
Wprowadzenie
W poprzedniej lekcji nauczyliśmy się generować publikacje cyfrowe z wykorzystaniem pakietu bookdown. Podstawą naszej pracy był raport fikcyjnej organizacji pozarządowej na temat muzeum cyfrowego, który przygotowaliśmy w postaci pliku PDF, EPUB i przeszukiwalnej strony internetowej.
Metoda pracy z bookdown jest prosta: przygotowujemy pliki markdown i ustawiamy odpowiednie parametry funkcji render_book. Definiujemy także metadane i ustawienia w pierwszym pliku naszej publikacji (index.Rmd) oraz pliku konfiguracyjnym _bookdown.yml. O tym wszystkim dowiedzieliśmy się w poprzedniej lekcji.
Teraz naszym celem będzie poznanie dodatkowych opcji generowania publikacji oraz sposobów umieszczania w jej internetowej wersji interaktywnych wykresów i tabel.
Przypomnijmy tylko, że pakiet bookdown wykorzystywany jest powszechnie w publikowaniu materiałów naukowych oraz skryptów i opracowań akademickich. Można wykorzystać go także do skonstruowania procesu automatycznego raportowania - program w R pobierać może i przetwarzać określone dane i następnie publikować je automatycznie w postaci plików PDF czy strony internetowej.
Cele lekcji
Celem lekcji jest nauka pracy z pakietem bookdown. Poznamy sposoby umieszczania w publikacji interaktywnych wykresów i tabeli oraz pracować będziemy nad jej formą (fonty, kolory itp.).
Efekty
Efektem naszej pracy będzie m.in. raport w postaci strony WWW uzupełnionej o interaktywne wykresy i tabele. Pamiętajmy, że raport jest fikcyjny (został wygenerowany przez ChatGPT) - interesuje nas jedynie praca nad formą publikacji oraz umieszczenie w niej określonych treści.
Wymagania
Aby skorzystać z tej lekcji, konieczne jest zapoznanie się z poprzednią, będącą wprowadzeniem do pracy w bookdown. Konieczna jest także wiedza na temat podstaw składni języka R i poruszania się w aplikacji Posit.cloud.
Pracujemy w Posit.cloud - należy założyć tam darmowe konto.
Część merytoryczna
Naszą lekcję zaczniemy od przeglądu dodatkowych opcji generowania publikacji. Następnie zajmiemy się dodawaniem interaktywnych elementów do wersji WWW naszego raportu. bookdown - korzystając z innych bibliotek R - pozwala na umieszczanie w publikacjach gotowych skryptów R, które są wykonywane podczas renderowania publikacji.
Zaawansowane ustawienia gitbook
Naszą publikację w postaci strony WWW generowaliśmy za pomocą kodu
render_book("index.Rmd", "bookdown::gitbook", config_file="_bookdown.yml")Aby bardziej spersonalizować wygląd tej strony, stwórzmy plik _output.yml i dodajmy do niego kilka ustawień:
bookdown::gitbook:
config:
toc:
collapse: subsection
scroll_highlight: true
before: null
after: null
toolbar:
position: fixed
edit : null
download: ["raport.pdf", "raport.epub"]
search:
engine: lunr # or fuse
# options to control/tune search engine behavior (for
# fuse.js, refer to https://fusejs.io/api/options.html)
options: null
fontsettings:
theme: night
family: serif
size: 2
sharing:
facebook: true
github: false
twitter: true
linkedin: false
weibo: false
instapaper: false
vk: false
whatsapp: false
all: ['facebook', 'twitter', 'linkedin', 'weibo', 'instapaper']
info: falseOpis wszystkich ustawień dostępny jest w dokumentacji pakietu. Zwróćmy uwagę na chociaż kilka z nich:
- sekcja toc (table of contents) zawiera ustawienia spisu treści, wyświetlanego po lewej stronie ekranu. Ustawienie collapse: subsection spowoduje, że nasz spis treści rozwijał się będzie, jeśli w głównych rozdziałach znajdują się podrozdziały (sekcje). Za pomocą opcji before i after możemy dodawać tekst na górę i dół spisu treści - do dobry sposób na umieszczenie w spisie treści tytułu i autora oraz stopki redakcyjnej.
- ustawienia download: [“raport.pdf”, “raport.epub”] dodają do nagłówka strony element pozwalający na pobranie plików PDF i EPUB z naszą publikacją (uwaga, pliki te nie będą generowane na bieżąco i muszą być dostępne na serwerze),
- sekcja search pozwala zmienić sposób wyszukiwania na stronie naszej publikacji,
- w sekcji fontsettings ustawiamy standardowy schemat kolorystyczny publikacji WWW, krój fontów i ich rozmiar. Warto pamiętać o tym, że użytkownik naszej strony może samodzielnie zmieniać te ustwawienia.
- sekcja sharing pozwala wskazać, ikony jakich mediów społecznościowych pojawią się w nagłówku naszej strony i pozwolą na łatwe udostępnianie tam jej treści.
Wadą pakietu bookdown jest to, że ustawienia zasad generowania i wyglądu publikacji definiuje się w wielu różnych miejscach. To efekt tego, że ten pakiet łączy w sobie metody z wielu innych pakietów. Na tej stronie możemy zobaczyć przystępne podsumowanie tego, w jakich miejscach edytujemy określone opcje tworzenia publikacji gitbook:

Uwaga: wpisy z _output.yml równie dobrze umieścić można w pliku index.Rmd w kluczu output.
Szablon bs4_book
bookdown pozwala na generowanie responsywnej publikacji WWW w formacie bs4_book, który wykorzystuje popularną bibliotekę CSS Bootstrap. Układ strony jest w tym przypadku trójkolumnowy - dodatkowa kolumna po prawej to generowany dynamicznie spis treści wyświetlanego aktualnie rozdziału:

Ustawienia formatu bs4_book opisane są w dokumentacji:
bookdown::bs4_book:
theme:
primary: "#0d6efd"
base_font:
google: Sen
heading_font:
google:
family: Bitter
wght: 200
code_font:
google:
# arguments to sass::font_google()
family: DM Mono
local: falseZwróćmy uwagę na opcję ustawień fontów (możemy korzystać z zasobów Google Fonts) oraz możliwośc ustawienia dominującego koloru szablonu - w naszym przypadku to #0D6EFD:
Ustawienia definiujemy w pliku _output.yml, a publikację generujemy za pomocą
render_book("index.Rmd", "bookdown::bs4_book", config_file="_bookdown.yml")Szablon Tufte
W bookdown skorzystać możemy też ze stylu Tufte, który pozwala na generowanie prezentacji WWW lub eleganckich jednostronicowych raportów. Konieczne jest zainstalowanie pakietu tufte:
install.packages("tufte")
render_book("index.Rmd", "bookdown::tufte_html_book", config_file="_bookdown.yml")
Ustawienia szablonu definiujemy - podobnie jak w poprzednich przypadkach - w pliku _output.yml. Na przykład, nasz wielostronicowy (wieloplikowy) raport możemy opublikować jako jeden duży dokument HTML. W tym celu pozbawimy go spisu treści (który zajmuje zbyt wiele miejsca na górze strony) i ustawimy na false sposób wydzielania podstron:
bookdown::tufte_html_book:
split_by: none
toc: falsePamiętajmy, aby zachować poprawną składnię YAML. Ponieważ nasza publikacja to HTML i CSS, możemy dowolnie edytować strukturę i estetykę publikacji tak, aby lepiej odpowiadała naszym wymaganiom. Zmianę koloru tła czy fontów wprowadzić można edytując plik CSS.

Warto wiedzieć, że styl Tufte nawiązuje do Edwarda Tufte, amerykańskiego statystyka i jednego z pionierów wizualizacji danych, krytyka prezentacji Power Point jako metody wykładu generującej błędy poznawcze i zaburzającej poprawność wnioskowania na podstawie posiadanych danych statystycznych.
Odpowiednie przygotowanie szablonu może być wymagające, ale jeśli już uda nam się go odpowiednio złożyć, możemy wykorzystywać go do automatycznego generowania wielu publikacji. Być może to interesująca opcja dla instytucji czy organizacji pozarządowych, które publikują swoje treści w seriach, a z jakiegoś powodu nie decydują się na klasyczny skład publikacji.
Interaktywne tabele w publikacjach bookdown
Przejdźmy teraz do drugiego tematu, jaki mieliśmy poruszyć w tej lekcji. Interaktywne wykresy i tabele w publikacjach generowanych przez bookdown umożliwiają dynamiczne eksplorowanie danych. Zamiast statycznych obrazów (plików graficznych z wykresami), interaktywne wykresy umożliwiają zoomowanie, przesuwanie, filtrowanie oraz wyświetlanie dodatkowych informacji przy najechaniu kursorem na konkretne elementy wykresu. Użytkownicy mogą samodzielnie eksplorować dane, identyfikować wzorce i szczegóły, które mogą być niewidoczne na statycznych wykresach. Nasza publikacja nadaje się wtedy nie tylko do lekktury, ale też do - z konieczności ograniczonej - pracy z danymi.
Na GitHub znajdują się fikcyjne dane dotyczące przyrostu zbiorów w naszym muzeum - na ich podstawie przygotujemy tabelę i wykres w pliku statystyki_zbiorow.Rmd. Oto kod w R, którym przygotujemy środowisko do generowania interaktywnego widgetu tabeli i dane, które do niej trafią:
# instalacja niezbednych pakietow
install.packages("DT")
# CSV do data.frame
# file.choose() umożliwi nam ręczne wskazanie pliku csv - dzięki temu nie musimy wpisywać pełnej ścieżki
dane <- read.csv(file.choose())
# zobaczmy nasze dane
View(dane)
# wczytujemy pakiety do środowiska
library(DT)
library(webshot)Teraz musimy edytować plik statystyki_zbiorow.Rmd - to w tym rozdziale pojawi się tabela.
# Statystyki zbiorów
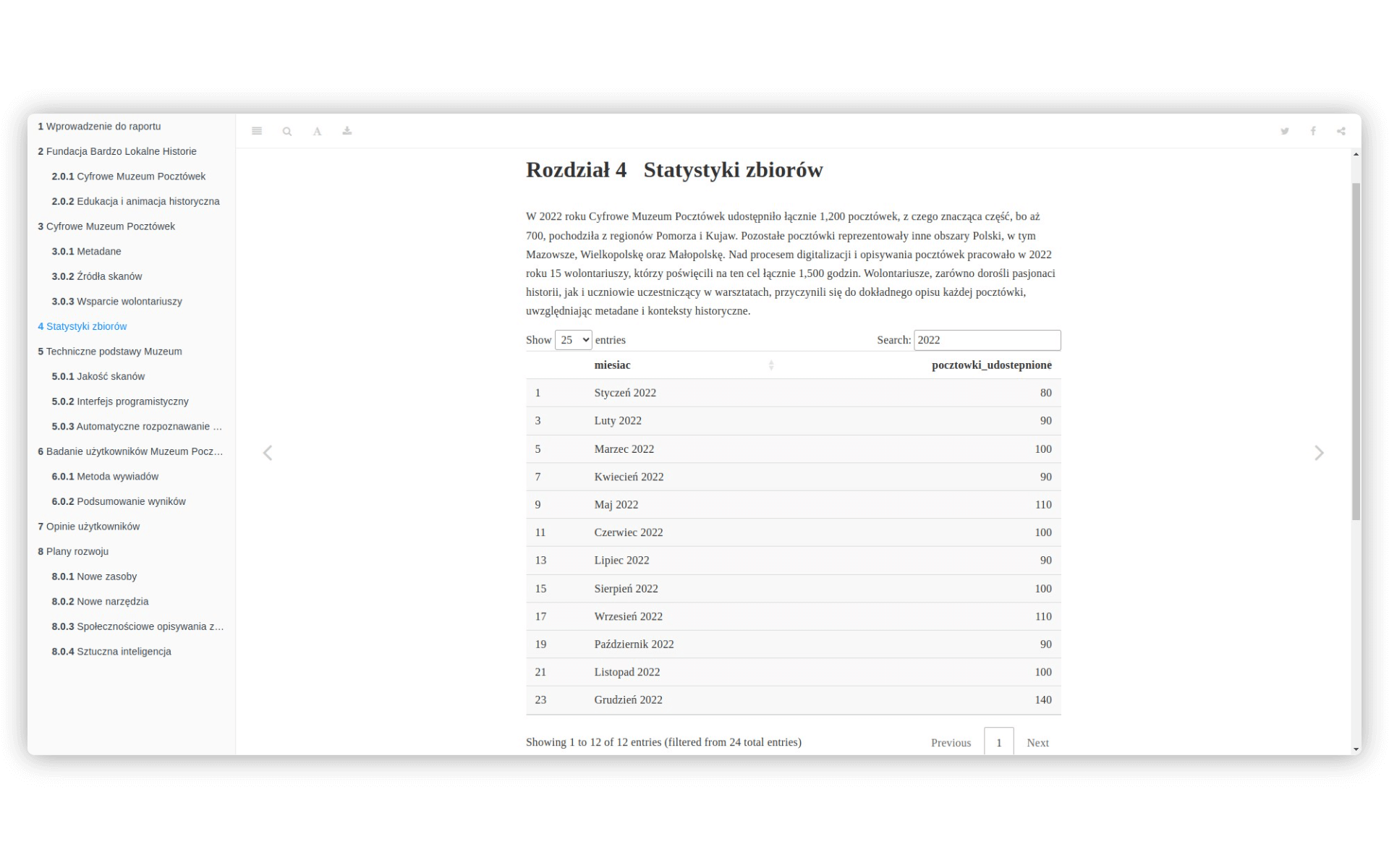
W 2022 roku Cyfrowe Muzeum Pocztówek udostępniło łącznie 1,200 pocztówek, z czego znacząca część, bo aż 700, pochodziła z regionów Pomorza i Kujaw. Pozostałe pocztówki reprezentowały inne obszary Polski, w tym Mazowsze, Wielkopolskę oraz Małopolskę. Nad procesem digitalizacji i opisywania pocztówek pracowało w 2022 roku 15 wolontariuszy, którzy poświęcili na ten cel łącznie 1,500 godzin. Wolontariusze, zarówno dorośli pasjonaci historii, jak i uczniowie uczestniczący w warsztatach, przyczynili się do dokładnego opisu każdej pocztówki, uwzględniając metadane i konteksty historyczne.
```{r, echo = FALSE}
library(DT)
DT::datatable(dane)
```
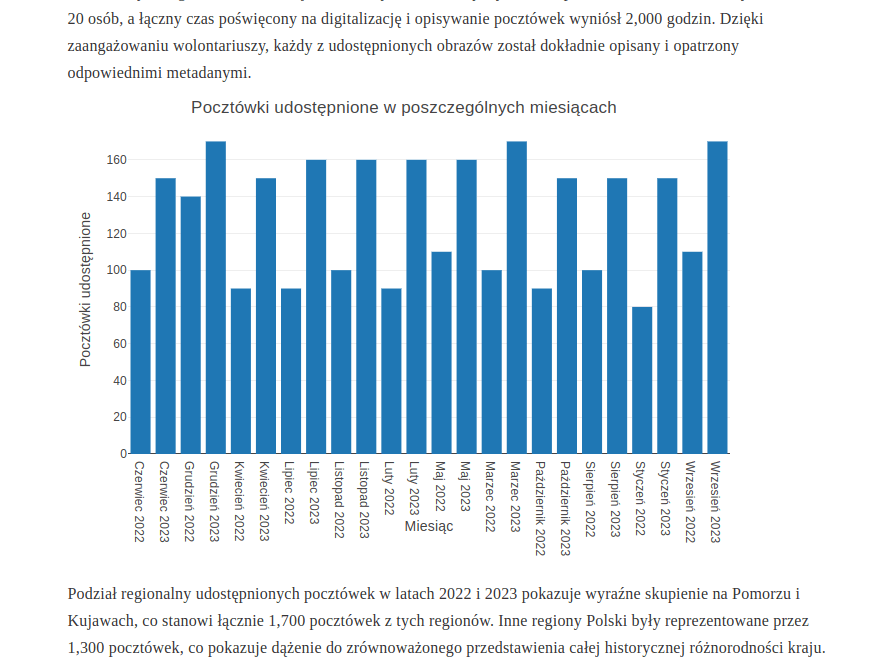
W 2023 roku Cyfrowe Muzeum Pocztówek zwiększyło swoje tempo pracy, udostępniając 1,800 pocztówek. Najwięcej z nich, bo aż 1,000, nadal pochodziło z Pomorza i Kujaw, co odzwierciedla główny obszar zainteresowania fundacji Bardzo Lokalne Historie. Z kolei 500 pocztówek pochodziło z Dolnego Śląska, a pozostałe 300 z różnych regionów wschodniej Polski, w tym Lubelszczyzny i Podkarpacia. Liczba wolontariuszy wzrosła do 20 osób, a łączny czas poświęcony na digitalizację i opisywanie pocztówek wyniósł 2,000 godzin. Dzięki zaangażowaniu wolontariuszy, każdy z udostępnionych obrazów został dokładnie opisany i opatrzony odpowiednimi metadanymi.Do pliku markdown dodajemy program w języku R, który zostanie wykonany podczas generowania publikacji. Aby w pliki .rmd umieścić taki kod, musimy oddzielić go od tekstu - robimy to za pomocą ```. Użycie argumentu echo = FALSE spowoduje, że w naszym rozdziale pojawi się wyłącznie efekt programu w R (nie zawsze chcemy publikować kod źródłowy):
Oczywiście, po edycji plików źródłowych publikacji musimy ponownie wygenerować całość, np. w postaci gitbooka:
render_book("index.Rmd", "bookdown::gitbook", config_file="_bookdown.yml")Interaktywne wykresy w publikacjach bookdown
Interaktywne wykresy oferują zaawansowane funkcje, takie jak powiększanie, filtrowanie wybranych części wykresu czy tworzenie zrzutów ekranu. Aby dodać interaktywny wykres, skorzystamy z pakietu plotly:
# instalowanie pakietów
install.packages("webshot")
install.packages("plotly")
webshot::install_phantomjs()
# generowanie wykresu
library(plotly)
fig <- plot_ly(dane, x = ~miesiac, y = ~pocztowki_udostepnione, type = 'bar')
fig <- fig %>% layout(title = 'Pocztówki udostępnione w poszczególnych miesiącach',
xaxis = list(title = 'Miesiąc'),
yaxis = list(title = 'Pocztówki udostępnione'))
# podgląd wykresu
figWykresy w plotly budujemy zgodnie z metodami Grammar of Graphics.
Aby umieścić wykres w naszej publikacji, do pliku statystyki_zbiorow.Rmd znów dodajemy kod R:
```{r, echo = FALSE}
library(plotly)
fig <- plot_ly(dane, x = ~miesiac, y = ~pocztowki_udostepnione, type = 'bar')
fig <- fig %>% layout(title = 'Pocztówki udostępnione w poszczególnych miesiącach',
xaxis = list(title = 'Miesiąc'),
yaxis = list(title = 'Pocztówki udostępnione'))
fig
```W efekcie w webowej wersji naszego raportu możemy udostępnić interaktywny wykres, pozwalający zapoznać się z danymi dokumentującymi rozwój naszego projektu:
Podsumowanie
Biblioteka bookdown pozwala nie tylko na generowanie publikacji w rozmaitych formatach i stylach, ale także na łączenie tekstów z kodem R. Chociaż przygotowanie optymalnej postaci publikacji oraz danych i kodu, który będzie je wyświetlał, może wymagać wiele pracy, to daje szansę na prawdziwą automatyzację publikowania.
Wykorzystanie metod
Łączenie teksów z kodem R jest wykorzystywane do tworzenia systemów raportowania w korporacjach oraz w publikowaniu naukowym (szczególnie w podręcznikach).
Pomysł na warsztat
Praca z bookdown może stanowić integralną część warsztatów z języka R. Warsztaty mogą obejmować praktyczne ćwiczenia z tworzenia własnych książek, raportów i dokumentacji, łącząc podstawy automatycznego składu z podstawami tworzenia wykresów i tabel w R.


