
Wprowadzenie
Digitalizacja dziedzictwa to jedno z najważniejszych zjawisk w kulturze ostatnich dekad. Wpływa nie tylko na dostępność zbiorów bibliotek, archiwów i muzeów, ale pozwala też na wykształcanie się nowych sposobów ich wykorzystania. Metody digitalizacji, przebieg tych procesów oraz efekty społeczne opisywane są w literaturze fachowej, tekstach naukowych, podręcznikach i tutorialach. O digitalizacji - choćby ze względu na jej koszty czy wchodzenie w materię prawa autorskiego - dyskutuje się też na forum politycznym.
Badając dyskurs polityczny na temat digitalizacji dziedzictwa możemy rozpoznawać wartości, jakie się jej nadaje, oceniać postawy wokół niej, zastanawiać się, jak motywuje się finansowanie tego typu przedsięwzięć. Warto podkreślić też, że pod pojęciem digitalizacji w debacie politycznej pojawiają się także wątki dalekie od działalności instytucji kultury i dziedzictwa, takie jak cyfryzacja administracji państwowej czy obecność określonych przepisów w prawie pracy.
Także samo pojęcie digitalizacji jest obecne w języku polskim już od… lat 30. XX wieku. Jak piszą Jakub Bobrowski i Piotr Żmigrodzki,
wyraz digitalizacja, odnoszony dziś przede wszystkim do czynności i procesów związanych z techniką komputerową funkcjonował w polszczyźnie już przynajmniej od lat 30. XX wieku jako termin medyczny i oznaczał działanie na organizm pacjenta lekami z naparstnicy (łac. digitalis). Był jednak nieobecny w słownikach ogólnych polszczyzny. W latach 70. XX wieku wyraz został ponownie zapożyczony, z języka angielskiego, w znaczeniu ‘wytwarzanie cyfrowych kopii istniejących realnie obiektów’ i w tym znaczeniu występuje w tekstach języka polskiego do dziś, tworzą się także jego inne znaczenia.
Cele lekcji
Celem lekcji jest nauka podstaw tworzenia wykresów w R z wykorzystaniem pakietów ggplot2 i plotly oraz zwrócenie uwagi na Korpus Dyskursu Parlamentarnego. To opracowany przez Instytut Podstaw Informatyki PAN i konsorcjum CLARIN-PL zbiór anotowanych językowo transkrypcji wystąpień i wypowiedzi parlamentarnych od 1919 roku do dziś (korpus jest na bieżąco aktualizowany danymi z posiedzeń).
Przygotowanie podstawowych danych do wizualizacji wymagać będzie od nas przetworzenia oryginalnych danych z korpusu - to okazja do pracy z ramkami danych oraz poznania podstaw przetwarzania tekstów w R.
Lekcja podzielona jest na kilka części.
Efekty
Efektem naszej pracy będą podstawowe wizualizacje (wykresy), ilustrujące parlamentarną dyskusję wokół digitalizacji dziedzictwa.
Wymagania
Będziemy pracować w R, przyda się więc darmowe konto w Posit.cloud oraz umiejętność korzystania z tej aplikacji. Podstawy składni języka R omawialiśmy w jednej z poprzednich lekcji.
Część merytoryczna
Źródłem treści do naszej pracy będzie Korpus Dyskursu Parlamentarnego:
Korpus Dyskursu Parlamentarnego jest zbiorem anotowanych lingwistycznie tekstów z posiedzeń plenarnych Sejmu i Senatu RP, interpelacji i zapytań poselskich oraz posiedzeń komisji od roku 1919 do chwili obecnej (są stale uzupełniane materiałami z kolejnych posiedzeń). Teksty opisane metadanymi oraz przetworzone automatycznie narzędziami lingwistycznymi (do segmentacji, analizy morfoskładniowej, rozpoznawania grup składniowych i nazw własnych) są dostępne do przeszukiwania oraz pobrania. Wszystkie teksty pochodzą z serwisów Sejmu i Senatu RP i zostały udostępnione dzięki uprzejmości Kancelarii Sejmu RP, Kancelarii Senatu RP oraz Biblioteki Sejmowej.
Transkrypcje parlamentarne nie są chronione prawem autorskim i możemy je swobodnie przetwarzać oraz udostępniać. Informacje o możliwości pobrania całego korpusu w różnych postaciach znajdują się na tej stronie - nieprzetworzone teksty w postaci plików TEI to około 1.7GB, anotowane - 34.4GB.
Więcej o korpusie i metodach jego przygotowania można przeczytać w opracowaniu Macieja Ogrodniczuka Polish Parliamentary Corpus (2018).
Przygotowanie konkordancji
Nie będziemy pracować z całym korpusem - wystarczą nam wyłącznie te wypowiedzi, w których pojawia się słowo digitalizacja lub digitalizować. To prosty filtr, który też łatwo podważyć - wybierajac wypowiedzi ten sposób pomijamy te, w których jest mowa o digitalizacji nie wprost (nie pojawia się to słowo kluczowe). W dobrze przygotowanym badaniu powinniśmy wybrać starannie te ustawy, posiedzenia czy pytania, których materia dotyczy prawa autorskiego czy funkcjonowania instytucji dziedzictwa i dopiero na ich podstawie gromadzić wypowiedzi. Ponieważ jednak naszym głównym celem jest poznawanie metod pracy z tekstem i wykresami w R, wystarczy nam zastosowanie takiego prostego filtra.
Skorzystajmy z wyszukiwarki korpusowej:
Z lekcji poświęconej analizom korpusowym wiemy, jak ważne jest stosowanie formy podstawowej (słownikowej) słowa w pracy z korpusem. Zastosowanie lemmy pozwoli nam zgromadzić wszystkie fragmenty wypowiedzi, w których pojawia się słowo digitalizacja, bez względu na to, w jakiej postaci tam występuje (digitalizacji, digitalizacją itp.).
Skorzystanie z wyszukiwarki korpusowej pozwoli nam wygenerować konkordancję dla słowa digitalizacja i digitalizować. Konkordancja to taka forma prezentacji danych korpusowych, które umożliwia zrozumienie i analizę użycia słów w danym korpusie. Składa się z uporządkowanej listy wszystkich wystąpień wyrazu lub frazy, zazwyczaj z podaniem kontekstu, w jakim się pojawiają.
Na stronie wyszukiwarki klikamy opcję KONSTRUKTOR ZAPYTAŃ i jako Atrybut segmentu wybieramy forma podstawowa:
Wyszukiwarka zwróciła 1755 wyników, które możemy pobrać to pliku CSV (przycisk na dole strony):
Plik z konkordancją dostępny jest na GitHub.
Import do ramki danych
Czas zalogować się na Posit.cloud i założyć nowy projekt. Pracę z naszą konkordancją w R zacznijmy od zaimportowania pliku CSV concordance.csv do środowiska. W tym celu musimy zaimportować sam plik do Posit.cloud (używamy opcji Upload w prawym dolnym panelu okna). Kiedy plik jest już na miejscu, możemy zbudować naszą ramkę danych:
c <- read.csv('concordance.csv', fileEncoding = "UTF-8", stringsAsFactors = FALSE)Metoda read.csv() przyjęła takie parametry:
- ścieżka do pliku źródłowego (plik znajduje się w katalogu głównym naszego projektu),
- kodowanie znaków (standardowo jako UTF-8),
- użycie stringsAsFactors = FALSE pozwoli nam uniknąć interpretowania kolumn tekstowych jako faktorów.
Faktory w R to specjalny typ danych używany do reprezentowania zmiennych kategorycznych, które mają skończoną liczbę unikalnych wartości. Faktory są przydatne, gdy dane mają kilka powtarzających się wartości, takich jak płeć, kolory, stany lub inne kategorie. Posiadanie kolumn faktorów w praktyce ogranicza możliwość ich edycji czy też dodawania nowych wierszy, jeśli znajdują się wśród nich wpisy spoza katalogu istniejących już faktorów.
Po poprawnym imporcie, możemy sprawdzić podstawową strukturę danych:
# polecenie names(c) wyświetli spis wszystkich kolumn (zmiennych)
names(c)
# [1] "Lewy.kontekst" "Rezultat" "Prawy.kontekst" "Interpretacja"
# [5] "Nazwa.własna" "Relacja.zależnościowa" "Lemat.nadrzędnika" "Izba"
# [9] "Typ" "Autor" "Mówca" "Przynależność.mówcy"
#[13] "Rola.mówcy" "Płeć.mówcy" "Komisja" "Data"
#[17] "Timestamp" "Rok" "Ustrój" "Numer.kadencji"
#[21] "Etykieta" "Tytuł" "Sesja" "Dzień"
#[25] "Numer" "Część"
# polecenie nrow(c) wyświetli liczbę wierszy (obserwacji)
nrow(c)
#[1] 1755Stosowanie nazw kolumn, zawierających kropki i polskie znaki nie jest najlepszym rozwiązaniem - dlatego zmieńmy je. Napiszmy oryginalne nazwy w taki sposób:
names(c) <- c(
"lewyKontekst", "rezultat", "prawyKontekst", "interpretacja",
"nazwaWlasna", "relacjaZaleznosciowa", "lematNadrzednika", "izba",
"typ", "autor", "mowca", "przynaleznoscMowcy",
"rolaMowcy", "plecMowcy", "komisja", "data",
"timestamp", "rok", "ustroj", "numerKadencji",
"etykieta", "tytul", "sesja", "dzien",
"numer", "czesc"
)W nazwach kolumn zastosowaliśmy notację camelCase, która jest dobrym sposobem na zachowanie czytelności ciągów tekstowych pozbawionych znaków interpunkcyjnych (zapis prawyKontekst jest bardziej czytelny niż prawykontekst).
Podstawowe statystyki
Obiekt c to ramka danych. Ramka danych (data frame) to jedna z podstawowych struktur danych w języku R. Jest szeroko stosowana do przechowywania danych tabelarycznych. To po prostu dwuwymiarowa tabela, w której każda kolumna reprezentuje zmienną, a każdy wiersz odpowiada obserwacji. Kolumny mogą zawierać różne typy danych, takie jak liczby całkowite, zmiennoprzecinkowe, ciągi znaków, faktory, czy daty. Ramki danych przypominają struktury danych znane z arkuszy kalkulacyjnych lub baz danych, co ułatwia ich zrozumienie i obsługę.
Możemy teraz zastosować funkcję table. Podstawowym zadaniem tej funkcji jest zliczanie, ile razy każda unikalna wartość występuje w danym wektorze lub kolumnie danych. Jeśli użyjemy tej funkcji na kolumnie rok, będziemy mogli sprawdzić, w jakich latach najczęściej pojawiały się w naszym korpusie wypowiedzi o digitalizacji. Zapiszmy wynik tego działania do obiektu years.
years <- table(c$rok)Pamiętajmy, że pracując z ramką danych, możemy wybierać dowolną kolumnę za pomocą znaku dolara (c$rok).
W efekcie otrzymamy obiekt o klasie table, z którym trudno pracować. Spróbujmy zamienić go na ramkę danych:
years <- as.data.frame(years, stringsAsFactors = FALSE)
names(years)
# [1] "Var1" "Freq"
names(years) <- c("rok","wystapienia")W naszym kodzie sprawdziliśmy też nazwy kolumn nowej ramki danych. Aby dane były bardziej czytelne, zmieniliśmy je.
Kolumna wystapienia zawiera liczby, więc możemy na niej przeprowadzić proste operacje statystyczne, np. policzyć średnią i medianę:
mean(years$wystapienia)
# [1] 52.24
median(years$wystapienia)
# [1] 47Wykres liniowy w ggplot2
W jednej z poprzednich lekcji mówiliśmy o bibliotece ggplot2, podkreślając, że działa na podstawie założeń Grammar of graphics. Oznacza to, że nasz wykres będzie składał się z rozmaitych warstw, które będziemy musieli programistycznie połączyć. Brzmi to jak coś skomplikowanego, ale takie wcale nie jest. Skorzystajmy z przygotowanych przed chwilą danych rocznych.
w1 <- ggplot(data = years, aes(x = rok, y = wystapienia)) +
geom_line(aes(group = 1)) +
labs(x = "Rok", y = "Liczba wystąpień", title = "Wystąpienia parlamentarne na temat digitalizacji")ggplot2 używa geom_line() do rysowania linii na wykresach na podstawie danych. Na naszym wykresie wszystkie punkty wygenerowane z danych powinny być połączone w jedną linię - niestety standardowo funkcja geom_line() nie ułoży tych punktów w ten sposób. Żeby wszystkie punkty danych zostały potraktowane jako jedna grupa, dodajemy group = 1 w geom_line().
aes to skrót od słowa “aesthetic” (estetyka) i jest funkcją w ggplot2 służącą do mapowania zmiennych na estetyki (cechy wizualne) wizualizacji - to bezpośrednie wdrożenie zasad grammar of graphics.
Nasz kod generujący wykres łączy ze sobą trzy warstwy:
- ggplot2() - tutaj definiujemy dane źródłowe oraz ich podstawowy układ (osie X i Y),
- geom_line - tutaj definiujemy typ wykresu i sposób, w jaki mają zostać użyte dane do jego narysowania,
- labs - tutaj definiujemy metadane - opisy osi oraz tytuł wykresu.
Poszczególne warstwy wykresu łączymy znakiem +. W efekcie otrzymujemy:
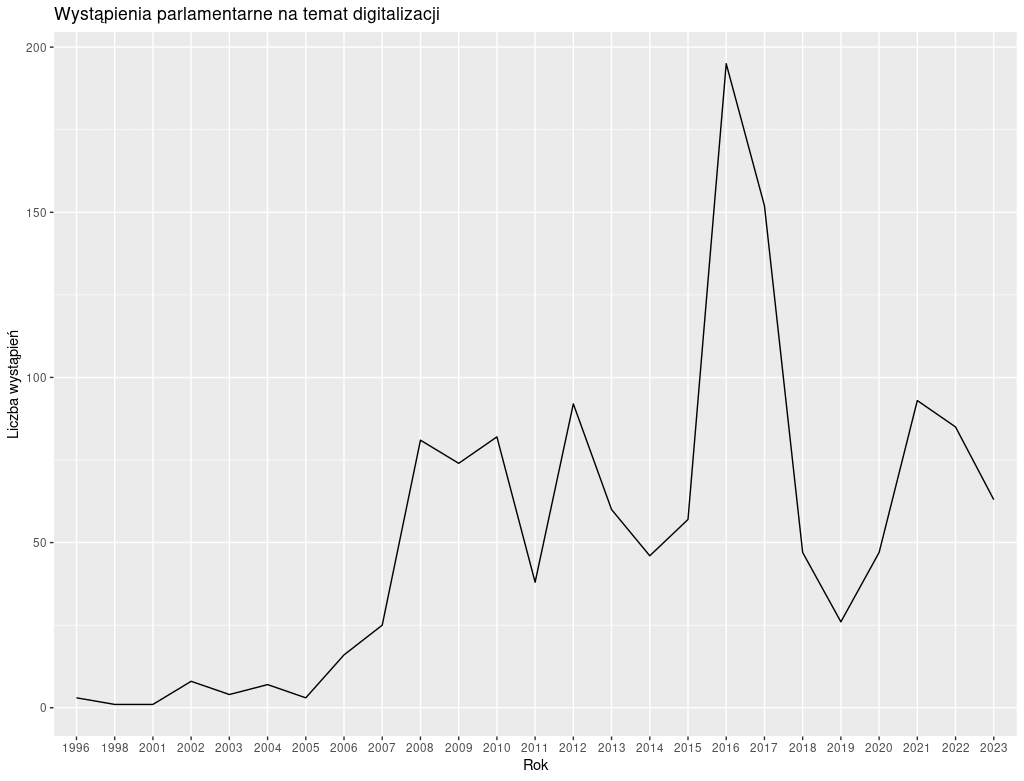
Widzimy wyraźny wzrost liczby wystąpień na temat digitalizacji w latach 2016-2017 - być może ma to związek z programem operacyjnym Polska Cyfrowa, który ogłoszono w sierpniu 2015 roku i w którym przeznaczono ponad 600 mln złotych na programy udostępniania w internecie zasobów kultury i nauki.
Interpretując ten wykres pamiętajmy, że w naszych danych nie wszystkie wystąpienia mają oznaczenie roku. Możemy to sprawdzić, posługując się znaną nam już funkcją table:
nodata <- table(is.na(c$rok))
nodata
#FALSE TRUE
#1306 449
total <- sum(nodata)
total
#[1] 1755
nodata / total * 100
#
# FALSE TRUE
# 74.41595 25.58405 Tym razem użycie table nie miało nam pokazać pełnej statystyki wszystkich lat, ale statystykę tego, czy rok jest podany w danych, czy też nie - stąd użycie is.na(c$rok). NA w R oznacza brakującą lub niedostępną wartość w zbiorze danych. Jest używana do reprezentowania danych, które są nieznane, pominięte lub nie zostały zebrane. Wartości NA mogą występować w różnych typach danych, takich jak liczby, teksty czy znaczniki czasu i są automatycznie ignorowane w wielu operacjach obliczeniowych i analizach statystycznych w R.
Jeśli uważnie przyjrzymy się danym z table, pewne informacje o roku wypowiedzi moglibyśmy znaleźć także w kolumnie etykieta, zawierającej sygnatury takie jak:
c$etykieta[1:10]
# [1] "200507-sjm-kspxx-00029-01" "200507-sjm-kspxx-00075-01" "200507-sjm-kspxx-00021-01" "200507-sjm-aswxx-00063-01"
# [5] "200507-sjm-aswxx-00063-01" "200507-sjm-aswxx-00063-01" "200507-sjm-aswxx-00063-01" "200711-sjm-kspxx-00044-01"
# [9] "200711-sjm-kspxx-00044-01" "200711-sjm-kspxx-00044-01"Skorzystajmy z tego już w kolejnej części tej lekcji, ale zwróćmy uwagę na zapis c$etykieta[1:10] - zastosowanie indeksu [1:10] pozwoliło wybrać pierwszych 10 wierszy z kolumny etykieta.
Dopracowywanie wykresu
Możemy w łatwy sposób zmienić wygląd naszego wykresu. Służą do tego motywy (themes), dostępne zarówno w bibliotece ggplot2, jak i osobno w bibliotece ggthemes. Skorzystanie z nich jest bardzo proste - po prostu do gotowego wykresu dodajemy nową warstwę:
w1 + theme_linedraw()W efekcie:
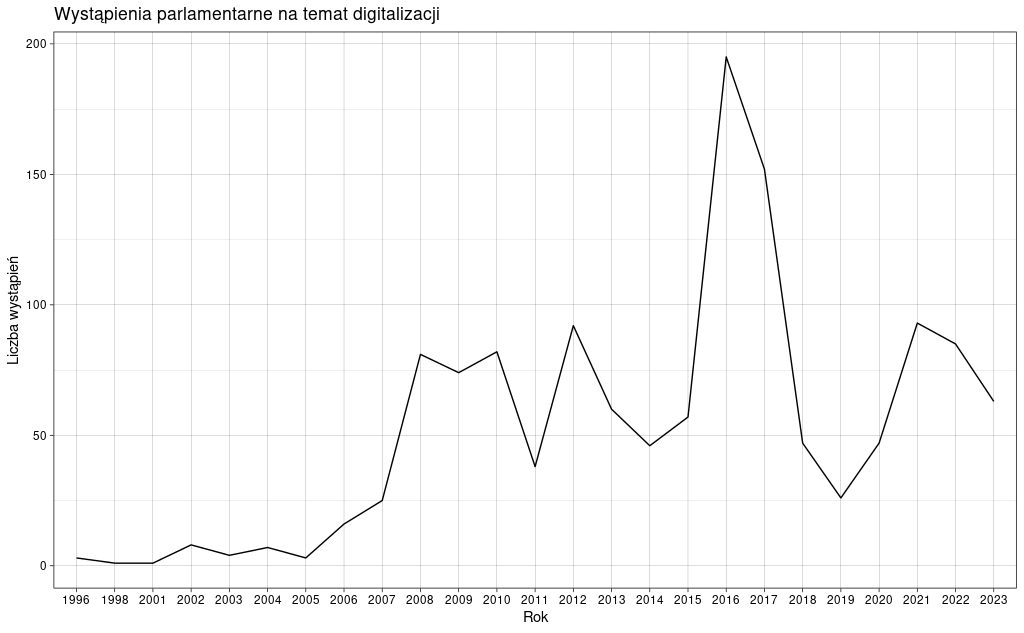
Aby skorzystać z pakietu ggthemes musimy go zainstalować i wczytać do środowiska. Potem praca z motywami wygląda tak samo jak w przypadku ggplot2:
install.packages("ggthemes")
library(ggthemes)
w1 + theme_solarized()Otrzymujemy:
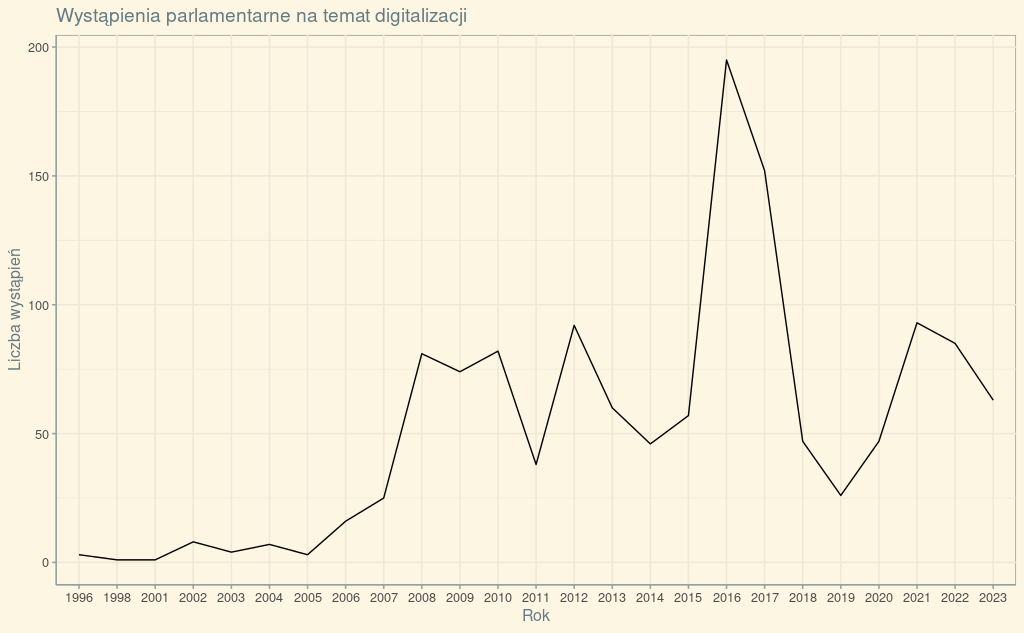
Motywy z ggplot2 i z ggthemes mogą być dodatkowo konfigurowane. Sprawdźmy, jak to działa w przypadku użytego przez nas wyżej theme_solarized():
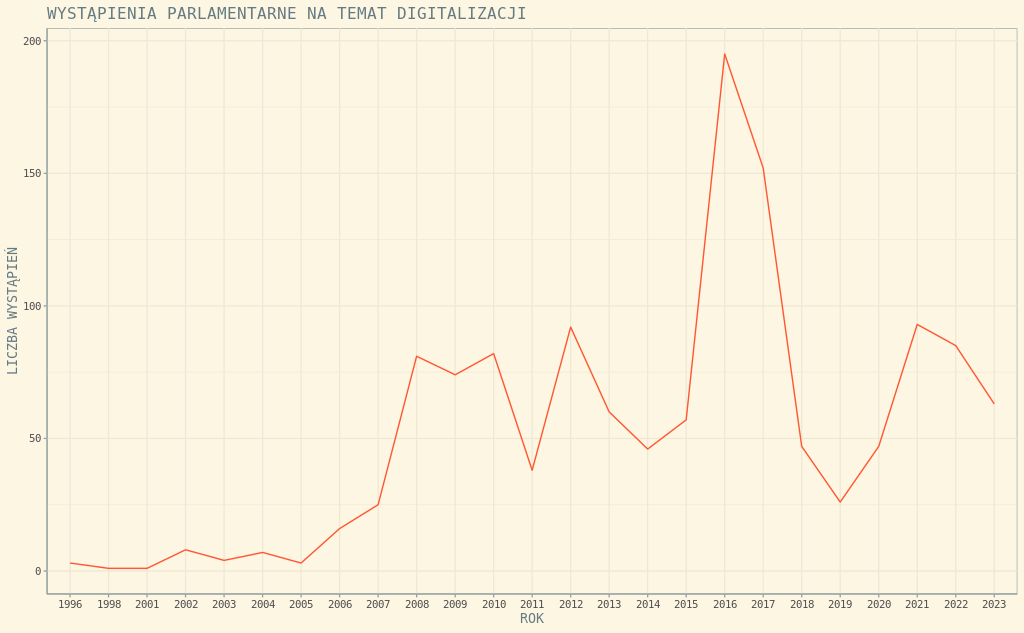
# tworzymy nowy obiekt zawierający wykres
w2 <- ggplot(data = years, aes(x = rok, y = wystapienia)) +
geom_line(aes(group = 1), color = "#FF5733") +
labs(x = "ROK", y = "LICZBA WYSTĄPIEŃ", title = "WYSTĄPIENIA PARLAMENTARNE NA TEMAT DIGITALIZACJI") +
theme_solarized(base_size = 10, base_family = "monospace", light = TRUE)
w2 # wyświetlenie wykresuZwróćmy uwagę, że nie tylko zmieniliśmy ustawienia fontów w theme_solarized(), ale też kolor linii wykresu w geom_line():
Interaktywny wykres (plotly)
W lekcji poświęconej automatycznemu składowi publikacji w bookdown pojawił się wątek interaktywnych wykresów. Aby je przygotować, potrzebujemy biblioteki plotly. Praca z nią jest bardzo prosta - gotowy obiekt zawierający wszystkie warstwy wykresu przekazujemy jako argument do funkcji ggplotly:
Wykres podejrzeć można też pod tym adresem. W razie potrzeby taki wykres możemy bez problemu umieścić w publikacji markdown.
Podsumowanie
R pozwala na budowanie wykresów zgodnie z założeniami Grammar of Graphics i automatyzację ich generowania. W połączeniu z pakietem bookdown ułatwia budowę nawet złożonych systemów raportowania. Do budowania takich systemów można użyć też Shiny, zestawu narzędzi do publikacji aplikacji webowych.
Dane wykorzystywane w tej lekcji pochodzą z Korpusu Dyskursu Parlamentarnego - warto poznać to narzędzie i wykorzystywać je w badaniach i analizach.
Wykorzystanie metod
O dużej popularności biblioteki ggplot2 może świadczyć fakt, że teksty naukowe, publikowane łącznie z udostępnioną biblioteką (to standardowa procedura przy tworzeniu bibliotek do R) są cytowane kilka tysięcy razy. Pewna część artykułów je cytujących to opracowania na temat wdrożeń ggplot2 do wizualizacji specyficznych danych - pamiętajmy, że każdy wykres jest już pewną interpretacją. Cytuje się też tę bibliotekę w artykułach, które po prostu wykorzystują metody ggplot2 do generowania standardowych wykresów.
Pomysł na warsztat
Lekcja może być częścią warsztatu wprowadzającego do R.
Poza tym kontekstem, uczestnicy warsztatów mogą korzystać z danych Korpusu Dyskursu Parlamentarnego do analizowania języka określonych ugrupowań politycznych albo sposobu opisywania rzeczywistości społecznej na poziomie parlamentarnym. Do pracy z tymi danymi nie potrzeba programowania w R - wystarczy zwykły arkusz kalkulacyjny. W ramach warsztatu wypracować można takie sposoby łączenia i zestawiania ze sobą danych z poszczególnych kolumn, które pozwolą zbudować głębsze interpretacje. Przykładowo, zestawienie danych z kolumn Płeć.mówcy i Przynależność.mówcy może pokazać, jak często kobiety, jako przedstawicielki określonych ugrupowań, zabierają głos w ich imieniu lub na wybrany temat.


