
Wprowadzenie
Metody cyfrowe nie zawsze muszą być wykorzystywane w dużych i skomplikowanych projektach. Czasem po prostu warto je zastosować, żeby ułatwić sobie pracę. Niniejsza lekcja będzie przykładem takiego użycia.
Rozwijana od 1998 roku Internetowa Baza Filmu Polskiego to inicjatywa Państwowej Wyższej Szkoły Filmowej, Telewizyjnej i Teatralnej im. Leona Schillera w Łodzi. Zawiera opisy polskich filmów, fotosy z planów, kalendarium, bazę recenzji oraz zestawienia prezentujące listy filmów, które miały premierę w wybranym roku.
Cele lekcji
Celem lekcji jest praktyka automatycznego pozyskiwania danych z witryn WWW (web scraping) z wykorzystaniem języka R.
Efekty
Efektem naszej pracy będzie wykres, prezentujący liczbę filmów, które miały premierę każdego roku w latach 1902-2023 - taki jest zakres danych, jakie znajdziemy na Filmpolski.pl. Dane z roku 2024 pominiemy, ponieważ z oczywistych względów są jeszcze niepełne.
Wymagania
Skorzystamy z języka R i platformy Posit.cloud, na której trzeba założyć darmowe konto. Niezbędna jest znajomość podstaw języka R oraz wiedza o koncepcji Grammar of Graphics - metody budowania wykresów w R (z wykorzystaniem biblioteki ggplot2). Podstawy web scrapingu możemy poznać w jednej z pierwszych lekcji na humanistyka.dev.
Do pracy wykorzystamy też wtyczkę XPath Helper. Zainstalujmy ją w przeglądarce.
Część merytoryczna
Przypomnijmy: prawie każdą stronę internetową można traktować jako zbiór danych, jeśli tylko jesteśmy w stanie znaleźć w niej jakąś powtarzalną strukturę. Eksplorując tę strukturę, wyrażaną w kodzie HTML, możemy pobierać wartości z wybranych miejsc (elementów czy węzłów).
Przejdźmy na witrynę FilmPolski.pl, do strony, gdzie znajdziemy listę filmów fabularnych, które miały premierę w 2020 roku:
https://filmpolski.pl/fp/index.php?filmy_z_roku=2020&typ=1W przeglądarce wyświetla się nam długa lista tytułów z odnośnikami do opisów poszczególnych filmów:

Analiza kodu źródłowego strony
Podstawą naszej pracy będzie poprawne zlokalizowanie informacji, które następnie będziemy chcieli przetworzyć na dane. Automatycznie pobierzemy listy filmów dla każdego roku i policzymy tytuły. Jaki element kodu strony będzie nam potrzebny?
Najeżdżamy myszą na górę interesującej nas listy i prawym przyciskiem myszy wybieramy opcję Zbadaj - otworzy się konsola deweloperska, w której w zakładce Elements znajdziemy jej kod źródłowy.
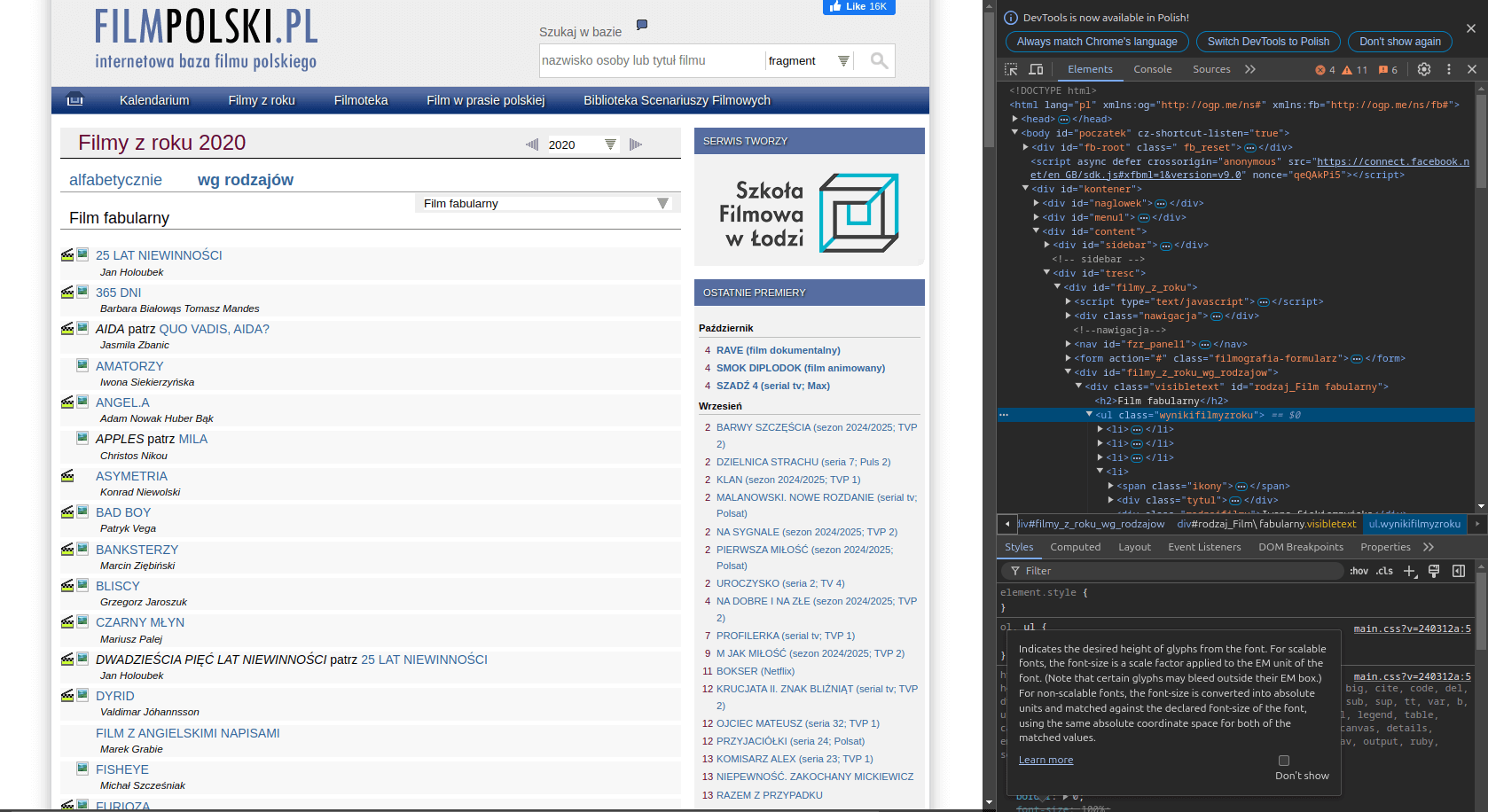
Spróbujmy zbadać ten kod źródłowy - fragment zamieściłem niżej:
<div class="visibletext" id="rodzaj_Film fabularny">
<h2>Film fabularny</h2>
<ul class="wynikifilmyzroku">
<li><span class="ikony"><a href="index.php/1251945" class="ikony-klaps"><img src="img1/klaps.png" alt="zwiastun" title="Zwiastun"></a><a href="index.php/1251945" class="ikony-zdjecie"><img src="img1/zdjecie.png" alt="zdjecie" onmouseover="return PokZdj(this, '1251945')" onmouseout="PokZdj(this, 1251945)"></a></span>
<div class="tytul"><a href="index.php/1251945">25 LAT NIEWINNOŚCI</a></div>
<div class="rodzajfilmu">Jan Holoubek</div>
</li>
<li><span class="ikony"><a href="index.php/1252009" class="ikony-klaps"><img src="img1/klaps.png" alt="zwiastun" title="Zwiastun"></a><a href="index.php/1252009" class="ikony-zdjecie"><img src="img1/zdjecie.png" alt="zdjecie" onmouseover="return PokZdj(this, '1252009')" onmouseout="PokZdj(this, 1252009)"></a></span>
<div class="tytul"><a href="index.php/1252009">365 DNI</a></div>
<div class="rodzajfilmu">Barbara Białowąs Tomasz Mandes</div>
</li>
<li><span class="ikony"><a href="index.php/1254210" class="ikony-klaps"><img src="img1/klaps.png" alt="zwiastun" title="Zwiastun"></a><a href="index.php/1254210" class="ikony-zdjecie"><img src="img1/zdjecie.png" alt="zdjecie" onmouseover="return PokZdj(this, '1254210')" onmouseout="PokZdj(this, 1254210)"></a></span>
<div class="tytul"><span class="tytulnieindeksowany">AIDA</span> patrz <a href="index.php/1254210">QUO VADIS, AIDA?</a></div>
<div class="rodzajfilmu">Jasmila Zbanic</div>
</li>
...
</ul>
</div>Widzimy, że interesujące nas informacje znajdują się w kontenerze o klasie visibletext, w liście <ul> o klasie wynikifilmyzroku i w elementach <li>:
<div class="visibletext" id="rodzaj_Film fabularny">
<ul class="wynikifilmyzroku">
<li>...</li>
<li>...</li>
</ul>
</div>Naszą kwerendę w źródle HTML możemy opisać w następujący sposób:
policz wszystkie unikalne wartości elementów <li> w elemencie <ul> o klasie wynikifilmyzroku, która znajduje się w elemencie <div> o klasie visibletextNiestety, nie możemy zrobić takiej kwerendy za pomocą poleceń w języku naturalnym (chociaż można przetestować to w ChatGPT 🤓). Skorzystajmy raczej z języka XPath, dzięki któremu możemy swobodnie wskazywać interesujące nas elementy źródła badanej strony.
Testowanie kwerend XPath
Zwróćmy uwagę, że każdy element naszej listy (<li>) ma dość skomplikowaną strukturę, a uważne spojrzenie na przykładowe dane z 2020 roku ujawnia nam pewien problem: tytuły filmów powtarzają się. Przykładowo, film Jana Holoubka, który miał premierę tamtego roku, zapisywany jest równocześnie jako DWADZIEŚCIA PIĘĆ LAT NIEWINNOŚCI, SPRAWA TOMKA KOMENDY oraz 25 LAT NIEWINNOŚCI. Takie duplikujące się filmy będą zaburzać poprawność naszego liczenia - musimy sobie jakoś z tym poradzić.
Jeśli na liście pojawia się alternatywny zapis tytułu filmu, obok niego dodawana jest fraza patrz i odnośnik do standardowego tytułu:
DWADZIEŚCIA PIĘĆ LAT NIEWINNOŚCI patrz 25 LAT NIEWINNOŚCI
SPRAWA TOMKA KOMENDY patrz 25 LAT NIEWINNOŚCI
KOBIETA W NOCY patrz A WOMAN AT NIGHT
LOVE TASTING patrz OSTATNI KOMERSMożemy zmodyfikować naszą kwerendę tak, żeby zliczała unikalne wartości tekstu linków, które pojawiają się w elementach <li>.
policz wszystkie unikalne wartości tektu elementów <a> w elementach <li> w elemencie <ul> o klasie wynikifilmyzroku, która znajduje się w elemencie <div> o klasie visibletextTak, nie jest to specjalnie prosta kwerenda, ale w praktyce web scrapingu korzysta się często z nie zawsze oczywistych zapytań XPath - nie mamy wpływu na strukturę strony, więc aby pozyskać dane, musimy się dostosować.
Możemy spróbować kwerendy XPath o takiej postaci:
count(//div[@class='visibletext']/ul[@class='wynikifilmyzroku']/li//a/text())Krótkie wyjaśnienie poszczególnych elementów:
- count(…) - funkcja ta zlicza liczbę elementów pasujących do podanego wyrażenia,
- //div[@class=’visibletext’] - wybiera każdy element <div> o klasie visibletext w dokumencie,
- /ul[@class=’wynikifilmyzroku’] - wśród wybranych <div> znajduje element <ul> o klasie wynikifilmyzroku,
- /li//a/text() - w obrębie tego <ul> znajduje wszystkie elementy <li> i w nich element <a> i wybiera jego tekst.
Warto zwrócić uwagę na podwójny znak // - w ten sposób w XPath wskazujemy na element (węzeł) niezależnie od jego miejsca w dokumencie. W przypadku naszej kwerendy chcemy zwrócić tekst elementów <a> niezależnie od tego, w jakim miejscu elementu <li> się znajduje.
Możemy tę kwerendę przetestować za pomocą wtyczki XPath Helper. Po jej uruchomieniu w lewy panel wklejamy kwerendę, po prawej możemy podejrzeć jej wynik:
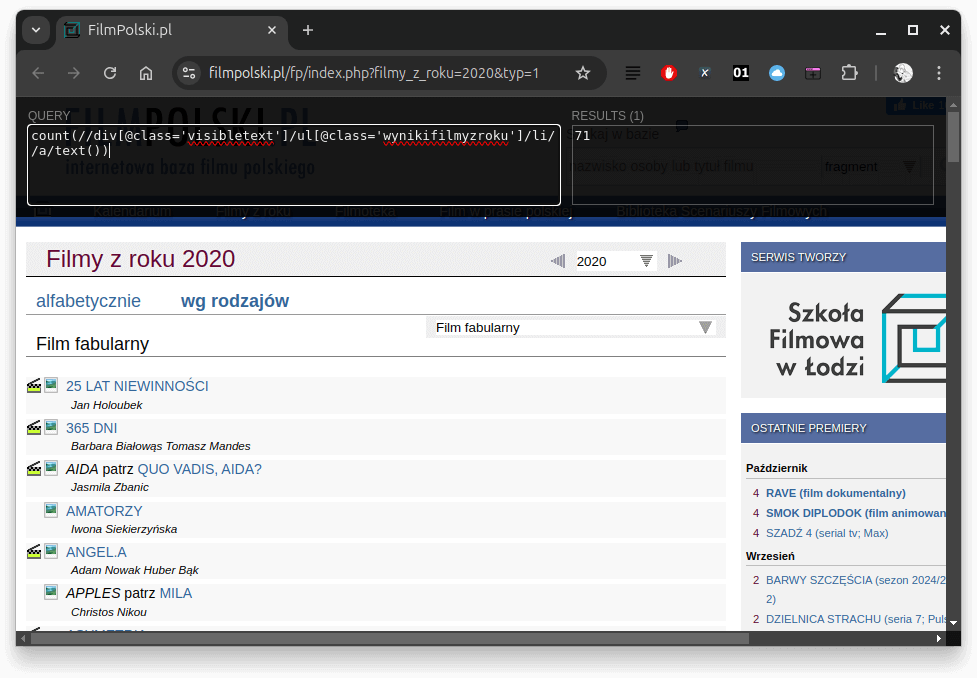
Uwaga! W naszej kwerendzie wciąż jednak brakuje pewnego elementu - możemy za pomocą XPath zliczyć wszystkie teksty linków z listy, ale nie potrafimy zliczyć ich unikalnych wartości. XPath nie ma po prostu wbudowanej takiej funkcji. Na szczęście kwerendy wykonywać bęziemy za pomocą R, a ten język daje nam narzędzia to takiego przefiltrowania danych. Ostatecznie, użyjemy takiej kwerendy
//div[@class='visibletext']/ul[@class='wynikifilmyzroku']/li//a/text()a filtrowanie wartości i ich zliczanie zostawimy wybranym metodom R.
Piszemy scraper w R
Przechodzimy do Posit.cloud i zakładamy nowy projekt. Nasz scraper napiszemy z wykorzystaniem biblioteki xml2. Zainstalujmy ją najpierw i wczytajmy do środowiska:
install.packages("xml2")
library(xml2)Napiszmy nasz scraper jako funkcję, którą uruchamiać będziemy dla każdego roku z okresu 1902-2023. Przypomnijmy, że funkcję w R definiujemy w taki sposób:
nazwafunkcji <- function(argument) {
# body funkcji
}Aregumentem naszej funkcji będzie rok, a w body wykorzystamy metody udostępniane przez xml2:
count_movies <- function(year = 2020) {
# upewnijmy się, że biblioteka xml2 jest wczytana do środowiska
library(xml2)
# budujemy dynamicznie adres URL (w zależności od wybranego roku)
# jako standardowy ustawiliśmy rok 2020
# filmy fabularne = type=1
fp_url <- paste0("https://filmpolski.pl/fp/index.php?filmy_z_roku=",year,"&typ=1")
# metoda read_html ściąga z podanego adresu URL dokument HTML/XML
fp_page <- read_html(fp_url)
# definiujemy kwerendę XPath, którą poruszamy się po dokumencie
# będziemy pobierać teksty wszystkich linków z listy
xpath <- "//div[@class='visibletext']/ul[@class='wynikifilmyzroku']/li//a/text()"
# tutaj wykonujemy kwerendę xpath na naszym dokumencie fp_page
# xml_find_all znajduje wszystkie pasujące elementy
fp_movies <- xml_find_all(fp_page, xpath)
# tutaj przetwarzamy zbiór znalezionych elementów (węzłów) i zliczamy unikalne wartości
fp_count <- length(unique(unlist(as_list(fp_movies))))
# funkcja zwraca liczbę i kończy się
return(fp_count)
}Końcówka kodu naszego scrapera wymaga dodatkowego wyjaśnienia, bo dużo się w niej dzieje 🤓:
fp_count <- length(unique(unlist(as_list(fp_movies))))Taki kod czytamy zawsze od środka (od fragmentu, który jest najgłębiej umieszczony w nawiasach). fp_movies to zbiór węzłów (elementów), w którym znajdują się teksty linków (tytuły filmów). Metodą as_list konwertujemy ten zbiór na standardową listę R, a metodą unlist na zwykły wektor wieloelementowy. Na danych w takiej postaci możemy już wykonać funkcję unique - usunąć wszystkie duplikaty. Poleceniem length badamy długość tak przefiltrowanego wektora - to liczba filmów fabularnych, które miały premierę w danym roku.
Uruchamiamy scraper w pętli
Nasza funkcja wydaje się być uniwersalna - możemy zastosować ją do dowolnego roku. Skorzystajmy z tej możliwości i przygotujmy pętlę, która wykona funkcję count_movies dla wszystkich lat z okresu 1902-2023.
Przypomnijmy, że pętla (loop) pozwala na wielokrotne wykonanie określonego fragmentu kodu (lub określonej funkcji) dla każdego elementu w wektorze, liście lub innej strukturze danych, którą można iterować. Iterowanie to proces przechodzenia przez elementy określonego zbioru - w naszym przypadku będą to lata od 1902 do 2023, a więc 1902, 1903, 1904 itd.
Nasze dane wpisywać będziemy do ramki danych (data frame). Ramka danych przechowuje dane w formie tabelarycznej, gdzie każda kolumna reprezentuje zmienną, a każdy wiersz odpowiada pojedynczemu obserwowanemu przypadkowi (rekordowi):
movie_stats <- data.frame()Skorzystajmy teraz z pętli for, której kod będziemy wykonywać dla wszystkich liczb w zakresie 1902:2023:
for(y in 1902:2023) {
# w każej iteracji rok (1902, 1903 itd.) przypisywany jest do y
# wykonywana jest funkcja count_movies, do której przekazujemy argument (rok)
c <- count_movies(y)
# do ramki danych dodajmy wiersz (generowany jako lista), w którym znajduje się
# informacja o roku i liczbie filmów
movie_stats <- rbind(movie_stats, list(
year = y,
movies_count = c
))
# dodajemy krótką informację, która będzie wyświetlana przy każdej iteracji
cat(paste0("W ",y, " znalazłem filmów: ", c, "\n"))
# Wprowadzamy 1 sek. przerwy między kolejnymi iteracjami, żeby nie zaburzyć działania serwera
Sys.sleep(1)
}Jeśli uruchomimy tę pętlę, w konsoli zaczną wyświetlać się informacje o zebranych liczbach filmów. Ostatecznie wszystkie dane znajdziemy w ramce danych movie_stats.
Przygotowanie wykresu
Nasza ramka zawiera dwie kolumny (year i movies_count). Możemy wyeksportować ją do CSV i w Excelu wygenerować wykres, ale ponieważ i tak już pracujemy w R, przygotujmy wykres z wykorzystaniem biblioteki ggplot2. Pamiętajmy, że ta biblioteka spełnia założenia gramatyki wykresów, a więc musimy złożyć nasz wykres z kilku warstw.
Instalujemy pakiet i wczytujemy go do środowiska:
install.packages("ggplot2")
library(ggplot2)Wykres słupkowy tworzymy za pomocą takiego kodu:
ggplot(movie_stats, aes(x = year, y = movies_count)) +
geom_bar(stat = "identity", fill = "steelblue") +
labs(title = "Premiery polskich filmów fabularnych (1902-2023)", x = "Rok", y = "Liczba premier") +
theme_minimal()Możemy teraz zobaczyć, jak działa Grammar of Graphics na żywo - znakiem + łączymy ze sobą kolejne warstwy wykresu:
- funkcja ggplot przyjmuje jako argument naszą ramkę danych, ustawiamy też odpowiednią estetykę - która jest tutaj rozumiana jako połączenie między zmiennymi a efektem wizualnym (aesthetic is a mapping between a visual cue and a variable) - wskazujemy, jakie dane mają być wyświetlane w osi X i Y,
- funkcja geom_bar tworzy kolejną warstwę wykresu - wypełnia go słupkami, których wartość bazuje bezpośrednio (stat = “identity”) na wartościach zmiennej movies_count. Słupki wypełniamy kolorem steelblue,
- za pomocą labs dodajemy warstwę meta - opisy osi X i Y oraz tytuł wykresu,
- ostatnią warstwą jest warstwa kolorystyczna - korzystamy z wybranego motywu.
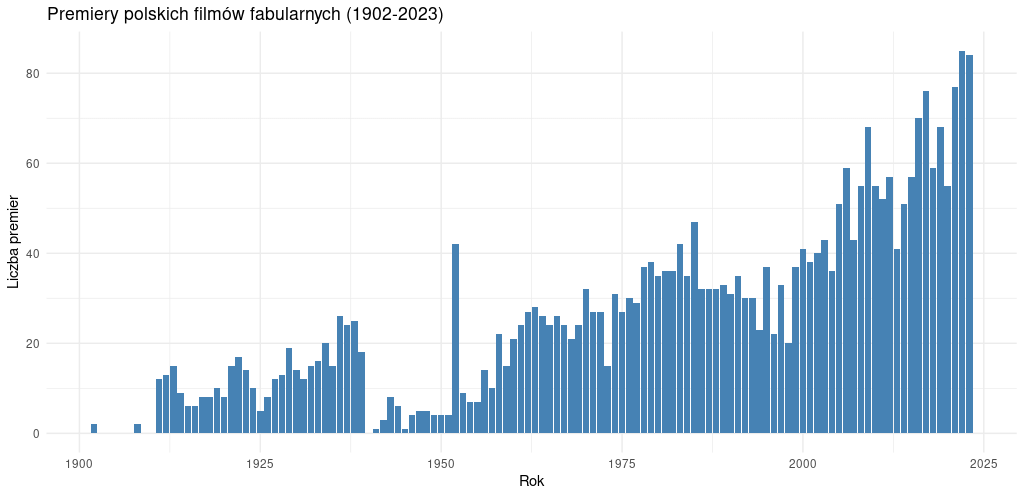
Na wykresie doskonale widać okołowojenną zapaść polskiej produkcji filmowej oraz gwałtowny przyrost nowych filmów fabularnych w ostatnich dekadach.
Podsumowanie
Umiejętność budowania własnych scraperów wydaje się jedną z kluczowych kompetencji w ramach cyfrowej humanistyki. W sieci WWW znajdziemy bardzo wiele informacji i danych, które są dostępne od ręki, ale trudno po nie sięgnąć, jeśli nie zautomatyzujemy tego procesu. Język R może być skutecznie użyty do przygotowania własnego scrapera, a Posit.cloud oferuje wygodne środowisko do testowania własnych narzędzi i pozyskiwania za ich pomocą danych badawczych.
Wykorzystanie metod
O znaczeniu web scrapingu we współczesnej nauce pisałem w poprzedniej lekcji, przywołując pojęcie APIkalipsy. Nie możemy oczekiwać, że wszystkie interesujące nas dane będą dostępne przez darmowe i wygodne API - podstawowe kompetencje w zakresie budowania scraperów dają nam bardziej podmiotową pozycję w relacjach z wydawcami witryn i serwisów internetowych.
Pomysł na warsztat
Lekcja jest gotowym komponentem do warsztatu z podstaw R. W takim warsztacie warto podkreślić konieczność dobrego przygotowania kwerendy XPath oraz zwrócić uwagę na potencjalne błędy i nieścisłości, które mogą pojawiać się w strukturze analizowanych stron.


