładności i pewności, łączącej się z uważną, ręczną analizą, jesteśmy w stanie zbadać naprawdę szeroki wycinek rzeczywistości. Moretti opisywał ten efekt w kontekście światowej literatury, natomiast Thomas Smits i współautorzy - w kontekście obiegu ikonicznych fotografii historycznych w internecie:
Jak media cyfrowe wpływają na interpretację ikonicznych fotografii? Ostatnie badania sugerują, że obieg online, zwłaszcza w formie memów, może prowadzić do erozji, złamania lub zniszczenia oryginalnego kontekstu ikonicznych obrazów. […] Twierdzimy, że możemy wykorzystać metody czytania zdystnansowanego do szerokiej analizy interakcji między ikonicznymi fotografiami a tekstem i zidentyfikować, w jakich kontekstach ikoniczne fotografie są rozpowszechniane online.
Nie jesteśmy w stanie obejrzeć tych wszystkich fotografii we wszystkich miejscach, w których się pojawiły online. Metody czytania zdystansowanego pozwalają jednak zdobyć wiedzę na temat ich wykorzystania i opisać proces interpretacji i gry z historią w internecie.
Pomysł na warsztat
Korzystając z aplikacji Voyant Tools (nie wymaga logowania) możemy poprosić uczestników warsztatu o opisanie charakteru języka propagandy PRL albo tekstów marketingowych. Wprowadzając pojęcia takie jak listy frekwencyjne, kolokacja czy konkordancja dajemy narzędzia do zidentyfikowania schematów językowych czy wartości lub emocji przypisywanych do wybranych słowów.


