
Wprowadzenie
W ramach lekcji będziemy ćwiczyć pracę z ChatGPT przy opracowywaniu opisów obiektów z wybranych muzeów i galerii cyfrowych. ChatGPT pozwala bardzo szybko przetworzyć schematyczny opis metadanych w podstawy interesującej narracji. Lekcja może być wzorem zajęć warsztatowych, w ramach których wykorzystuje się nowe narzędzia AI do pracy i zabawy ze zbiorami kultury i dziedzictwa online.
W ramach tej lekcji korzystać będziemy z zasobów cyfrowych udostępnianych przez Muzeum Narodowe we Wrocławiu.
Alternatywnie wobec ChatGPT wykorzystać można chat dostępny w wyszukiwarce Ecosia, przy czym ma on pewne ograniczenia co do długości konwersacji, co może przeszkadzać w efektywnej pracy.
Cele lekcji
Celem lekcji jest:
- wprowadzenie do przetwarzania treści z wykorzystaniem ChatGPT (czyszczenie danych, przetwarzanie do tabeli, parafrazowanie, tworzenie list itp.),
- ukazanie problemu twórczości i praw autorskich w kontekście treści generowanych przez narzędzia AI na podstawie autorskich opracowań.
Efekty
- zdobycie umiejętności podstawowej pracy z przetwarzaniem tekstu z wykorzystaniem ChatGPT lub podobnych narzędzi,
- zdobycie podstawowej wiedzy o metadanych i ich roli w opisach zbiorów cyfrowych,
- zwrócenie uwagi na wyzwania prawnoautorskie związane z opisywaniem zbiorów cyfrowych oraz generowaniem treści na podstawie autorskich materiałów.
Wymagania
Konieczny jest dostęp do ChatGPT (co wymaga utworzenia konta po podaniu numeru telefonu) lub podobnego czatu dostępnego na stronie wyszukiwarki Ecosia (bez konieczności logowania) lub w innych podobnych serwisach. Polecenia i efekty tych poleceń, opisane w treści lekcji, pochodzą z ChatGPT.
Część merytoryczna
W 2023 roku Muzeum Narodowe we Wrocławiu uruchomiło nową witrynę, na której mamy dostęp do prawie 10 tys. zdigitalizowanych zabytków. W zbiorach muzeum, teraz dostępnych już online, znajduje się niesamowity obiekt - kolorowy drzeworyt z XVIII/XIX wieku, przedstawiający aktora teatru kabuki. Kabuki to jeden z nurtów tradycyjnego teatru japońskiego.
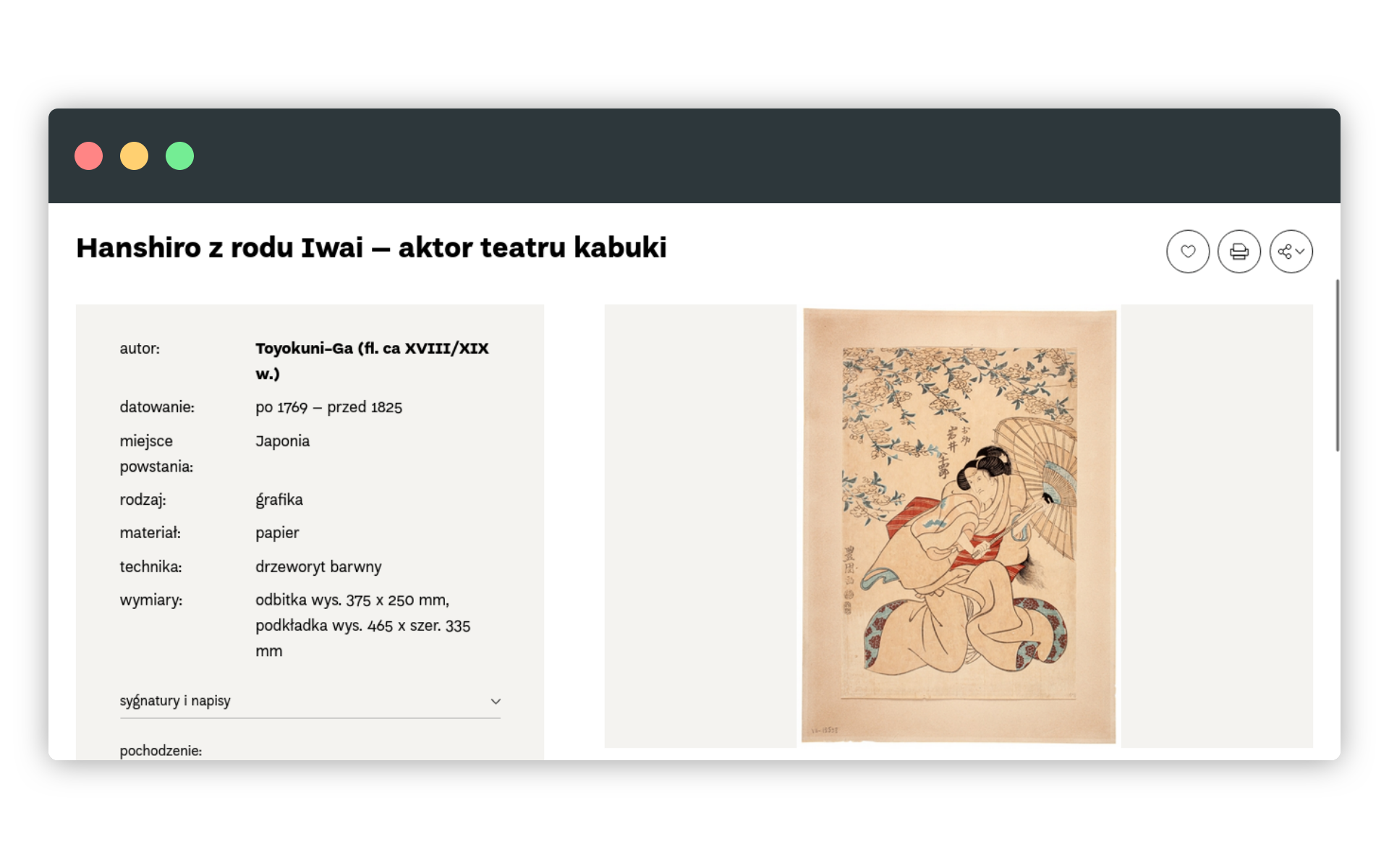
Pobieramy metadane obiektu
W lewej części strony tego obiektu znajdują się metadane. Metadane to nic innego jak uporządkowane i tworzące pewną strukturę informacje (dane) o obiekcie cyfrowym. Kształt metadanych może być różny w różnych projektach opisywania i publikowania zbiorów, istnieją też jednak szeroko stosowane standardy metadanych takie jak MARC21, wykorzystywany przede wszystkim w bibliotekach, Dublin Core - obecny m.in. w polskich bibliotekach cyfrowych czy choćby ISAD(G), używany w archiwach państwowych oraz w Centrum Archiwistyki Społecznej do opisywania gromadzonych oddolnie zbiorów.
W kontekście tej lekcji nie ma znaczenia, jaki standard metadanych stosuje Muzeum Narodowe we Wrocławiu. Istotne jest dla nas to, że metadane te są wyróżnione na stronie i dostępne do ściągnięcia metodą kopiuj-wklej. Wadą ChatGPT (przynajmniej w darmowej wersji) jest brak możliwości kierowania go na dowolną stronę internetową z poleceniem pobrania jakiejś treści. To zadanie musimy wykonać sami.
Wchodzimy więc na stronę interesującego nas obiektu, zaznaczamy i kopiujemy treści z pola metadanych. Możemy wkleić je do notatnika, aby usunąć niepotrzebne formatowanie, ale nie wydaje się to konieczne, skoro w ChatGTP polecenia wpisujemy w plain text (tekście pozbawionym formatowania). Skopiowany tekst wygląda tak:
Toyokuni-Ga (fl. ca XVIII/XIX w.) datowanie: po 1769 – przed 1825 miejsce powstania: Japonia rodzaj: grafika materiał: papier technika: drzeworyt barwny wymiary: odbitka wys. 375 x 250 mm, podkładka wys. 465 x szer. 335 mm sygnatura: Po lewej stronie, obok postaci kobiety sygnatura w alfabecie japońskim: "Toyokuni ga" napis: Powyżej postaci podzielony na trzy kolumny napis w alfabecie japońskim: Toyokuni-Ga pochodzenie: 1969, zakup Muzeum Narodowe we Wrocławiu Dział Grafiki XVI–XIX w. numer inwentarza: MNWr VII-12538Tekst do tabeli w ChatGPT
Do strony obiektu w repozytorium MNWr jeszcze wrócimy. Teraz przejdźmy do ChatGPT. Nasze metadane są teraz zupełnie nieczytelne - w skopiowanej wersji nie udało się nam przecież zachować formatowania tabelki (takiej, jaka jest dostępna na oryginalnej stronie). Pora to naprawić. Oto przykładowy prompt, który zamieni tę pozornie nieuporządkowaną treść na czytelną tabelę w interfejsie ChatGPT:
zamień tę treść na tabelę z kolumnami pole i wartość: autor: Toyokuni-Ga (fl. ca XVIII/XIX w.) datowanie: po 1769 – przed 1825 miejsce powstania: Japonia rodzaj: grafika materiał: papier technika: drzeworyt barwny wymiary: odbitka wys. 375 x 250 mm, podkładka wys. 465 x szer. 335 mm sygnatura: Po lewej stronie, obok postaci kobiety sygnatura w alfabecie japońskim: "Toyokuni ga" napis: Powyżej postaci podzielony na trzy kolumny napis w alfabecie japońskim: Toyokuni-Ga pochodzenie: 1969, zakup Muzeum Narodowe we Wrocławiu Dział Grafiki XVI–XIX w. numer inwentarza: MNWr VII-12538W efekcie powinniśmy otrzymać tabelę:
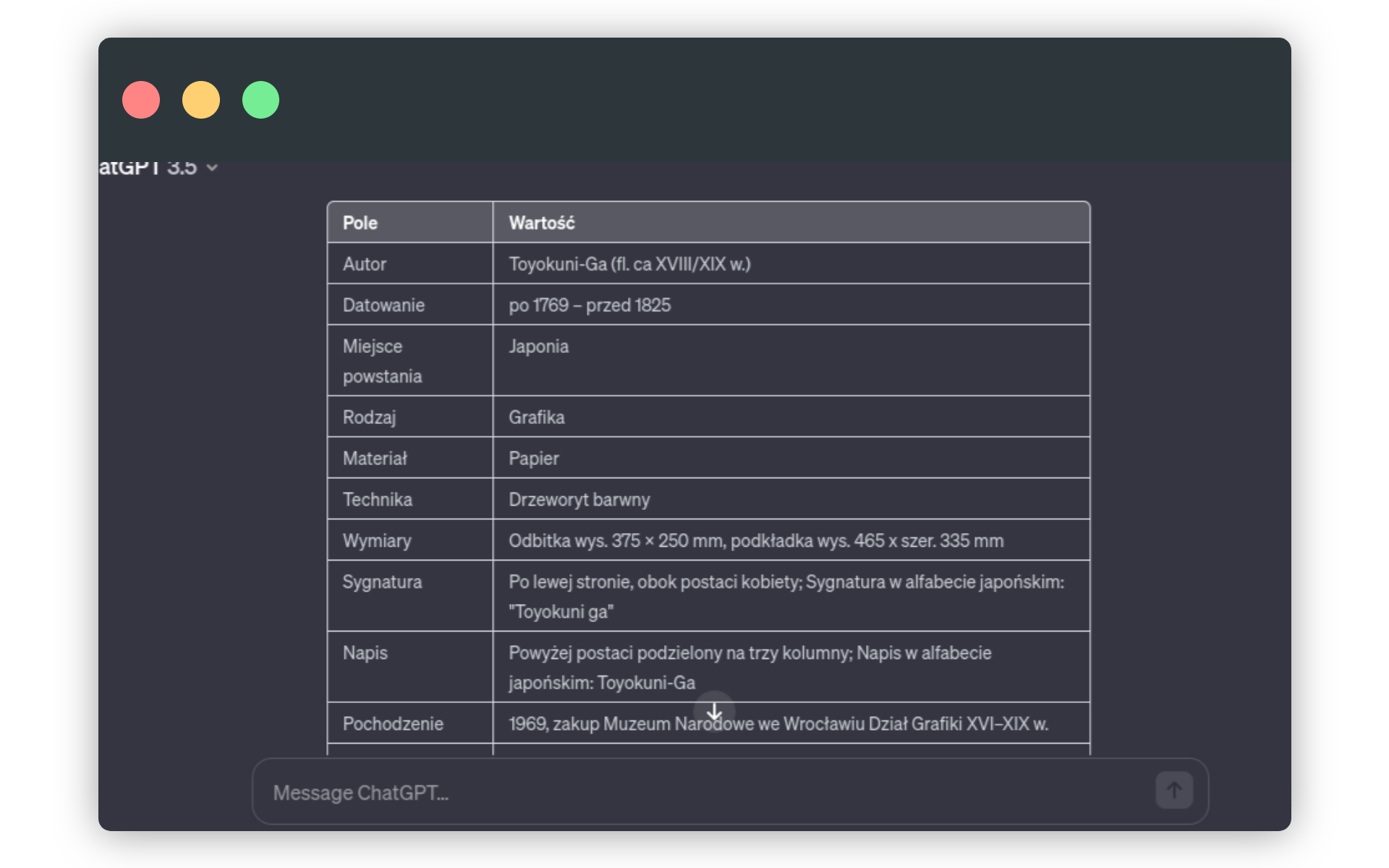
Warto zwrócić uwagę, że w poleceniu tworzącym tabelę od razu nadaliśmy nazwy poszczególnym kolumnom. To ważne, bo w dalszej części ćwiczenia będziemy się do tych kolumn odwoływać.
To też dobry moment na porównanie wartości metadanych wyświetlonych w tabeli z wartościami podanymi na oryginalnej stronie MNWr. Starajmy się zawsze podejrzliwie podchodzić do efektów pracy ChatGPT. W naszym przykładzie okazało się, że w wierszu Pochodzenie znalazły się treści, których tam oryginalnie nie było (Muzeum Narodowe we Wrocławiu Dział Grafiki XVI–XIX w.). To efekt pewnej niekonsekwencji w zapisie nagłówków metadanych i ich wartości na stronie obiektu - w każdym przypadku oddziela je dwukropek, ale nie jest tak przy nagłówku Muzeum Narodowe we Wrocławiu. Nie jest to jednak duży problem wobec naszych planów dla tej tabelki.
Zdania na podstawie metadanych
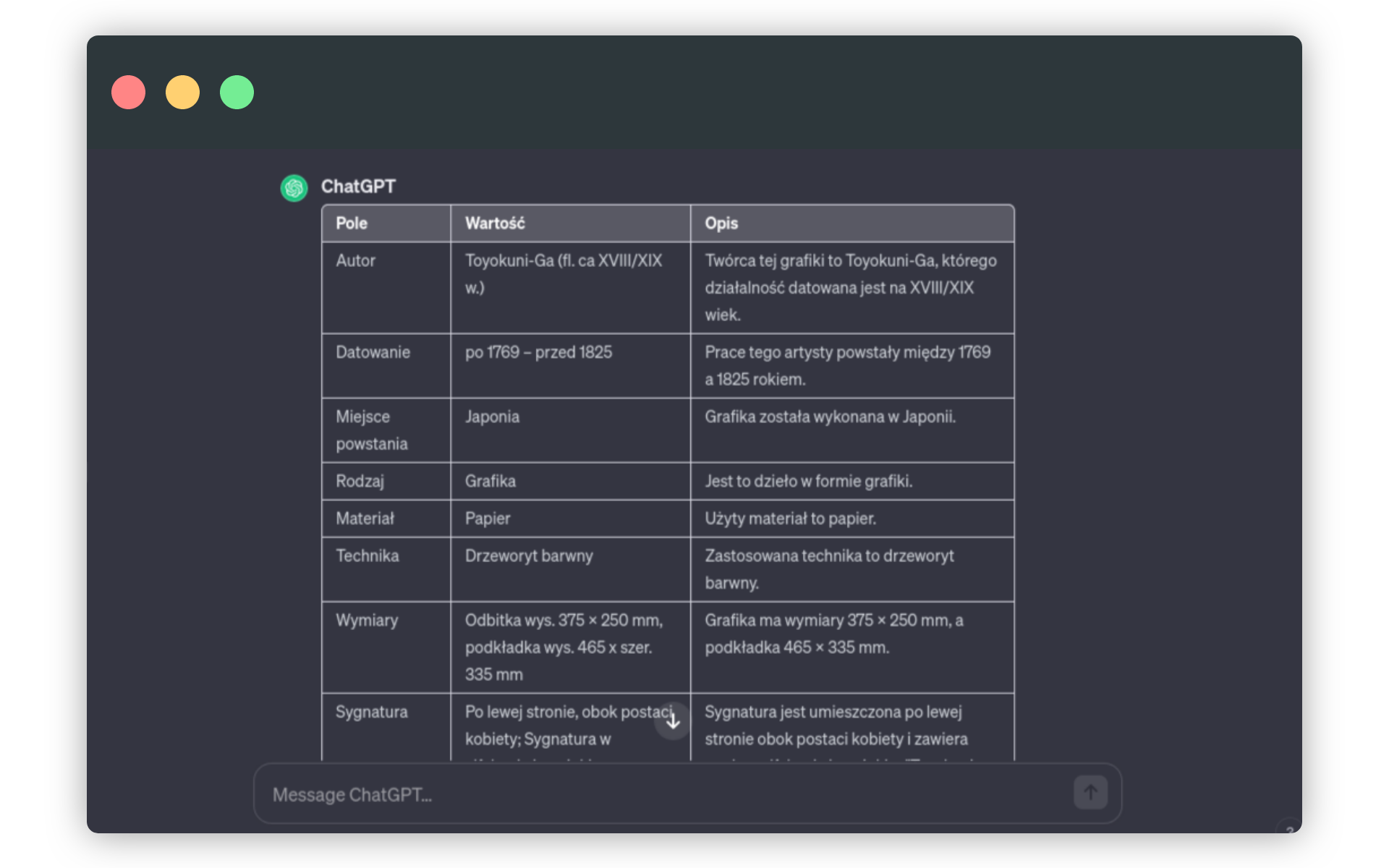
Spróbujmy wykorzystać teraz kreatywną stronę ChatGPT. Poniższy prompt powinien do naszej tabeli dodać nową kolumnę o nazwie opis, w której znajdzie się prosta narracja bazująca na wartości metadanych. Można powiedzieć, że przetwarzamy pojęcia i słowa kluczowe na pełne zdania:
dodaj kolumnę opis, w której włóż 1-3 zdania zbudowane na podstawie treści kolumny wartośćChatGPT poradził sobie z tym zadaniem.
Przenieśmy teraz wszystkie opisy do jednego akapitu za pomocą promptu:
wartości kolumny Opis przerzuć do jednego akapituW efekcie uzyskamy tekst opisu, niestety z niepotrzebnymi powtórzeniami i w koślawym stylu:
Autor tej grafiki to Toyokuni-Ga, którego działalność datowana jest na XVIII/XIX wiek. Prace tego artysty powstały między 1769 a 1825 rokiem. Grafika została wykonana w Japonii i jest dziełem w formie grafiki, wykonanym na papierze techniką drzeworytu barwnego. Ma wymiary 375 x 250 mm, a podkładka 465 x 335 mm. Sygnatura jest umieszczona po lewej stronie obok postaci kobiety i zawiera napis w alfabecie japońskim "Toyokuni ga". Ponad postacią widnieje napis podzielony na trzy kolumny, zawierający imię artysty w alfabecie japońskim "Toyokuni-Ga". Grafika została nabyta przez Muzeum Narodowe we Wrocławiu w 1969 roku i znajduje się w Dziale Grafiki XVI–XIX wieku. Jest zarejestrowana pod numerem inwentarzowym MNWr VII-12538.Polecenie
popraw styl tego tekstu i usuń powtórzenia, zachowując wszystkie informacjeuporządkuje tekst, ale wytnie drobne informacje (takie jak np. to, że napis umieszczony powyżej postaci podzielony jest na trzy kolumny):
Grafika została stworzona przez Toyokuni-Ga, znanego z działalności w XVIII/XIX wieku. Powstała między 1769 a 1825 rokiem w Japonii jako drzeworyt barwny na papierze. Ma wymiary 375 x 250 mm (odbitka) i 465 x 335 mm (podkładka). Sygnatura w alfabecie japońskim "Toyokuni ga" umieszczona jest obok postaci kobiety. Ponad postacią widnieje napis "Toyokuni-Ga". Praca została nabyta przez Muzeum Narodowe we Wrocławiu w 1969 roku i jest częścią Działu Grafiki XVI–XIX wieku, zarejestrowana pod numerem inwentarzowym MNWr VII-12538.Remiks opisu merytorycznego
Zostawmy jednak te szczegóły i skorzystajmy z oryginalnego opisu merytorycznego, który przygotowały Dorota Róż-Mielecka i Aurelia Zduńczyk. O ile metadane możemy uznać za treści, które nie są objęte ochroną prawa autorskiego (trudno przecież drzeworyt opisać inaczej niż drzeworyt i nie ma w tym autorskiej inwencji), to opis autorek z MNWr taką ochroną jest już objęty. Warto zwracać uwagę na kwestie praw autorskich podczas pracy z narzędziami AI i dbać o odpowiednią atrybucję oraz poszanowanie integralności oryginalnych treści, z których korzystamy.
Kolejny prompt doda sparafrazowany opis obiektu do wygenerowanej już przez nas na bazie metadanych treści:
do tekstu "Grafika została stworzona przez Toyokuni-Ga, znanego z działalności w XVIII/XIX wieku. Powstała między 1769 a 1825 rokiem w Japonii jako drzeworyt barwny na papierze. Ma wymiary 375 x 250 mm (odbitka) i 465 x 335 mm (podkładka). Sygnatura w alfabecie japońskim "Toyokuni ga" umieszczona jest obok postaci kobiety. Ponad postacią widnieje napis "Toyokuni-Ga". Praca została nabyta przez Muzeum Narodowe we Wrocławiu w 1969 roku i jest częścią Działu Grafiki XVI–XIX wieku, zarejestrowana pod numerem inwentarzowym MNWr VII-12538." dodaj sparafrazowany tekst: "Jeden z drzeworytów ukiyo-e, czyli "obrazów przepływającego świata" czy też "obrazów przemijającego świata" przedstawia aktora teatru kabuki Hanshiro z rodu Iwai. Głowę mężczyzny odgrywającego postać kobiecą zdobi czarna peruka (katsura) i fioletowa czapeczka przekrywająca wygolone miejsce nad czołem (yaro-boshi)."Praca z ChatGPT nie zawsze jest prosta i musiałem potestować wiele promptów, aby uzyskać odpowiedni efekt. Być może w Waszym przypadku także będzie to konieczne. Najbardziej efektywnym rozwiązaniem okazało się podanie wprost, do jakiego tekstu ma zostać dołączony sparafrazowany merytoryczny opis obu autorek. Tak brzmi ostateczny efekt połączenia:
Grafika została stworzona przez Toyokuni-Ga, znanego z działalności w XVIII/XIX wieku, jako jedno z drzeworytów ukiyo-e, zwanych również "obrazami przepływającego świata" czy "obrazami przemijającego świata". Przedstawia aktora teatru kabuki Hanshiro z rodu Iwai. Głowę mężczyzny odgrywającego postać kobiecą zdobi czarna peruka (katsura) i fioletowa czapeczka przekrywająca wygolone miejsce nad czołem (yaro-boshi). Powstała między 1769 a 1825 rokiem w Japonii jako drzeworyt barwny na papierze o wymiarach 375 x 250 mm (odbitka) i 465 x 335 mm (podkładka). Sygnatura w alfabecie japońskim "Toyokuni ga" umieszczona jest obok postaci kobiety, a ponad postacią widnieje napis "Toyokuni-Ga". Praca została nabyta przez Muzeum Narodowe we Wrocławiu w 1969 roku i jest częścią Działu Grafiki XVI–XIX wieku, zarejestrowana pod numerem inwentarzowym MNWr VII-12538.Jest dobrze. Z takim materiałem możemy się już bardziej otworzyć na kreatywność i zabawę (nie prowadzimy przecież badania naukowego). Spróbujmy poeksperymentować z formą opisu, akceptując przy tym drobne wady stylistyczne i gramatyczne tekstu, który wygenerował dla nas ChatGPT. Dla bezpieczeństwa skopiowałem sobie wygenerowany tekst, żeby w razie potrzeby móc do niego wrócić.
Generowanie opisów i narracji w wielu stylach
Testując możliwości i kreatywność ChatGTP wygenerowałem opisy w postaci m.in.:
- dialogu między przewodnikiem a zwiedzającymi (który zachował logikę opisu i wszystkie fakty, ale brzmiał jak fragment przypowieści biblijnej albo powieści socrealistycznej),
- listę 10 faktów o obiekcie,
- komunikat prasowy o możliwości obejrzenia cyfrowej reprodukcji tego drzeworytu,
- listę 5 zagadek na temat drzeworytu (materiał wygenerowany przez ChatGPT był tutaj zupełnie nieudany),
- scenę w opowiadaniu, którego akcja dzieje się w Japonii w XVIII wieku (“Scena kończy się uśmiechem rodziny, która podziwia nowy nabytek i cieszy się jego obecnością w swoim domu”).
Ostateczny efekt kreatywnej pracy z ChatGPT wynika nie tylko z ograniczeń tego modelu, ale też szczegółowości promptu. W tym ćwiczeniu ChatGPT pozwolił jednak na bardzo szybkie generowanie podstawowych wersji różnych form opisywania obiektu, które w razie potrzeby dałoby się poprawić i uzupełnić ręcznie.
Na koniec tego ćwiczenia spróbujmy wykorzystać ChatGPT do przygotowania pewnej chronologii tego dzieła:
weź tekst "Grafika została stworzona przez Toyokuni-Ga, znanego z działalności w XVIII/XIX wieku, jako jedno z drzeworytów ukiyo-e, zwanych również "obrazami przepływającego świata" czy "obrazami przemijającego świata". Przedstawia aktora teatru kabuki Hanshiro z rodu Iwai. Głowę mężczyzny odgrywającego postać kobiecą zdobi czarna peruka (katsura) i fioletowa czapeczka przekrywająca wygolone miejsce nad czołem (yaro-boshi). Powstała między 1769 a 1825 rokiem w Japonii jako drzeworyt barwny na papierze o wymiarach 375 x 250 mm (odbitka) i 465 x 335 mm (podkładka). Sygnatura w alfabecie japońskim "Toyokuni ga" umieszczona jest obok postaci kobiety, a ponad postacią widnieje napis "Toyokuni-Ga". Praca została nabyta przez Muzeum Narodowe we Wrocławiu w 1969 roku i jest częścią Działu Grafiki XVI–XIX wieku, zarejestrowana pod numerem inwentarzowym MNWr VII-12538." i wygeneruj na jego podstawie chronologię tej grafiki (w punktach)Efekt tego zabiegu można zobaczyć w udostępnionym materiale z ChatGPT (nie wymaga to logowania). Potwierdza się, że o ile ChatGPT wciąż ma problemy z kreatywnością, to bardzo dobrze radzi sobie z generowaniem streszczeń i podsumowań oraz wyciąganiem informacji z tekstu. Wrócimy do tego w kolejnych lekcjach.
Podsumowanie
ChatGPT jest efektywnym narzędziem do pracy z tekstami. W ramach ćwiczenia udało się nam przetworzyć zestaw metadanych w ciągły tekst opisu, uzupełnić go o autorski opis merytoryczny oraz potestować różne formy prezentacji całości (lista, opowiadanie, informacja prasowa, chronologia). Dużym ułatwieniem w pracy z tekstami w ChatGPT jest stosowanie tabel, ułatwiających kontrolę nad jakością danych oraz ich przetwarzanie.
Wykorzystanie metod
ChatGPT pomaga rozwiązać podstawowe problemy w przetwarzaniu tekstu, jednak dla bardziej skomplikowanych zadań związanych z przetwarzaniem języka polskiego warto korzystać z zaawansowanych narzędzi udostępnionych przez konsorcjum naukowe CLARIN-PL.
Pomysł na warsztat
Zaproś uczestników warsztatu do wyboru obiektów z muzeum cyfrowego. Zwróćcie uwagę na postać metadanych i informacje, jakie przekazują. Po skopiowaniu ich do ChatGPT, przygotujcie tabelę i wygenerujcie w niej nową kolumnę, której treścią będzie sparafrazowana wartość metadanych. Na podstawie tej kolumny przygotujcie tekst opisu, który następnie przetwarzajcie do wybranej postaci (opowiadania, informacji prasowej, piosenki itp.).


