Wprowadzenie
Instytucje kultury i organizacje pozarządowe zobowiązane są do tworzenia raportów ze swojej działalności. Poza rozpoznaniem wymogów raportowania, przygotowaniem merytorycznym (dane, informacje) i pracą redakcyjną, trzeba w jakiś sposób udostępnić treść sprawozdania. Raport opublikować można w postaci elegancko złożonej broszury albo zwykłego pliku PDF.
Być może - dla niektórych instytucji - rozwiązaniem usprawniającym coroczne przygotowywanie raportu byłoby pewne zautomatyzowanie procesu jego składu i publikowania. Zamiast płacić za tradycyjny skład albo udostępniać PDF wygenerowany z pliku Worda, można skorzystać z R i pakietu bookdown.
Zresztą taka automatyzacja przydać się może też w przypadkach takich jak skład publikacji pokonferencyjnych, materiałów warsztatowych, podręczników i skryptów akademickich. Jeżeli nasza instytucja w ramach swojej działalności tworzy i udostępnia tego typu publikacje, bookdown może być ciekawą opcją.
Cele lekcji
Celem lekcji jest wdrożenie do korzystania z pakietu bookdown. Lekcja składa się z dwóch części:
- w pierwszej poznamy podstawy składu publikacji z wykorzystaniem tego pakietu,
- w drugiej lekcji umieszczać będziemy w naszej publikacji zaawansowane rodzaje treści (interaktywne wykresy i tabele) oraz pracować będziemy nad formą (fonty, kolory).
Efekty
Bezpośrednim efektem naszej pracy będzie raport dostępny w postaci pliku PDF, EBPUB oraz strony WWW z opcją przeszukiwania treści. W raporcie znajdą się rozdziały, przypisy, grafiki, tabele i wykresy. Obie lekcje będą dobrym wstępem do dalszej samodzielnej pracy nad składem publikacji w R.
Przykładową publikację wygenerowaną z wykorzystaniem bookdown podejrzeć można na tej stronie. Publikacja webowa złożona przez bookdown
- posiada automatycznie generowany spis treści,
- możliwość dynamicznego przeszukiwania treści,
- wsparcie dla publikowania wykresów i tabel,
- możliwość samodzielnego ustawienia fontu i koloru tła oraz włączenia trybu ciemnego (dark mode).
Wymagania
Aby sprawnie pracować w bookdown konieczne jest
- poznanie podstaw składni języka R i poruszania się w aplikacji Posit.cloud,
- znajomość podstaw markdown (można je poznać w lekcji poświęconej Twine).
Posit.cloud to dostępne przez przeglądarke środowisko programistyczne dla R - korzystając z niego, możemy programować bez konieczności instalowania jakichkolwiek narzędzi na własnym komputerze. Markdown to prosty język znaczników, stworzony w celu łatwego formatowania tekstu i konwersji go na HTML.
Ponieważ celem lekcji nie jest merytoryczne opracowanie raportu tylko jego skład, skorzystałem z ChatGPT i wygenerowałem kilka krótkich rozdziałów raportu. Teksty te dostępne są na GitHubie i można je wykorzystać do zrealizowania lekcji.
Część merytoryczna
Na potrzeby lekcji wymyślmy sobie projekt Cyfrowego Muzeum Pocztówek, prowadzonego przez fikcyjną fundację Bardzo Lokalne Historie. Fundacja uzyskała grant na przygotowanie i udostępnianie cyfrowej kolekcji pocztówek z przełomu XIX i XX wieku i musi opublikować raport z ostatnich dwóch lat, pokazujący przyrost zasobów muzeum oraz działania wokół zgromadzonej kolekcji.
ChatGPT pozwoli nam szybko przygotować rozdziały do raportu - pamiętajmy, interesuje nas praca nad formą publikacji a nie jej merytoryczna zawartość.
Kodowanie do markdown
Na GitHubie dostępne są wygenerowane maszynowo teksty raportu. W katalogu /txt znajdują się pliki .txt:
- /txt/index.txt
- /txt/o_fundacji.txt
- /txt/o_muzeum.txt
- /txt/statystyki_zbiorow.txt
- /txt/sprawy_techniczne.txt
- /txt/badanie.txt
- /txt/opinie.txt
- /txt/plany.txt
Każdy plik to treść osobnego rozdziału. Aby użyć te treści w naszej publikacji, musimy zakodować je na format markdown. Markdown pozwala w łatwy sposób opisywać tekst znacznikami, tak aby ostatecznie wygenerować na jego podstawie HTML. Nagłówki, pogrubienia i kursywy, ale też umieszczanie grafiki czy tabel byłoby niemożliwe bez odpowiedniego kodowania.
Bardzo ważny jest plik index.txt - to będzie pierwszy plik, którego treść wyświetli się po wejściu na stronę raportu. To też kluczowy plik w procesie generowania PDF czy EPUB - umieszczamy tam metadane i definiujemy opcje składu.
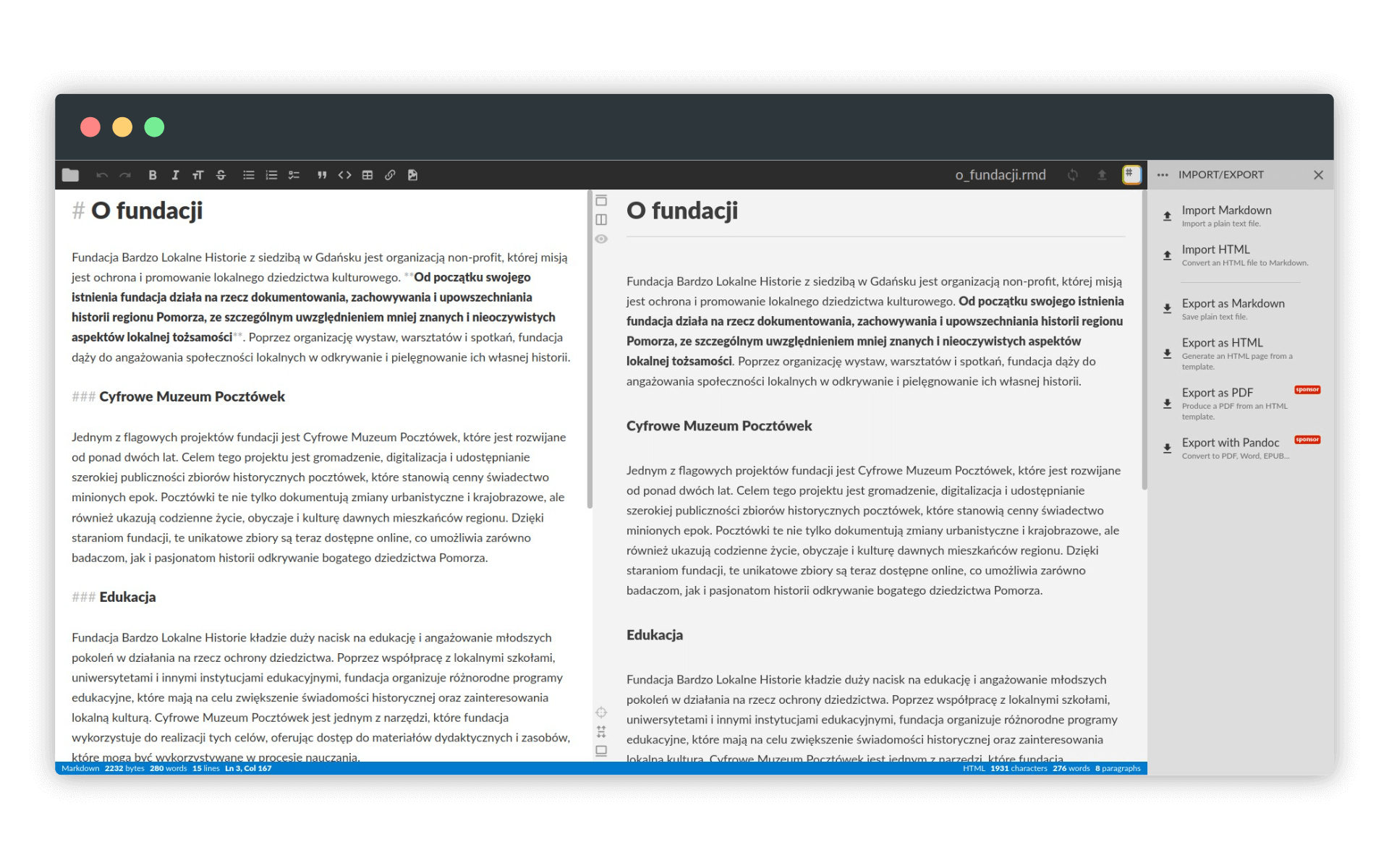
Dostępnych jest wiele narzędzi online, ułatwiających pracę z markdown. Jednym z nich jest StackEdit. Praca w nim jest bardzo intuicyjna. Okno aplikacji dzieli się na dwie części: po prawej kodujemy tekst w markdown, po prawej mamy jego aktualizowany na bieżąco podgląd:

Po skończonej edycji wybieramy z menu po lewej stronie (uruchamianego kliknięciem w ikonę z logo aplikacji) opcję Import/export i Export as Markdown:
Szybką pomoc w tagowaniu w markdown można znaleźć na GitHub, można też skorzystać z pomocy ChatGPT, szczególnie przy trudniejszych elementach kodu (np. tabelach).
Gotowe pliki markdown z podstawowym tagowaniem udostępnione są na GitHub w katalogu /rmd - można je użyć do generowania raportu.
Pzygotowujemy środowisko i treści
Gotowe pliki .Rmd musimy umieścić w środowisku Posit.cloud. Jak widać, cała praca redakcyjna odbywa się poza tą przestrzenią - możemy swobodnie pracować nad treściami raportu i dopiero po skończonej redakcji wrócić do pracy w środowisku programistycznym R. Aby zaimportować wiele plików do Posit.cloud, musimy je spakować do jednego katalogu - katalog taki zawiera oprócz plików markdown także materiały graficzne, które dodamy już w przestrzeni Posit.cloud. Grafiki znajdują się w katalogu /assets.
Zakładamy nowy projekt w Posit.cloud. W katalogu głównym naszego projektu tworzymy katalog book i tam importujemy plik files.zip. Po przesłaniu pliku, paczka zostanie rozpakowana. Tworzymy też plik bookdown.R, w którym będziemy umieszczać kod generujący nasz raport:
Musimy teraz zainstalować bibliotekę bookdown i wczytać ją do środowiska:
install.packages("bookdown")
library(bookdown)Możemy zacząć pracę nad składem 😄.
Ustawiamy opcje składu
Standardowo, metody dostępne w pakiecie bookdown wygenerują plik książki bazując na nazwach plików źródłowych (dlatego można je numerować, np. 1_wstep.Rmd, 2_informacje_ogolne.Rmd itd.). Możemy jednak bezpośrednio wskazać zasady generowania książki oraz jej podstawowe metadane. W tym celu musimy stworzyć plik tekstowy _bookdown.yml w formacie YAML i umieścić go w katalogu głównym, z którego generować będziemy naszą publikację.
Pliki YAML (YAML Ain’t Markup Language) to format plików tekstowych używany głównie do przechowywania i przesyłania danych. YAML jest prosty i czytelny dla człowieka, co czyni go dobrym narzędziem do przechowywania konfiguracji aplikacji, opisów struktur danych oraz wymiany informacji między systemami. Pliki YML używają wcięć (tabulatorów) do określania struktury danych, co ułatwia zrozumienie hierarchii informacji bez użycia dodatkowych znaczników, jak w przypadku XML lub JSON.
Pełen opis konfiguracji dostępny jest na stronie pomocy pakietu.
W naszym pliku dodajemy linię:
rmd_files: ["index.Rmd","o_fundacji.Rmd","o_muzeum.Rmd","statystyki_zbiorow.Rmd","sprawy_techniczne.Rmd","badanie.Rmd","opinie.Rmd","plany.Rmd"]Dane (czy metadane) w formacie YAML możemy dodać też do pliku index.Rmd, przy czym - ze względu na właściwości narzędzi i metod, które wykorzystuje pakiet bookdown, określone opcje zadziałają wyłącznie wtedy, kiedy określimy je w odpowiednim pliku.
W pliku index.Rmd podajemy oprócz podstawowych metadanych także klasę dokumentu PDF.
---
title: "Raport z działania Cyfrowego Muzeum Pocztówek"
author: "Jan Nowak-Kowalski"
date: "`r Sys.Date()`"
site: "bookdown::bookdown_site"
documentclass: book
link-citations: yes
---Klasa book wygeneruje broszurę ze stroną tytułową, spisem treści i rozdziałami dodawanymi od nowej strony. Zastosowanie klasy article pozwoli na uzyskanie dokumentu (postaci artykułu naukowego), klasa slides - prezentację. Więcej o klasach przeczytać można w dokumentacji LaTex.
Pamiętajmy o znakach - - - otwierających i zamykających sekcję metadanych!
Poprawne zestawienie plików powinno wyglądać mniej więcej tak:
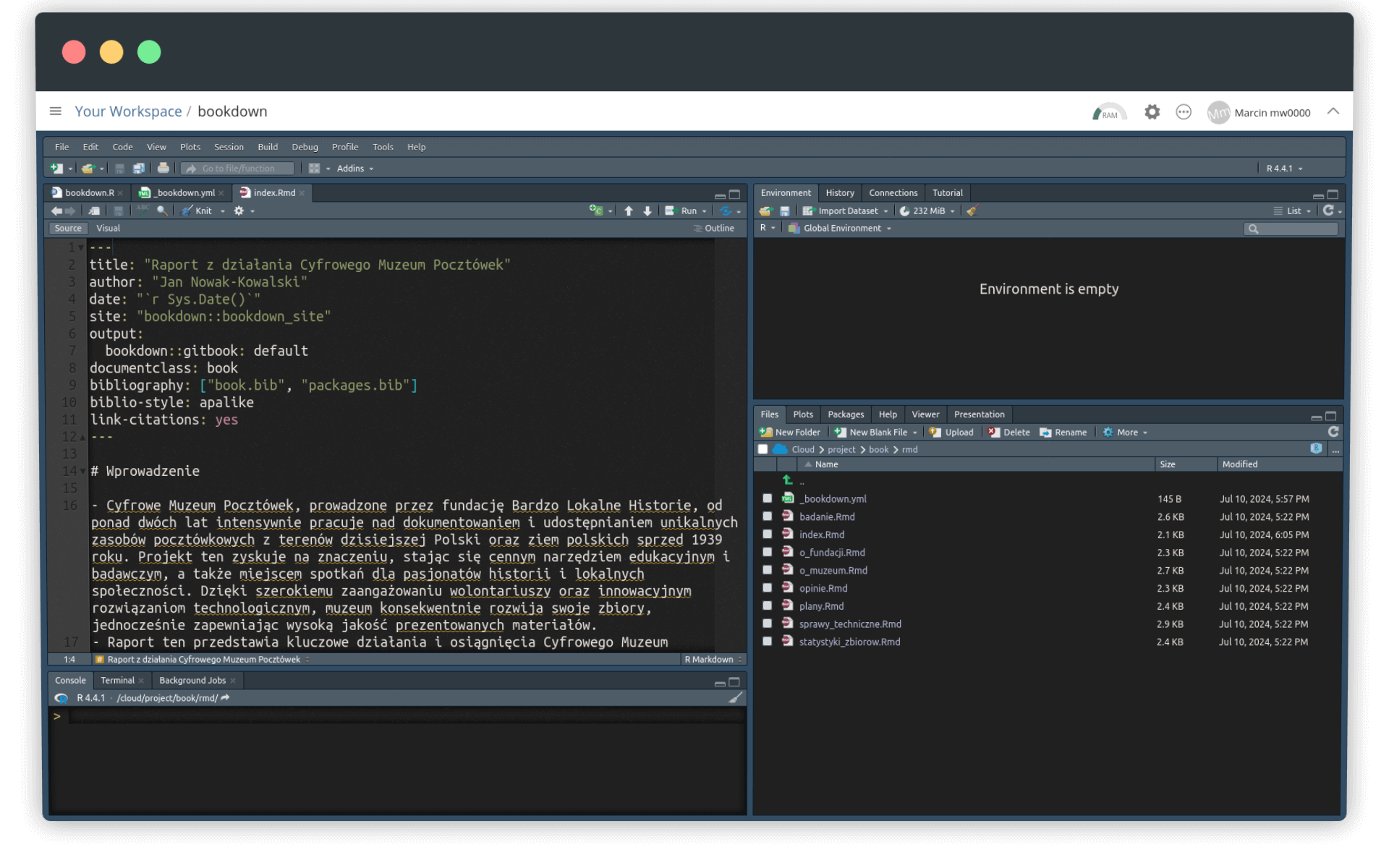
Konieczne jest też odpowiednie ustawienie katalogu roboczego. Kiedy w panelu bocznym wyświetlona jest już zawartość katalogu /rmd, wybieramy opcję More… - Set as Working Directory
Spróbujmy dodać jeszcze ilustrację do strony startowej (index.Rmd). Aby w markdown dodać ilustrację, potrzebujemy tego kodu:
W naszym przykładzie:
Edytor Posit.cloud sprawdzi poprawność ścieżki do pliku graficznego i wygeneruje od razu podgląd:
Oczywiście możemy dodawać grafikę do każdego źródłowego pliku .Rmd.
Generowanie pliku PDF
Nareszcie możemy zacząć generować nasz raport w różnych formatach. Zacznijmy od PDF. Pamiętając o tym, żeby katalog roboczy zawierał wszystkie niezbędne pliki .Rmd, korzystamy z takiej metody:
render_book("index.Rmd", "bookdown::pdf_book", config_file="_bookdown.yml")W efekcie w naszym katalogu powstanie nowy katalog - _book, a w nim plik _main.pdf. Możemy go od razu podejrzeć:
Tłumaczenia elementów treści
Jak widać, problemem są angielskie frazy (chapter zamiast rodział czy Figure zamiast Rycina). Możemy to zmienić, edytując metadane w index.Rmd i dodając linię z kluczem lang:
---
title: "Raport z działania Cyfrowego Muzeum Pocztówek"
author: "Jan Nowak-Kowalski"
date: "`r Sys.Date()`"
site: "bookdown::bookdown_site"
documentclass: book
link-citations: yes
lang: pl
---Wygenerowanie raz jeszcze pliku PDF poleceniem
render_book("index.Rmd", "bookdown::pdf_book", config_file="_bookdown.yml")stworzy plik z polskimi tłumaczeniami:
Funkcja render_book() jako pierwszy argument przyjmuje źródła książki (może być to plik index.Rmd lub katalog z plikami markdown), jako drugi - format, w jakim zostanie wygenerowana publikacja. W naszym przypadku stosujemy metodę pdf_book z pakietu bookdown, stąd zapis bookdown::pdf_book, zgodnie ze schematem:
nazwa_pakietu::nazwa_metodyGenerowanie wersji webowej
Aby wygenerować wersję webową raportu (stronę internetową gotową do umieszczenia na serwerze), musimy zmienić argument w funkcji render_book():
render_book("index.Rmd", "bookdown::gitbook", config_file="_bookdown.yml")
Aby spolszczyć interfejs naszej publikacji w formacie HTML (którą będziemy zaraz generować), należy do pliku _bookdown.yml dodać tłumaczenia:
language:
label:
fig: 'Rycina '
tab: 'Tabela '
eq: 'Równanie '
thm: 'Twierdzenie '
lem: 'Lemat '
cor: 'Wniosek '
prp: 'Propozycja '
cnj: 'Hipoteza '
def: 'Definicja '
exm: 'Przykład '
exr: 'Ćwiczenie '
hyp: 'Hipoteza '
proof: 'Dowód. '
remark: 'Uwaga. '
solution: 'Rozwiązanie. '
ui:
chapter_name: 'Rozdział '
appendix_name: 'Dodatek 'Pamiętajmy o dodaniu spacji po każdym ciągu tekstowym tłumaczenia. Więcej na temat ustawień webowej wersji raportu dowiemy się w kolejnej lekcji.
Po wygenerowaniu plików należy umieścić je na serwerze - konieczne jest też dodanie katalogu assets, zawierającego grafiki.
Generowanie pliku EBUB
Aby wygenerować raport w postaci publikacji na czytniki (EBPU), korzystamy z funkcji bookdown::epub_book:
Za jej pomocą możemy ustawić takie opcje jak okładka, sposób generowania spisu treści czy wygląd (ustawiany za pomocą pliku CSS):
epub_book(fig_width = 5, fig_height = 4, dev = "png",
fig_caption = TRUE, number_sections = TRUE, toc = FALSE,
toc_depth = 3, stylesheet = NULL, cover_image = NULL,
metadata = NULL, chapter_level = 1, epub_version = c("epub3",
"epub", "epub2"), md_extensions = NULL, global_numbering = !number_sections,
pandoc_args = NULL, template = "default")Oczywiście wykorzystujemy tę funkcję jako parametr funkcji render_book():
render_book("index.Rmd", "bookdown::epub_book", config_file="_bookdown.yml")Otrzymujemy plik EPUB:
Podsumowanie
Pakiet bookdown to wygodne narzędzie do generowania plików PDF, EPUB i witryn WWW z treścią artykułów naukowych, raportów czy podręczników. Praca z plikami markdown jest prosta, a metody generowania poszczególnych formatów pozwalają na odpowiednie przygotowanie publikacji (o tym więcej w kolejnej lekcji).
Korzystanie z tego pakietu nie musi jednak ograniczać się do generowania plików ze statycznych treści. Możemy wyobrazić sobie taki system publikowania, w którym - używając R - dynamicznie generujemy treść plików źródłowych i następnie przetwarzamy je automatycznie do publikacji. W takim przypadku aktualizacja raportów czy personalizacja podręczników nie musi być dużym wyzwaniem organizacyjnym. Możemy w ten sposób generować też dyplomy ukończenia kursu czy plany zajęć warsztatowych.
W kolejnej lekcji poznamy zaawansowane metody pracy z bookdown i sposoby na umieszczanie w treści naszych publikacji webowych interaktywnych wykresów i tabel.
Wykorzystanie metod
Na stronie bookdown.org znajdują się przykłady podręczników przygotowanych z wykorzystaniem tego pakietu. Powszechnie wykorzystuje się go także do publikowania tekstów naukowych oraz raportów.
Pomysł na warsztat
Praca z bookdown może być elementem warsztatu z R. W trakcie warsztatu można zwrócić uwagę na możliwości, jakie daje automatyzacja procesu pisania i publikowania treści (raportowanie, personalizacja podręczników itp.).


