
Wprowadzenie
W poprzedniej lekcji poznaliśmy Korpus Dyskursu Parlamentarnego. Wygenerowaliśmy konkordancję dla form podstawowych słów digitalizacja i digitalizować, a następnie przygotowaliśmy w Posit.cloud wykres ilustrujący liczbę wystąpień na temat digitalizacji w latach 1996-2023. Pracowaliśmy z bibliotekami R do budowania wykresów zgodnie z założeniami Grammar of Graphics: ggplot2 i plotly, a nasze dane zaimportowane z korpusu przyjęły postać ramki danych (data frame).
Pora na bardziej zaawansowaną pracę z taką postacią danych. Spróbujmy je przetworzyć tak, aby wygenerować kolejne dane do wizualizacji.
Cele lekcji
Celem lekcji jest dalsze poznawanie metod pracy z ramkami danych w R oraz wprowadzenie do korzystania z metod pakietu tm do przetwarzania tekstów i pakietu wordcloud do generowania chmur słów kluczowych. Źródłem naszych danych będzie ramka danych wygenerowana z Korpusu Dyskursu Parlamentarnego.
Efekty
Efektem naszej pracy będą przetworzone dane korpusowe i ich wizualizacje w postaci chmury słów kluczowych.
Wymagania
Do skorzystania z lekcji konieczne jest darmowe konto w Posit.cloud, umiejętność korzystania z tej aplikacji, znajomość podstaw składni języka R (omawialiśmy już ją na tej stronie) oraz lektura poprzedniej lekcji.
Część merytoryczna
Nasze już nieco bardziej zaawansowane ćwiczenia z danymi z Korpusu Dyskursu Parlamentarnego, dostępnymi w postaci ramki danych, zacznijmy od przygotowania chmury słów kluczowych. Musimy oczywiście zaimportować plik CSV oraz uporządkować kolumny - robiliśmy to już w poprzedniej lekcji. W ramce danych znajdziemy kolumnę lematNadrzednika, która pokazuje najbliższy kontekst słowa digitalizacja i digitalizować:
paste0(c$lematNadrzednika, c$rezultat)[1:10]
# [1] "i digitalizacji" "i digitalizacji" "na digitalizację"
# [4] "infrastruktura digitalizacji" "służyć digitalizacji" "stan digitalizacji"
# [7] "na digitalizację" "efekt digitalizuje" "wykorzystywać digitalizację"
# [10] "sprawa digitalizacji" Funkcja paste0 połączyła nam ze sobą dwie kolumny, a indeks [1:10] pokazał pierwszych dziesięć wyników. Przynajmniej część słów z kolumny lematNadrzednika może pomóc nam w interpretacji danych. Aby ułatwić sobie tę interpretację, użyjmy chmury słów kluczowych.
Chmura słów kluczowych: dane
Chmura słów kluczowych (chmura tagów) to wizualna reprezentacja najczęściej występujących słów lub fraz w danym tekście, dokumencie lub zbiorze danych. W tej wizualizacji słowa są wyświetlane w różnych rozmiarach - wielkość każdego słowa jest proporcjonalna do jego częstotliwości występowania.
Chmury słów kluczowych są używane w analizie tekstu do szybkiego zidentyfikowania głównych tematów i trendów, ułatwiając zrozumienie treści oraz wyodrębnienie istotnych informacji w dużych zbiorach danych. Chmury słów - jak każda wizualizacja - nie są oczywiście neutralną formą prezentacji danych - więcej na ten temat dowiedzieliśmy się w jednej z poprzednich lekcji.
Chmury słów kluczowych w R buduje się głównie na podstawie macierzy częstotliwości słowo-dokument (Document-Term Matrix, DTM), jednak ten format danych językowych poznamy podczas innej lekcji. Spróbujmy przygotować chmurę słów na podstawie danych, które możemy uzyskać w prosty sposób dzięki funkcji table - poda nam ona liczbę wystąpień każdej wartości z kolumny lematNadrzednika:
table(c$lematNadrzednika)[120:130]
# postępować postulat poświecić poświęcić potrwać potrzeba potrzebować powiedzieć powinien powód
# 1 1 1 1 1 4 1 1 2 2
# powodować
# 1 Zamiana tabeli do ramki danych i zmiana nazw kolumn sprawi, że dane będą czytelniejsze:
wrdcld_data <- as.data.frame(table(c$lematNadrzednika), stringsAsFactors = FALSE)
names(wrdcld_data)
# [1] "Var1" "Freq"
names(wrdcld_data) <- c("lemma", "freq")
head(wrdcld_data)
# lemma freq
#1 - 3
#2 – 4
#3 , 100
#4 ; 4
#5 : 1
#6 ? 1
tail(wrdcld_data)
# lemma freq
#248 złoty 1
#249 zmniejszyć 1
#250 znaczenie 1
#251 zostać 4
#252 zrobić 4
#253 zwać 1W powyższym kodzie użyliśmy funkcji tail, która pozwala podejrzeć ostatnie wiersze ramki danych (podobnie funkcja head pokazuje pierwsze wiersze).
Poruszanie się po ramce danych
Jak poruszać się po ramce danych i wyświetlać / zwracać wartości z wybranej komórki?
# wyświetlenie całej kolumny lemma - sposób I
wrdcld_data$lemma
# wyświetlenie całej kolumny lemma - sposób II
wrdcld_data[,1]
# wyświetlenie wybranych 10 wierszy kolumny lemma - sposób I:
wrdcld_data$lemma[20:29]
# wyświetlenie wybranych 10 wierszy kolumny lemma - sposób II:
wrdcld_data[20:29,1]
# wyświetlenie wybranych 10 wierszy wszystkich kolumn:
wrdcld_data[20:29,]
# sprawdzenie, czy rzeczywiście wyświetliliśmy 10 wierszy:
nrow(wrdcld_data[20:29,])
# [1] 10W języku R indeksy są kluczowym narzędziem do nawigowania i manipulowania ramkami danych. Pierwszy sposób, wrdcld_data$lemma, wykorzystuje nazwę kolumny do bezpośredniego uzyskania dostępu do jej zawartości. To prosta i czytelna metoda wybierania danych z data frame. Drugi sposób, wrdcld_data[,1], wykorzystuje pozycję kolumny w ramce danych (kolumna lemma jest pierwsza). Taka matoda wybierania danych może być wykorzystana, kiedy nie znamy nazw kolumn.
Aby nauczyć się, jak poprawnie tworzyć indeksy, warto zapamiętać schemat:
dane[WIERSZE,KOLUMNY]Aby wyświetlić wybrane wiersze kolumny lemma, możemy użyć indeksowania przy użyciu zakresu, jak w wrdcld_data$lemma[20:29] lub też wskazując pozycję kolumny: wrdcld_data[20:29,1]. Sprawdzenie liczby wierszy wyświetlonych w tym zakresie za pomocą nrow(wrdcld_data[20:29,1]) potwierdza, że faktycznie otrzymujemy 10 wierszy (wiersz numer 20, wiersz numer 21 itp.).
Jeśli w indeksie nie podamy pozycji wierszy lub kolumn, zwrócimy wszystkie wiersze / kolumny:
# otrzymamy określony zakres wierszy ze wszystkich kolumn
dane[WIERSZE,]
# otrzymamy wszystkie wiersze z wskazanych kolumn
dane[,KOLUMNY]Chmura słów kluczowych: stopwords
W naszej tabeli znajduje się wiele tzw. stopwords, które podważają sens budowania chmury słów kluczowych - po co komu wiedza, że znaki interpunkcyjne czy spójniki występują najczęściej w naszych danych? Usuńmy te niepotrzebne elementy - oczywiście, nie zrobimy tego ręcznie.
Skorzystajmy z metod, jakie daje popularna biblioteka tm (text mining). Naszym zdaniem będzie 1) usunięcie stopwords, 2) usunięcie interpunkcji oraz 3) wyrzucenie wszystkich pustych elementów.
Zacznijmy od zainstalowania i wczytania niezbędnych bibliotek:
install.packages("tm")
library(tm)
install.packages("stopwords")
library(stopwords)Nadpiszmy wrdcld_data - poprzednia ramka danych nie będzie nam potrzebna:
wrdcld_data <- c$lematNadrzednikawrdcld_data to kolumna w ramce danych, a więc wieloelementowy wektor (obiekt). Na razie nie będziemy liczyć częstości występowania słów, zajmiemy się raczej usunięciem tych niepotrzebnych.
Przed wyrzuceniem stopwords nasze dane wyglądają tak:
wrdcld_data
# [1] "i" "i" "na" "infrastruktura" "służyć" "stan"
# [7] "na" "efekt" "wykorzystywać" "sprawa" "," "zdjęcie"
# [13] "o" "kwestia" "zdjęcie" "na" "to" "zakres"
# [19] "że" "że" "," "," "," "uruchomić"
# [25] "proces" "konieczność" "być" "projekt" "do" "i" W bibliotece tm dostępna jest metoda removeWords, której argumentem jest lista stopwords. Biblioteka stopwords udostępnia nam łatwy sposób pobrania i przetworzenia listy polskich stopwords za pomocą metody stopwords. Podajemy jej kod języka (pl) oraz źródło danych (stopwords-iso) - wszystko na ten temat możemy wyczytać w dokumentacji pakietu.
wrdcld_data <- removeWords(wrdcld_data, stopwords("pl", "stopwords-iso"))W efekcie:
wrdcld_data
# [1] "" "" "" "infrastruktura" "służyć" "stan"
# [7] "" "efekt" "wykorzystywać" "sprawa" "," "zdjęcie"
# [13] "" "kwestia" "zdjęcie" "" "" "zakres"
# [19] "" "" "," "," "," "uruchomić"
# [25] "proces" "konieczność" "" "projekt" "" "" Udało się. Kolejnym problemem są znaki interpunkcyjne - je też możemy usunąć z wykorzystaniem metod tm:
wrdcld_data <-removePunctuation(wrdcld_data)W naszych danych nie będzie już znaków interpunkcyjnych. Pozostaje wyrzucenie pustych wpisów z naszego wektora. Aby to zrobić, korzystamy z indeksu:
wrdcld_data <- wrdcld_data[nchar(wrdcld_data) > 0]Oto jak działa ten kod:
- nchar(wrdcld_data): funkcja nchar() zwraca liczbę znaków w każdym elemencie wektora wrdcld_data. Jeśli wrdcld_data zawiera ciągi znaków, nchar() zwróci informację wektor liczb całkowitych, gdzie każda liczba reprezentuje długość odpowiadającego jej ciągu znaków,
- nchar(wrdcld_data) > 0: to wyrażenie logiczne sprawdza, czy liczba znaków w każdym elemencie wrdcld_data jest większa od zera. Wynikiem jest wektor wartości logicznych (TRUE lub FALSE), gdzie TRUE oznacza, że dany element ma więcej niż zero znaków.
- wrdcld_data[nchar(wrdcld_data) > 0]: to jest właściwe filtrowanie. Wektor wrdcld_data jest filtrowany za pomocą wektora logicznego uzyskanego w poprzednim kroku. Oznacza to, że wrdcld_data zostanie nadpisany i znajdą się w nim tylko te elementy, które mają więcej niż zero znaków.
W efekcie:
wrdcld_data
# [1] "infrastruktura" "służyć" "stan" "efekt" "wykorzystywać" "sprawa" "zdjęcie"
# [8] "kwestia" "zdjęcie" "zakres" "uruchomić" "proces" "konieczność" "projekt"
# [15] "kwestia" "przebiegać" "zagadnienie" "akcja" "sfera" "sprawa" "chcieć"
# [22] "sfera" "program" "kwestia" "etap" "kierunek" "zasadzać" "inicjatywa"
# [29] "możliwość" "wykonywać" "poprzez" "mieć" "wyzwanie" "kryć" "rozumienie" Chmura słów kluczowych: ustawienia
Mamy przygotowane dane źródłowe, czas policzyć wystąpienia poszczególnych słów. Znowu korzystamy z funkcji table do policzenia częstości oraz funkcji as.data.frame do przetworzenia tabeli na ramkę danych:
wrdcld_data <- as.data.frame(table(wrdcld_data), stringsAsFactors = FALSE)
names(wrdcld_data) <- c("lemma", "freq")Zmieniliśmy też nazwy kolumn, żeby łatwiej było się nimi posługiwać przy generowaniu chmury słów. Stworzymy ją przy pomocy funkcji wordcloud:
# instalujemy bibliotekę i wczytujemy do środowiska
install.packages("wordcloud")
library(wordcloud)
# budujemy chmurę słów
wordcloud(wrdcld_data$lemma, wrdcld_data$freq)Kluczowe jest podanie do tej funkcji dwóch rodzajów danych: słów kluczowych (wrdcld_data$lemma) oraz ich częstości (wrdcld_data$freq):

Rzut oka na wygenerowaną chmurę słów potwierdzi nasze przypuszczenia, że temat digitalizacji był poruszany w parlamencie przede wszystkim w kontekście rozmaitych regulacji, planowania polityk państwa w tym zakresie itp. Proste statystyki częstości słów pokazują, jak wyraźnie wyróżnia się na ich tle słowo proces:
mean(wrdcld_data$freq)
# [1] 3.701422
median(wrdcld_data$freq)
# [1] 2
max(wrdcld_data$freq)
# [1] 97Jak to jest, że pomimo tak radykalnych różnic częstości między najczęstszym słowem a większością, nasza chmura słów nie jest zdominowana przez słowo proces? Funkcja wordcloud przyjmuje też ustawienia skali, które są wynikiem działania funkcji scale. Standardowa skala to scale = c(4, 0.5), co ustawia maksymalny rozmiar czcionki na 4, a minimalny na 0.5. Gdybyśmy spróbowali oddać częstość słów 1:1 (najczęstsze słowo o wielkości 97, minimalny rozmiar jako 1)
wordcloud(wrdcld_data$lemma, log1p(wrdcld_data$freq), scale=c(97,1))otrzymalibyśmy błąd
In wordcloud(wrdcld_data$lemma, log1p(wrdcld_data$freq), scale = c(97, : system could not be fit on page. It will not be plottedTo świetny przykład tego, że chmura słów kluczowych jest interpretacją danych.
Spróbujmy jeszcze użyć opcji filtrowania słów ze względu na ich częstość. Za pomocą parametru min.freq ustawiamy minimalną częstość występowania słowa (standardowo to minimalnie 3 wystąpienia). Gdybyśmy chcieli pokazać wszystkie słowa (także te, które pojawiają się tylko raz), moglibyśmy użyć kodu:
wordcloud(wrdcld_data$lemma, wrdcld_data$freq, min.freq = 1)
Można dyskutować, czy taka postać chmury słów jest w stanie powiedzieć nam cokolwiek o analizowanych treściach. Pamiętajmy, że mediana częstości naszego zbioru słów wynosi 2, więc ograniczenie wyświetlania słów wyłącznie do tych, które występują minimalnie 3 razy wydaje się zasadna, jeśli nasza wizualizacja miałaby pomijać wyjątkowe, specjalistyczne czy też przypadkowe słowa.
quantile(wrdcld_data$freq)
# 0% 25% 50% 75% 100%
# 1 1 2 4 97 Trzeci kwantyl to taka wartość, poniżej której znajduje się 75 proc. danych. Wykorzystajmy go wygenerowania chmury słów kluczowych, która zawierać będzie najczęściej pojawiające się słowa:
wordcloud(wrdcld_data$lemma, wrdcld_data$freq, min.freq = 4)
A gdyby tak wyświetlić tylko dziesięć najczęstszych słów? Aby to zrobić, musimy posortować naszą źródłową ramkę danych po wartościach z kolumny freq:
wrdcld_data <- wrdcld_data[order(-wrdcld_data$freq), ]Pozostaje tylko użyć funkcji wordcloud ze wskazaniem wyłącznie 10 pierwszych wierszy z każdej kolumny:
wordcloud(wrdcld_data$lemma[1:10], wrdcld_data$freq[1:10])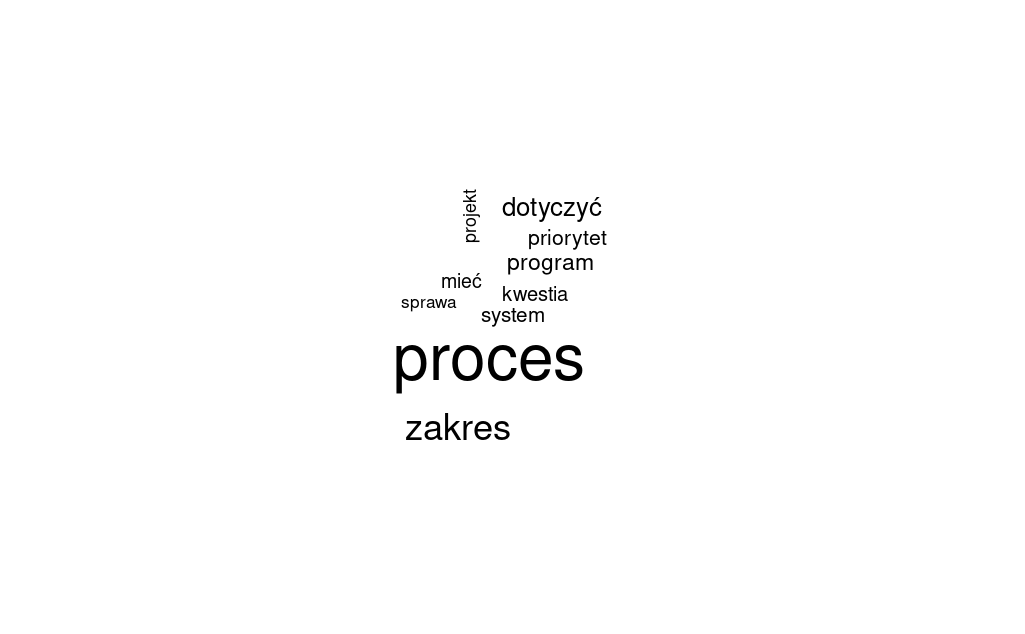
Chmura słów kluczowych: kolory
Dzięki instalowanej wraz z wordcloud bibliotece RColorBrewer możemy do naszej chmury słów dodać kolory:
wordcloud(wrdcld_data$lemma, wrdcld_data$freq, colors=brewer.pal(8, "Dark2"))
Kolory generujemy za pomocą funkcji brewer.pal, której możemy podać liczbę kolorów oraz nazwę palety:
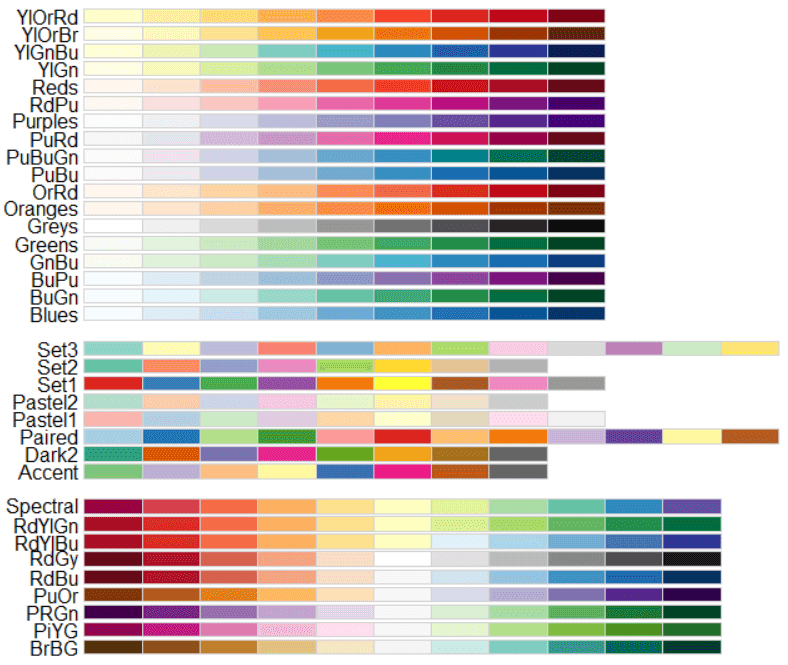
W dokumentacji biblioteki wyczytamy, że dostępne są trzy rodzaje palet:
- palety sekwencyjne - odpowiednie do uporządkowanych danych, które rozwijają się od niskich do wysokich wartości. Tutaj dominującym elementem schematu kolorystycznego jest zmiana jasności - z jasnymi kolorami dla niskich wartości danych i ciemnymi kolorami dla wysokich wartości,
- palety jakościowe - służą do podkreślania różnic między kategoriami (klasami), najlepiej nadają się do reprezentowania danych kategorycznych / jakościowych,
- palety rozbieżne podkreślają średnie, krytyczne wartości oraz ujawniają skrajności na obu końcach zakresu danych. Wartości średnie są podkreślone jasnymi kolorami, a skrajne niskie i wysokie - ciemnymi z kontrastującymi odcieniami.
Warto zwrócić uwagę nie tylko na to, jakie znaczenie może mieć kolor w wizualizacji danych, ale też jakie znaczenie może mieć układ palety kolorów.
Podsumowanie
Chmura słów kluczowych może być ciekawym dodatkiem do artykułu, raportu albo katalogu. Przygotowując ją warto pamiętać o tym, że - jak każda wizualizacja - jest także interpretacją danych. Przygotowanie jej wymaga też odpowiednio przepracowanych danych - korzystamy wyłącznie z form podstawowych oraz usuwamy znaki intepunkcyjne - wszystkie te zadania możemy wykonać bezpośrednio w R. Generując kolorowe chmury słów, zwróćmy uwagę na znaczenie rodzajów palet (sekwencyjnych, rozbieżnych i jakościowych).
Wykorzystanie metod
O korzystaniu z chmur słów jako metodzie wizualizacji przeczytaj na tej stronie.
Pomysł na warsztat
Lekcja jest częścią warsztatu wprowadzającego do R.
Poza tym kontekstem można przygotować warsztat z budowania chmur słów kluczowych z wykorzystaniem drukowanej prasy (różne wielkości i kolory liter nagłówków) oraz krótkich tekstów źródłowych (np. tekstów piosenek albo zbioru tweetów). Uczestnicy i uczestniczki warsztatu mogą zastanowić się, co pokazuje, a co ukrywa chmura słów i czy są takie rodzaje treści, które trudno byłoby opisać za pomocą takiej wizualizacji


