
Wprowadzenie
Dzięki YouTube Data Tools udało nam się już pobrać dane na temat filmów, publikowanych na YouTube na kanale Muzeum Historii Polski. Zbadaliśmy też częstotliwość ich publikowania, teraz spróbujmy zinterpretować informacje o samych filmach. Pozyskane przez nas dane zawierają tytuły i opisy, jest więc na czym oprzeć naszą pracę.
Cele lekcji
Celem lekcji jest poznanie podstaw przetwarzania języka naturalnego za pomocą narzędzi udostępnianych przez konsorcjum naukowe CLARIN-PL. Chcemy także przekonać się, jak błędne założenia wobec badania (np. wybór wizualizacji jako efektu analizy) mogą doprowadzić do jego porażki. Będziemy pracować bez programowania.
Efekty
Efektem naszej pracy z obu lekcji będzie opis tematów (wątków), jakie - na podstawie tytułów i opisów filmów - poruszane były przez ostatnie lata na kanale YouTube prowadzonym przez Muzeum Historii Polski. Spróbujemy zrobić to za pomocą chmury słów kluczowych i zobaczymy, że istnieją lepsze rozwiązania.
Wymagania
Pracujemy z gotowym zestawem danych. Konieczna jest przeglądarka internetowa i dostęp do arkusza kalkulacyjnego (np. Google Sheets). Konsorcjum CLARIN-PL udostępnia swoje narzędzia i usługi bezpośrednio w przeglądarce - niezbędne jest jednak założenie darmowego konta. Osoby posiadające konta uczelniane mogą autoryzować się za pomocą narzędzi takich jak CAS. Korzystać będziemy też z narzędzi korpusowych Voyant Tools.
Część merytoryczna
CLARIN-PL jest polskim konsorcjum naukowym. Tworzymy infrastrukturę naukowo-technologiczną udostępniającą zasoby językowe oraz elektroniczne narzędzia do automatycznego przetwarzania języka naturalnego. […] CLARIN-PL wchodzi w skład Europejskiej Infrastruktury Badawczej CLARIN ERIC (Common Language Resources and Technology Infrastructure – European Research Infrastructure Consortium). Powstała ona w 2012 roku. Ma na celu udostępnienie szerokiemu gronu odbiorców (w szczególności naukowcom, wykładowcom i studentom) wyspecjalizowanych zbiorów danych, wiedzy oraz możliwości technicznych potrzebnych do prowadzenia badań na dużych ilościach tekstów. […] Nasze wsparcie dla środowisk naukowych jest całkowicie bezpłatne, a współpraca z biznesem odbywa się na zasadach komercyjnych.
— czytamy na stronie konsorcjum.
W skład polskiego konsorcjum wchodzą Politechnika Wrocławska, Instytut Podstaw Informatyki PAN, Uniwersytet Łódzki, Uniwersytet Wrocławski, Instytut Slawistyki PAN i Polsko-Japońska Akademia Technik Komputerowych. Konsorcjum udostępnia obecnie 37 narzędzi do przetwarzania języka naturalnego, z których skorzystać można bezpośrednio w przeglądarce.
Wszystkie narzędzia CLARIN bazują na rozwiązaniach wypracowanych naukowo i specyficznie dla języka polskiego. Jeśli korzystamy z nich w pracy naukowej, warto je cytować. Propozycję cytowania znajdziemy na stronie każdego narzędzia:

W komunikacji naukowej cytowanie oprogramowania jest równie uzasadnione, co cytowanie innych publikacji (artykułów, monografii). W ten sposób wspieramy naukową widoczność autorów i autorek konkretnych narzędzi oraz dostarczamy informacji na temat zasad działania oprogramowania, co pozwala w pewnym stopniu ograniczyć efekt czarnej skrzynki. Efekt ten występuje, kiedy korzystamy ze skomplikowanych narzędzi w sposób niemal magiczny, bez zrozumienia ich technicznej budowy i metod funkcjonowania. Każde oprogramowanie posiada swoje ograniczenia, a cytowanie artykułów je opisujących zwiększa wiarygodność naszej pracy badawczej.
Przygotowanie danych
Zanim wybierzemy odpowiednie narzędzia CLARIN, musimy przygotować dane źródłowe. Pobieramy plik CSV przygotowany w trakcie poprzedniej lekcji- znajdziemy w nim kolumny videoTitle oraz videoDescription. Zawartość tych kolumn (bez nagłówków!) musimy zapisać w osobnych plikach. To proste - zaznaczamy kolumnę i wklejamy ją do systemowego notatnika. Zapiszmy te oba pliki jako videoTitles.txt oraz videoDescriptions.txt. Oba te pliki są już dostępne w repozytorium na GitHubie w katalogu sources. Poniżej przykład zawartości videoTitles.txt:
Fryderyk Chopin - cudowne dziecko, lew salonowy i geniusz. Zaprasza Łukasz Starowieyski
Kawały polityczne w PRL. Dlaczego władza się ich bała?
Warszawa, czyli stolica z przypadku?
Bunt, który przerodził się w rewoltę. Poznań 1956 roku
Inflanty - zapomniana kraina I Rzeczpospolitej
Dwie twarze Józefa Piłsudskiego
Ku chwale i ku przestrodze. Malarstwo historyczne
Mieszko i jego drużyna. Bitwa pod Cedynią
Bitwa o Monte Cassino. Czy Polacy zadecydowali o zwycięstwie?
Zajął Moskwę, pojmał cara. Hetman Stanisław Żółkiewski. Zaprasza Łukasz StarowieyskiUwaga - w naszym badaniu analizujemy zestaw tytułów i zestaw opisów jako dwa duże, niezależne teksty, powstałe z połączenia danych o wszystkich filmach. Nie oznacza to, że takie podejście jest jedyne: można wyobrazić sobie analizę, w której wyodrębniamy wszystkie tytuły z określonych lat i porównujemy je ze sobą w takim zestawieniu albo badanie, w którym sprawdzamy, jaką długość mają filmy poświęcone określonym tematom. W takich zadaniach posługiwać się już musimy danymi również spoza kolumn videoTitle oraz videoDescription.
Umieszczenie danych w platformie CLARIN-PL
Aby skorzystać z narzędzi językowych CLARIN-PL, musimy się zalogować. Na stronie clarin-pl.eu/catalog/tools wybieramy interesujące nas narzędzie - niech to tym razem będzie LEM (Literacki Eksplorator Maszynowy). To bardzo uniwersalne oprogramowanie, udostępniające wiele opcji - my skorzystamy z niego, aby zamienić wszystkie słowa z naszych tytułów i opisów na formy podstawowe.
Klikamy w zielony przycisk Testuj demo, który przeniesie nas na stronę logowania.
Trzeba wiedzieć, że przeglądarkowe narzędzia CLARIN-PL udostępniane są w wersjach demo o ograniczonej przepustowości - oznacza to, że nie ma sensu opracowywać za ich pomocą zbyt dużych zbiorów tekstów. W takim przypadku należy skontaktować się bezpośrednio z przedstawicielami CLARIN-PL i poprosić o pomoc w przetworzeniu własnego zbioru.
Logowanie do usług CLARIN-PL odbywa się przez system E-science. Oznacza to, że można zalogować się w nim kontem uczelniamym. Możliwe jest także złożenie konta na prywatny adres email.
Po zalogowaniu się przejdźmy na stronę Magazynu Danych, gdzie umieścimy nasze pliki. Każdy użytkownik otrzymuje na start 2GB przestrzeni dyskowej na swoje pliki oraz na pliki wynikowe. Na platformie możemy umieszczać korpusy (zbiory plików w postaci spakowanych archiwów, np. zip) lub pojedyncze pliki.
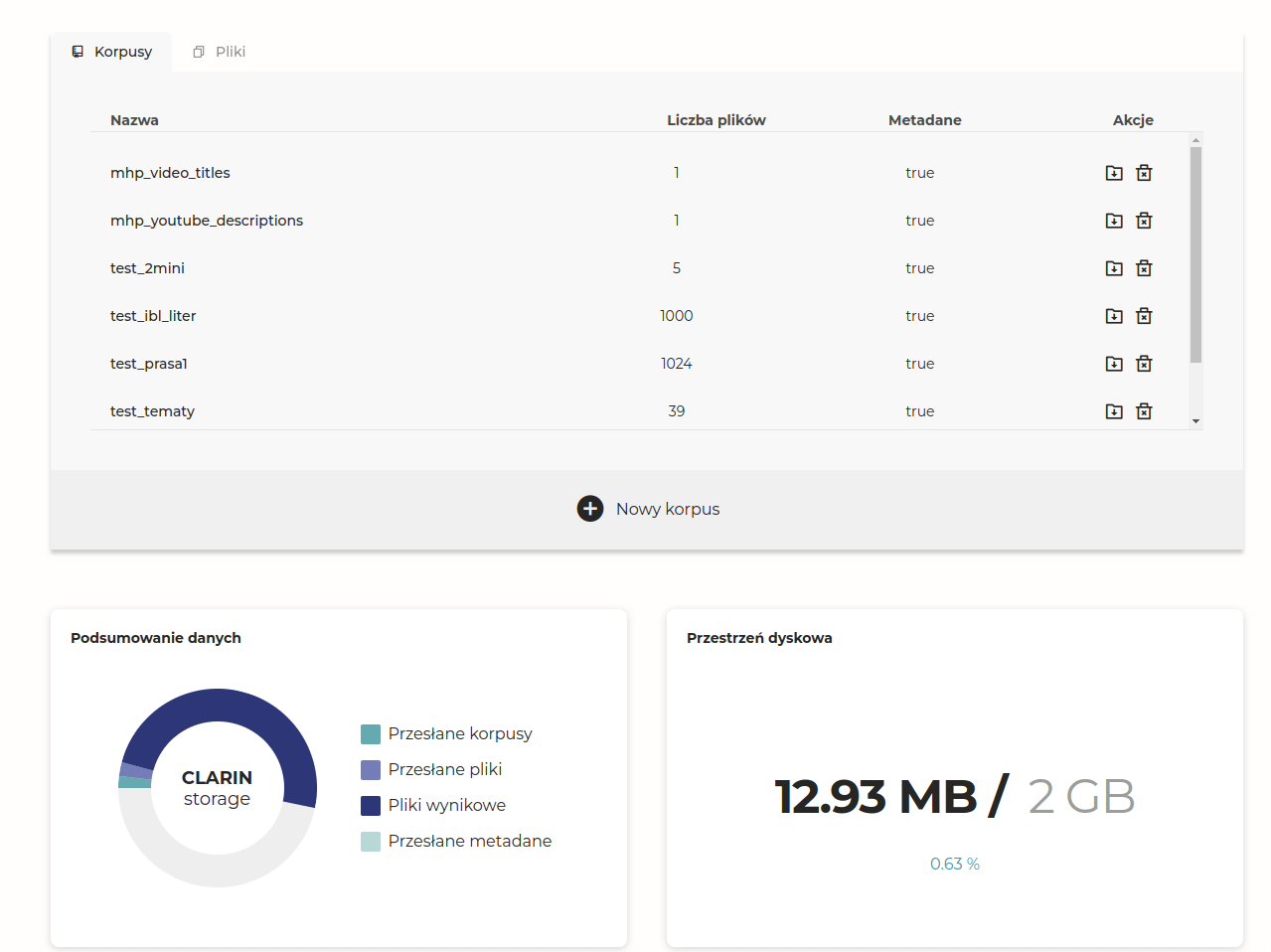
Przesyłamy na platformę pliki videoTitles.txt oraz videoDescriptions.txt (spakowane bądź nie) i możemy zacząć pracować z Literackim Eksploratorem Maszynowym oraz innymi narzędziami Clarin-PL.
Automatyczna lematyzacja i generowanie statystyk
Aby efektywnie analizować teksty z wykorzystaniem statystyki słów, musimy ujednolicić ich wszystkie formy. Lematyzacja to proces sprowadzenia różnych form gramatycznych słów do ich podstawowych form.
Przykładowo, formy podstawowe wygenerowane przez LEMa na podstawie wymienionych wyżej tytułów filmów to:
Fryderyk Chopin - cudowny dziecko , lew salonowy i geniusz .
zapraszać Łukasz Starowieyski Kawała polityczny w PRL .
dlaczego władza się on bać ?
Warszawa , czyli stolica z przypadek ?LEM nie utrzymał porządku linijek oraz błędnie zidentyfikował formę podstawową słowa kawały, jednak efekt jest mniej więcej zgodny z naszymi oczekiwaniami. Będziemy przetwarzać dużą liczbę słów, więc możemy pozwolić sobie na drobne nieścisłości – to zresztą nie jest badanie naukowe, tylko prosty tutorial.
Dzięki lematyzacji będziemy w stanie poprawnie policzyć wszystkie słowa - taka transformacja jest konieczna podczas przygotowywania chmur słów kluczowych, o czym dowiedzieliśmy się już w lekcji poświęconej opisom obrazów ze zbiorów Muzeum Narodowego w Warszawie.
Niektóre narzędzia CLARIN-PL oferują dwa tryby dostępu:
- interaktywny: pozwala szybko edytować i uruchamiać proste zadania tekstowe. Treści do przetworzenia i analizy podajemy bezpośrednio w formularzu na stronie narzędzia;
- tryb kreatora: pozwala na uruchamianie zadań z pełną parametryzacją na większych plikach lub całych korpusach.
LEM dostępny jest wyłącznie w tym drugim trybie. Kiedy mamy już nasze pliki na platformie CLARIN-PL, zaznaczamy je w oknie wyboru. Z listy dostępnych usług narzędzia LEM wybieramy opcję Lematyzator. Alternatywnie wybrać można opcję Statystyki słów i części mowy. O ile Lematyzator wyłącznie przetworzy nam teksty na formy podstawowe, to użycie Statystyk słów i części mowy wygeneruje m.in. zestawienie lematów z informacją o ich liczebności w naszym tekście.

Po poprawnie zakończonym zadaniu możemy pobrać paczkę zip z przetworzonymi tekstami. Zlematyzowane wersje obu plików videoTitles.txt oraz videoDescriptions.txt dostępne są na GitHubie w katalogu lemmas.
Warto zwrócić uwagę, że każdemu zadaniu na platformie CLARIN-PL możemy nadać własną nazwę, co może utrzymać porządek podczas pracy z wieloma narzędziami i wieloma zbiorami danych.
Korpus w Voyant Tools
Skorzystajmy teraz z Voyant Tools, narzędzia, o którym często wspomina się na warsztatach z podstaw humanistyki cyfrowej. To aplikacja webowa rozwijana od 2016 roku przez międzynarodowy zespół badaczy i badaczek.
Zlematyzowaną treść zawierającą tytuły (lub opisy) filmów z profilu MHP umieszczamy w Voyant Tools za pomocą przycisku Upload. Udostępniony przeze mnie korpus można przeglądać pod tym linkiem.
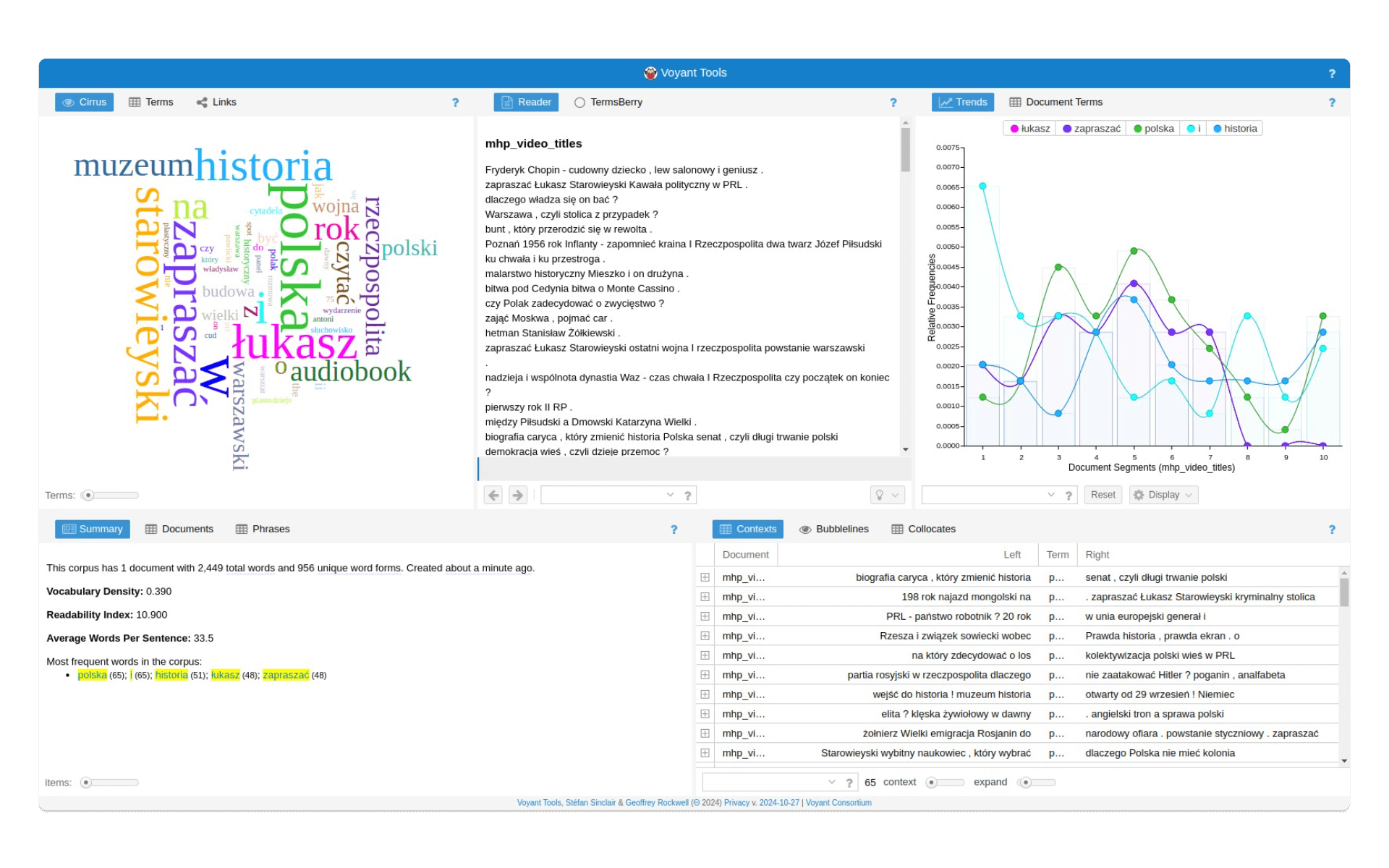
Voyant Tools to wartościowa aplikacja: przetwarzając statystycznie tekst jest w stanie wygenerować nam dane na temat najczęściej pojawiających się słów, listę konkordancji dla wybranego słowa, zestawienie bigramów (najczęstszych zbitek słownych w tekście) czy wykres opisujący obecność wybranych słow / bigramów w poszczególnych tekstach. Z tego ostatniego narzędzia nie skorzystamy, ponieważ wszystkie tytuły umieściliśmy w jednym pliku tekstowym. Wadą Voyant Tools - jeśli korzystamy z niego do analizy tekstów w języku polskim - jest brak możliwości lematyzacji słów.
Usunięcie niepotrzebnych słów (stopwords)
Stopwords (co można przetłumaczyć jako słowa pomijalne) to zbiór słów, które - w kontekście konkretnej analizy tekstu - nie niosą ze sobą żadnej wartości znaczeniowej czy poznawczej. Na jednej z wielu list stopwords dostępnych na GitHubie znajdują się takie słowa jak
a
aby
ach
acz
aczkolwiek
aj
albo
ale
alez
ależ
ani
az
aż
bardziej
bardzo
beda
bedzie
bez
deda
będą
bede
będę
będzieAutorem listy jest Marcin Bielak.
Przyimki, zaimki, partykuły czy liczebniki nie są potrzebne w naszej analizie - nie chcemy jej umieszczać w chmurze słów kluczowych. Ale nie tylko słowa, które nie niosą znaczenia, są dla nas zbędne.
Analizujemy tytuły filmów, które Muzeum Historii Polski umieszcza na YouTube. Interesuje nas przede wszystkim to, o jakich wątkach historycznych jest mowa w tych filmach, dlatego słowa takie jak
historia
muzeum
Polska
Łukasz
Starowieyskiraczej będą przeszkadzać niż pomagać (Łukasz Starowieyski to prowadzący rozmowy w podkastach i na filmach MHP). Trudno jednak na podstawie korpusu prawie 2.5 tys. słów (tyle znajduje się w pliku videoTitles.txt) ręcznie przygotować tego typu zbiór.
Aby poradzić sobie z tym kłopotem moglibyśmy użyć ChatGPT, aby na podstawie zlematyzowanej treści videoTitles.txt wyodrębnił i zapisał do listy wszystkie słowa, które nie są pojęciami historycznymi. Możemy też po prostu ręcznie przejrzeć listę najczęściej występujących słów w korpusie i te, które nie mają charakteru historycznego dodawać do listy stopwords. Ponieważ nasze badanie ma charakter poglądowy i nie chcemy poświęcać na nie zbyt wiele czasu, skoncentrujmy się wyłącznie na usunięciu słów z wcześniej zdefiniowanego zbioru.
Pobieramy na dysk plik polish.stopwords.txt. Otwieramy go i kopiujemy zawartość. W aplikacji Voyant Tools dodajemy stopwords klikając ikonę przełącznika w prawym górnym rogu panelu zawierającego chmurę słów kluczowych:
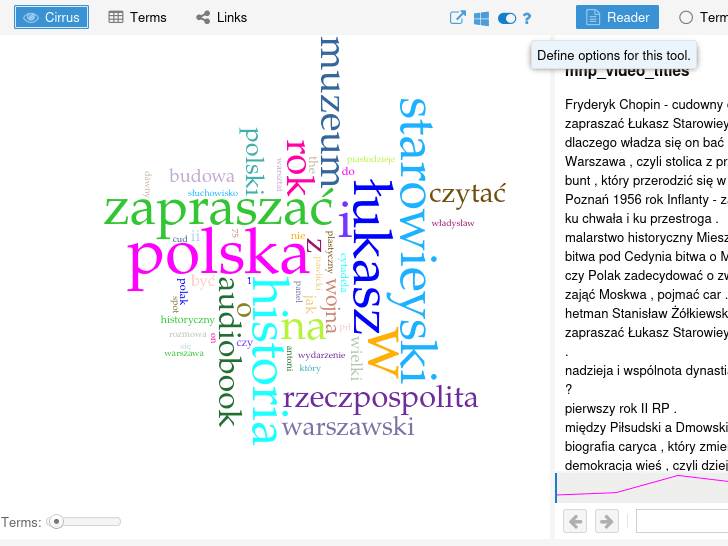
oraz wybierając przycisk Edit List przy opcji Stopwords. Zaznaczenie opcji apply globally spowoduje, że lista stopwords zostanie użyta nie tylko przy generowaniu chmury słów kluczowych ale też w innych panelach Voyant Tools:
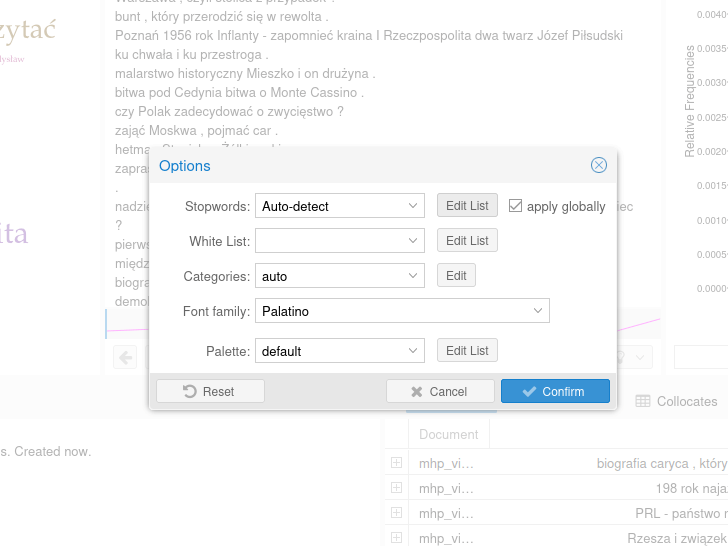
Po kliknięciu w przycisk na ekranie pojawi się niewielkie pole tekstowe, do którego wklejamy treść pliku polish.stopwords.txt. To niewygodny, ale niestety jedyny sposób na dodanie stopwords dla języka polskiego do Voyant Tools.
Kiedy system uwzględni obecność słów, które zdefiniowaliśmy do usunięcia, przetworzy chmurę słów kluczowych:

Chmura słów w takiej postaci nic nam nie mówi - widzimy słowa takie jak powstanie, wojna czy król, ale to zbyt ogólne pojęcia. Zwiększenie liczby słów w chmurze do 150 pozwala zobaczyć coś więcej:

Nadal jesteśmy zbyt daleko do dobrej jakości wizualizacji. Pomieszanie pojęć historycznych z informacjami opisującymi filmy (nazwisko prowadzącego, słowa takie jak zapraszam czy muzeum) powoduje, że chmura słów niczego nam nie mówi. Trudno też w automatyczny sposób oddzielić wartościowe elementy tytułów od tych, które powinny być dla nas przezroczyste. Okazuje się, że pomysł na badanie z wykorzystaniem chmury słów nie był najlepszy. Koncepcja wizualizacji, którą założyliśmy na początku, bez głębszego spojrzenia na dostępne dane, spowodowała, że straciliśmy dużo czasu i energii na bezwartościową analizę 😥.
Spróbujmy inaczej.
Maszynowe wyodrębnienie pojęć
Skorzystajmy z narzędzia TermoPL:
TermoPL wykorzystuje metody statystyczne oraz występujące w tekście zależności gramatyczne, aby zidentyfikować te słowa i zestawienia wielowyrazowe, które prawdopodobnie są terminami specjalistycznymi. Narzędzie przygotowane jest do pracy na długich tekstach w różnych językach.
Planując chmurę słów kluczowych, koncentrowaliśmy się na pojedynczych słowach. Niewiele nam to dało, dlatego spróbujmy zebrać dane na temat zbitek słów, nie tylko podwójnych (bigramów), jakie analizować można w Voyant Tools, ale też większych.
Efektem pracy narzędzia jest tabelaryczne zestawienie potencjalnych terminów. W tabeli zawarte są takie informacje jak liczba wystąpień czy różnorodność kontekstów, co pomaga ocenić ich trafność i istotność. Jeśli dane słowo lub fraza pojawia się w tekście w różnych wariantach (np. odmienione przez przypadki), wszystkie wystąpienia zostaną sprowadzone do jednej formy podstawowej (lemat).
Pracujemy wciąż w trybie kreatora:
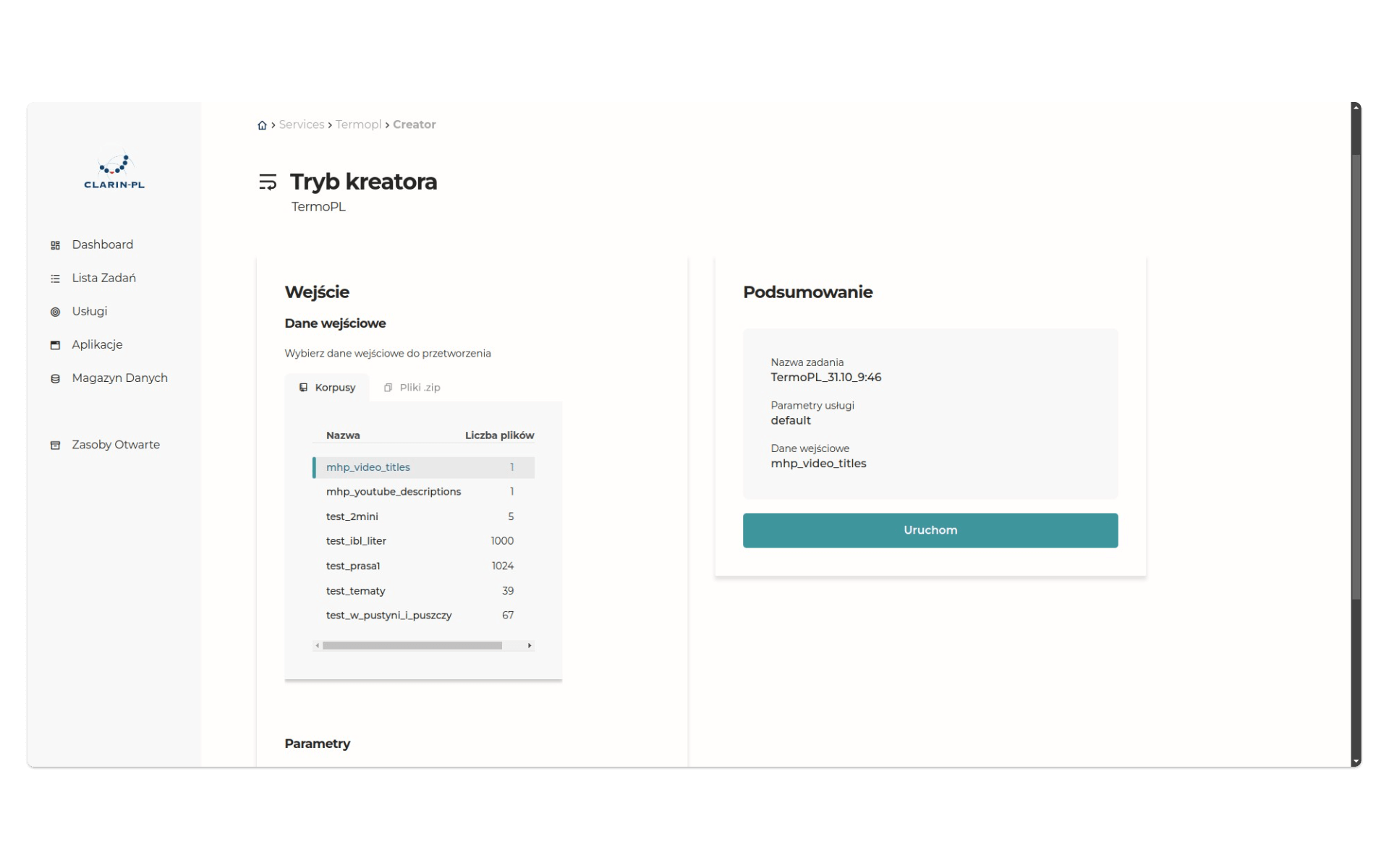
Po wysłaniu danych do narzędzia otrzymamy wyniki analizy - będą dostępne w plikach w katalogu zip (są też dostępne na GitHub). Oto zestaw kilkunastu pojęć, zidentyfikowanych automatycznie przez TermoPL:
muzeum historia
muzeum historia Polska
budowa muzeum historia Polska
cytadela warszawski
warsztat plastyczny
spot promocyjny cykl
audiobook muzeum historia Polska
wydarzenie historyczny
cud Polska
Polska
Łukasz
II wojna światowy
II RP
Starowieyski
historia
II Rzeczpospolita
dawny Polska
historia Polska
I Rzeczpospolita
klasyk polski historiografia
kłamstwo katyński
World war
panel 3
panel 2
muzeum
audiobook
związek sowiecki
zwiastun film
historia mówiony
patriotyzm jutro
getto warszawskiWidzimy wyraźnie, że jakość tych danych jest radykalnie lepsza - kluczowa okazała się zmiana podejścia: przestaliśmy koncentrować się na pojedynczych słowach i zainteresowaliśmy najczęściej występującymi zbitkami.
Próba interpretacji
Rzut oka na zestaw pojęć pozwala wypracować podstawowe wnioski. Po pierwsze, na profilu MHP publikowano nie tylko filmy poświęcone historii, ale także opowiadające o budowie siedziby Muzeum (stąd pojęcia takie jak betonować płyta stropodach czy budowa muzeum historia). Po drugie, wokół dyskusji o politycznym sprofilowaniu MHP można zauważyć, że tak charakterystyczne dla niedawnej polskiej polityki historycznej pojęcie jak żołnierze wyklęci pojawia się w tytułach filmów jedynie raz. Po trzecie, tytuły filmów sugerują takie ujęcie historii Polski, w którym wydarzenia polityczne i militarne nie muszą wcale dominować (dobre przykłady takiego podejścia to takie pojęcia jak historia mówić, odbudowa Warszawa, historia ludowy). Po czwarte, możemy przypuszczać, że nie wszystkie materiały publikowane na YouTube to filmy (dokumentalne lub nagrania rozmów) - w zbiorze pojęcie słuchowisko pojawia się dziesięć razy, audiobook muzeum historia Polska - pięć, a samo słowo audiobook - aż dwadzieścia cztery razy.
Dzięki poszczególnym pojęciom możemy identyfikować także epoki historyczne, na temat których przygotowano filmy MHP: to panorama historii Polski, ponieważ zidentyfikowane pojęcia dotyczą czasów od średniowiecza do współczesności (gdzie pojawiają się wątki pamięci i polityki historycznej, także wokół tematu agresji Rosji na Ukrainę).
Pamiętajmy, że takie maszynowe, statystyczne podejście nie da nam gotowych odpowiedzi i zamkniętej listy tematów i wątków, raczej pozwoli na zdefiniowanie ich na podstawie samodzielnej analizy.
Nasz zbiór był niewielki - prawdziwy potencjał metod tego typu widać najlepiej przy dużych zbiorach tekstów, których nie da się już samodzielnie przejrzeć.
Podsumowanie
Podstawowym błędem w naszej koncepcji badania była koncentracja na wizualizacji: chmura słów kluczowych okazała się zupełnie nieefektywną metodą opisu treści filmów na profilu MHP, także dlatego, że akcentowała pojedyncze słowa, a nie pojęcia. Dopiero użycie TermoPL pozwoliło nam na przygotowanie podstawowej interpretacji.
Nie zawsze dostępność narzędzi i łatwość korzystania z nich przekłada się na efekt analityczny - kluczowe jest dostosowanie narzędzia do danych. Chmura słów nie jest też specjalnie efektywną formą wizualizacji - warto zainteresować się alternatywami. Jedną z nich udostępnia nawet Voyant Tools - to wizualizacja sieci połączeń między słowami.
W trakcie analizy okazało się też, że przygotowana przez LEM lematyzacja tekstu nie jest pozbawiona błędów. Przykładowo, frazę powstanie w gettcie zamieniono na powstać w gettcie, co zupełnie zniekształca oryginalne znaczenie. W przypadku frazy powstanie warszawskie LEM zachował oryginalną treść.
Wykorzystanie metod
Na platformie CLARIN-PL opisy poszczególnych usług uzupełnione są o przykłady użycia. Np., korzystając z TermoPL
Ekonomista pracuje nad słownikiem specjalistycznym. Jako punkt wyjścia przyjął duży korpus publikacji z zakresu ekonomii i nauk pokrewnych, z którego zamierza pozyskać listę haseł do opracowania. Dzięki użyciu TermoPL dysponuje zestawieniem wszystkich istotnych terminów i nie musi przeglądać tekstów ręcznie.
W Google Scholar również znajdziemy ciekawe przykłady wykorzystania narzędzi CLARIN. W 2022 roku Agnieszka Jedziniak opublikowała artykuł Dziewiętnastowieczne impresje z podróży do Włoch w perspektywie analizy kwantytatywnej leksyki wobec językowego obrazu świata (na przykładzie Listów z podróży po Włoszech Konstantego Gaszyńskiego), w którym przedstawiła, przygotowaną z użyciem LEMa, listę frekwencyjną trzystu wyrazów, wyodrębnioną z treści Listów z podróży po Włoszech Konstantego Gaszyńskiego (1853). Na bazie tej listy autorka przygotowała zestaw kategorii wyrazów, różniących się znaczeniowo (np. nazwy czynności określających akcję, nazwy własne czy nazwy i określenia czasu).
Możemy wyobrazić sobie badanie, w którym podobnej analizie poddane są raporty wybranych instytucji kultury - możemy sprawdzić, przez jakie czynności opisują swoje działania i jak pozycjonują się wobec czasu (np. czy muzea historyczne są rzeczywiście historyczne, czy raczej odpowiadają na potrzeby współczesności).
Pomysł na warsztat
Przeglądarkowe narzędzia CLARIN-PL to narzędzia no-code, więc można je wykorzystać w warsztatach z podstaw przetwarzania języka naturalnego, akcentując znaczenie lematyzacji i ograniczenia w jej przeprowadzaniu dla tekstów w języku polskim. Ponieważ chmura słów kluczowych jest często stosowaną wizualizacją w opracowaniach naukowych i raportach, można zorganizować warsztat, który ukaże trudności związane z jej generowaniem oraz wady tej metody jako formy prezentacji wiedzy.
Pamiętajmy, że narzędzia przeglądarkowe CLARIN-PL udostępniane są w wersjach demo, dlatego unikajmy wysyłania do nich zbyt dużych zbiorów tekstów.


